旅行商问题(TSP)是计算机算法中经典的NP
hard 问题。 在本系列文章中,我们将首先使用动态规划 AC
aizu中的TSP问题,然后再利用深度学习求大规模下的近似解。深度学习应用解决问题时先以PyTorch实现监督学习算法
Pointer Network,进而结合强化学习来无监督学习,提高数据使用效率。
本系列完整列表如下:
TSP可以用图模型来表达,无论有向图或无向图,无论全连通图或者部分连通的图都可以作为TSP问题。
Wikipedia
TSP
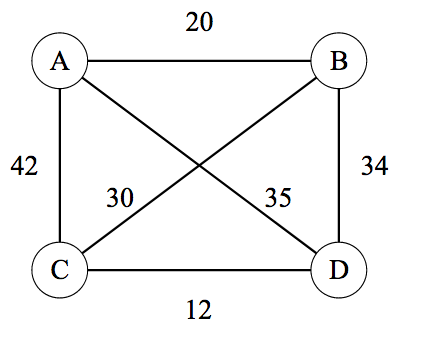
中举了一个无向全连通的TSP例子。如下图所示,四个顶点A,B,C,D构成无向全连通图。TSP问题要求在所有遍历所有点后返回初始点的回路中找到最短的回路。例如,\(A \rightarrow B \rightarrow C \rightarrow D
\rightarrow A\) 和 \(A \rightarrow C
\rightarrow B \rightarrow D \rightarrow A\)
都是有效的回路,但是TSP需要返回这些回路中的最短回路(注意,最短回路可能会有多条)。
publicGraph(int V_NUM){ this.V_NUM = V_NUM; this.edges = newint[V_NUM][V_NUM]; for (int i = 0; i < V_NUM; i++) { Arrays.fill(this.edges[i], Integer.MAX_VALUE); } } publicvoidsetDist(int src, int dest, int dist){ this.edges[src][dest] = dist; } } publicstaticclassTSP{ publicfinal Graph g; long[][] dp; publicTSP(Graph g){ this.g = g; } publiclongsolve(){ int N = g.V_NUM; dp = newlong[1 << N][N]; for (int i = 0; i < dp.length; i++) { Arrays.fill(dp[i], -1); } long ret = recurse(0, 0); return ret == Integer.MAX_VALUE ? -1 : ret; } privatelongrecurse(int state, int v){ int ALL = (1 << g.V_NUM) - 1; if (dp[state][v] >= 0) { return dp[state][v]; } if (state == ALL && v == 0) { dp[state][v] = 0; return0; } long res = Integer.MAX_VALUE; for (int u = 0; u < g.V_NUM; u++) { if ((state & (1 << u)) == 0) { long s = recurse(state | 1 << u, u); res = Math.min(res, s + g.edges[v][u]); } } dp[state][v] = res; return res; } } publicstaticvoidmain(String[] args){ Scanner in = new Scanner(System.in); int V = in.nextInt(); int E = in.nextInt(); Graph g = new Graph(V); while (E > 0) { int src = in.nextInt(); int dest = in.nextInt(); int dist = in.nextInt(); g.setDist(src, dest, dist); E--; } System.out.println(new TSP(g).solve()); } }
def__init__(self, v_num: int): self.v_num = v_num self.edges = [[INT_INF for c inrange(v_num)] for r inrange(v_num)] defsetDist(self, src: int, dest: int, dist: int): self.edges[src][dest] = dist
classTSPSolver: g: Graph dp: List[List[int]]
def__init__(self, g: Graph): self.g = g self.dp = [[Nonefor c inrange(g.v_num)] for r inrange(1 << g.v_num)] defsolve(self) -> int: return self._recurse(0, 0) def_recurse(self, v: int, state: int) -> int: """ :param v: :param state: :return: -1 means INF """ dp = self.dp edges = self.g.edges if dp[state][v] isnotNone: return dp[state][v] if (state == (1 << self.g.v_num) - 1) and (v == 0): dp[state][v] = 0 return dp[state][v] ret: int = INT_INF for u inrange(self.g.v_num): if (state & (1 << u)) == 0: s: int = self._recurse(u, state | 1 << u) if s != INT_INF and edges[v][u] != INT_INF: if ret == INT_INF: ret = s + edges[v][u] else: ret = min(ret, s + edges[v][u]) dp[state][v] = ret return ret
defsimulate_bruteforce(n: int) -> bool: """ Simulates one round. Unbounded time complexity. :param n: total number of seats :return: True if last one has last seat, otherwise False """
seats = [Falsefor _ inrange(n)]
for i inrange(n-1): if i == 0: # first one, always random seats[random.randint(0, n - 1)] = True else: ifnot seats[i]: # i-th has his seat seats[i] = True else: whileTrue: rnd = random.randint(0, n - 1) # random until no conflicts ifnot seats[rnd]: seats[rnd] = True break returnnot seats[n-1]
defsimulate_online(n: int) -> bool: """ Simulates one round of complexity O(N). :param n: total number of seats :return: True if last one has last seat, otherwise False """
# for each person, the seats array idx available are [i, n-1] for i inrange(n-1): if i == 0: # first one, always random rnd = random.randint(0, n - 1) swap(rnd, 0) else: if seats[i] == i: # i-th still has his seat pass else: rnd = random.randint(i, n - 1) # selects idx from [i, n-1] swap(rnd, i) return seats[n-1] == n - 1
递推思维
这一节我们用数学递推思维来解释0.5的解。令f(n) 为第 n
位乘客坐在自己的座位上的概率,考察第一个人的情况(first step
analysis),有三种可能
这种思想可以写出如下代码,seats为 n 大小的bool
数组,当第i个人(0<i<n)发现自己座位被占的话,此时必然seats[0]没有被占,同时seats[i+1:]都是空的。假设seats[0]被占的话,要么是第一个人占的,要么是第p个人(p<i)坐了,两种情况下乱序都已经恢复了,此时第i个座位一定是空的。
defsimulate(n: int) -> bool: """ Simulates one round of complexity O(N). :param n: total number of seats :return: True if last one has last seat, otherwise False """
seats = [Falsefor _ inrange(n)]
for i inrange(n-1): if i == 0: # first one, always random rnd = random.randint(0, n - 1) seats[rnd] = True else: ifnot seats[i]: # i-th still has his seat seats[i] = True else: # 0 must not be available, now we have 0 and [i+1, n-1], rnd = random.randint(i, n - 1) if rnd == i: seats[0] = True else: seats[rnd] = True returnnot seats[n-1]
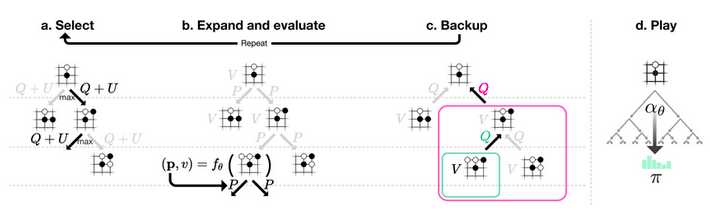
上一篇中,我们知道AlphaGo Zero 的MCTS树搜索是基于传统MCTS 的UCT (UCB
for Tree)的改进版PUCT(Polynomial Upper Confidence
Trees)。局面节点的PUCT值由两部分组成,分别是代表Exploitation的action
value Q值,和代表Exploration的U值。 \[
PUCT(s, a) =Q(s,a) + U(s,a)
\] U值计算由这些参数决定:系数\(c_{puct}\),节点先验概率P(s, a)
,父节点访问次数,本节点的访问次数。具体公式如下 \[
U(s, a)=c_{p u c t} \cdot P(s, a) \cdot \frac{\sqrt{\Sigma_{b} N(s,
b)}}{1+N(s, a)}
\]
_parent: TreeNode _children: Dict[int, TreeNode] # map from action to TreeNode _visit_num: int _Q: float# Q value of the node, which is the mean action value. _prior: float
和上面的计算公式相对应,下列代码根据节点状态计算PUCT(s, a)。
{linenos
1 2 3 4 5 6 7 8 9 10
classTreeNode:
defget_puct(self) -> float: """ Computes AlphaGo Zero PUCT (polynomial upper confidence trees) of the node. :return: Node PUCT value. """ U = (TreeNode.c_puct * self._prior * np.sqrt(self._parent._visit_num) / (1 + self._visit_num)) return self._Q + U
AlphaGo Zero
MCTS在playout时遇到已经被展开的节点,会根据selection规则选择子节点,该规则本质上是在所有子节点中选择最大的PUCT值的节点。
defpropagate_to_root(self, leaf_value: float): """ Updates current node with observed leaf_value and propagates to root node. :param leaf_value: :return: """ if self._parent: self._parent.propagate_to_root(-leaf_value) self._update(leaf_value)
def_update(self, leaf_value: float): """ Updates the node by newly observed leaf_value. :param leaf_value: :return: """ self._visit_num += 1 # new Q is updated towards deviation from existing Q self._Q += 0.5 * (leaf_value - self._Q)
AlphaGo Zero MCTS Player
实现
AlphaGo Zero MCTS
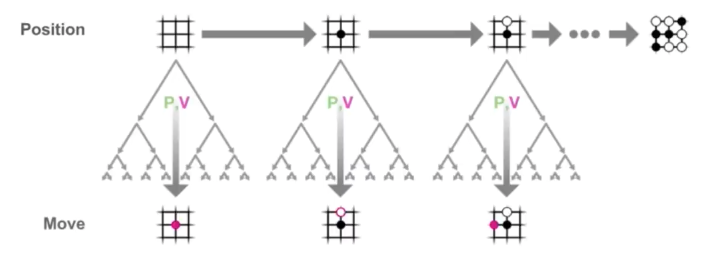
在训练阶段分为如下几个步骤。游戏初始局面下,整个局面树的建立由子节点的不断被探索而丰富起来。AlphaGo
Zero对弈一次即产生了一次完整的游戏开始到结束的动作系列。在对弈过程中的某一游戏局面,需要采样海量的playout,又称MCTS模拟,以此来决定此局面的下一步动作。一次playout可视为在真实游戏状态树的一种特定采样,playout可能会产生游戏结局,生成真实的v值;也可能explore
到新的叶子节点,此时v值依赖策略价值网络的输出,目的是利用训练的神经网络来产生高质量的游戏对战局面。每次playout会从当前给定局面递归向下,向下的过程中会遇到下面三种节点情况。
def_next_step_play_act_probs(self, game: ConnectNGame) -> Tuple[List[Pos], ActionProbs]: """ For the given game status, run playouts number of times specified by self._playout_num. Returns the action distribution according to AlphaGo Zero MCTS play formula. :param game: :return: actions and their probability """
for n inrange(self._playout_num): self._playout(copy.deepcopy(game))
defget_action(self, board: PyGameBoard) -> Pos: """ Method defined in BaseAgent. :param board: :return: next move for the given game board. """ return self._get_action(copy.deepcopy(board.connect_n_game))[0]
# the pi defined in AlphaGo Zero paper acts, act_probs = self._next_step_play_act_probs(game) move_probs[list(acts)] = act_probs if self._is_training: # add Dirichlet Noise when training in favour of exploration p_ = (1-epsilon) * act_probs + epsilon * np.random.dirichlet(0.3 * np.ones(len(act_probs))) move = np.random.choice(acts, p=p_) assert move in game.get_avail_pos() else: move = np.random.choice(acts, p=act_probs)
defself_play_one_game(self, game: ConnectNGame) \ -> List[Tuple[NetGameState, ActionProbs, NDArray[(Any), np.float]]]: """ :param game: :return: Sequence of (s, pi, z) of a complete game play. The number of list is the game play length. """
classMCTSAlphaGoZeroPlayer(BaseAgent): def_playout(self, game: ConnectNGame): """ From current game status, run a sequence down to a leaf node, either because game ends or unexplored node. Get the leaf value of the leaf node, either the actual reward of game or action value returned by policy net. And propagate upwards to root node. :param game: """ player_id = game.current_player
# now game state is a leaf node in the tree, either a terminal node or an unexplored node act_and_probs: Iterator[MoveWithProb] act_and_probs, leaf_value = self._policy_value_net.policy_value_fn(game)
ifnot game.game_over: # case where encountering an unexplored leaf node, update leaf_value estimated by policy net to root for act, prob in act_and_probs: game.move(act) child_node = node.expand(act, prob) game.undo() else: # case where game ends, update actual leaf_value to root if game.game_result == ConnectNGame.RESULT_TIE: leaf_value = ConnectNGame.RESULT_TIE else: leaf_value = 1if game.game_result == player_id else -1 leaf_value = float(leaf_value)
# Update leaf_value and propagate up to root node node.propagate_to_root(-leaf_value)
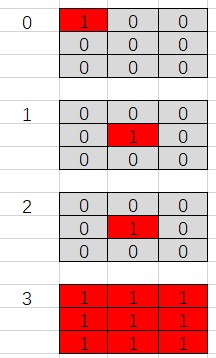
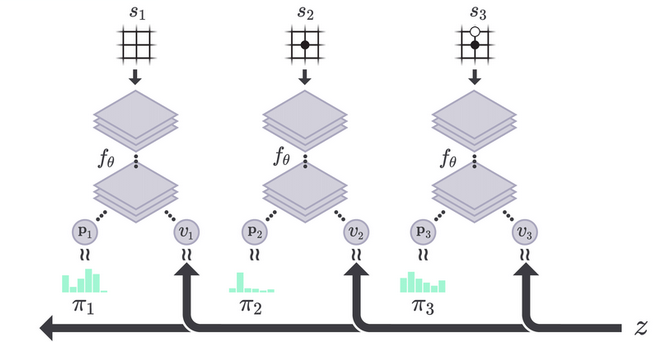
defconvert_game_state(game: ConnectNGame) -> NetGameState: """ Converts game state to type NetGameState as ndarray. :param game: :return: Of shape 4 * board_size * board_size. [0] is current player positions. [1] is opponent positions. [2] is last move location. [3] all 1 meaning move by black player, all 0 meaning move by white. """ state_matrix = np.zeros((4, game.board_size, game.board_size))
if game.action_stack: actions = np.array(game.action_stack) move_curr = actions[::2] move_oppo = actions[1::2] for move in move_curr: state_matrix[0][move] = 1.0 for move in move_oppo: state_matrix[1][move] = 1.0 # indicate the last move location state_matrix[2][actions[-1]] = 1.0 iflen(game.action_stack) % 2 == 0: state_matrix[3][:, :] = 1.0# indicate the colour to play return state_matrix[:, ::-1, :]
AlphaGo Zero 作为Deepmind在围棋领域的最后一代AI
Agent,已经可以达到棋类游戏的终极目标:在只给定游戏规则的情况下,AI
棋手从最初始的随机状态开始,通过不断的自我对弈的强化学习来实现超越以往任何人类棋手和上一代Alpha的能力,并且同样的算法和模型应用到了其他棋类也得出相同的效果。这一篇,从原理上来解析AlphaGo
Zero的运行方式。
AlphaGo Zero
算法由三种元素构成:强化学习(RL)、深度学习(DL)和蒙特卡洛树搜索(MCTS,Monte
Carlo Tree Search)。核心思想是基于神经网络的Policy
Iteration强化学习,即最终学的是一个深度学习的policy
network,输入是某棋盘局面 s,输出是此局面下可走位的概率分布:\(p(a|s)\)。
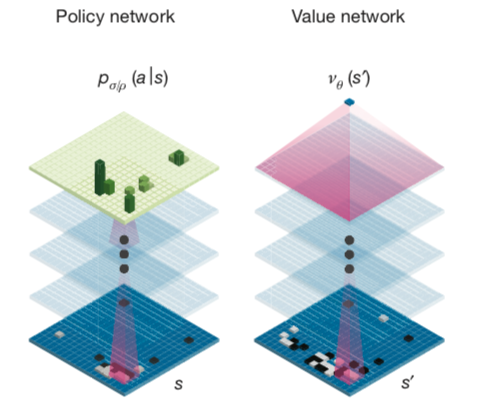
在第一代AlphaGo算法中,这个初始policy
network通过收集专业人类棋手的海量棋局训练得来,再采用传统RL 的Monte
Carlo Tree Search Rollout 技术来强化现有的AI对于局面落子(Policy
Network)的判断。Monte Carlo Tree Search Rollout
简单说来就是海量棋局模拟,AI Agent在通过现有的Policy
Network策略完成一次从某局面节点到最终游戏胜负结束的对弈,这个完整的对弈叫做rollout,又称playout。完成一次rollout之后,通过局面树层层回溯到初始局面节点,并在回溯过程中同步修订所有经过的局面节点的统计指标,修正原先policy
network对于落子导致输赢的判断。通过海量并发的棋局模拟来提升基准policy
network,即在各种局面下提高好的落子的\(p(a_{win}|s)\),降低坏的落子的\(p(a_{lose}|s)\)
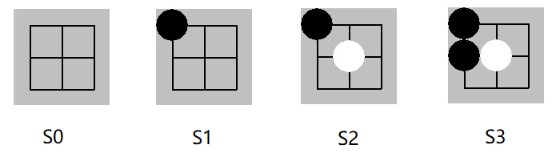
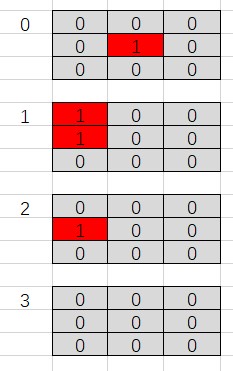
举例如下井字棋局面:
局面s
基准policy network返回 p(s) 如下 \[
p(a|s) =
\begin{align*}
\left\lbrace
\begin{array}{r@{}l}
0.1, & & a = (0,2) \\
0.05, & & a = (1,0) \\
0.5, & & a = (1,1) \\
0.05, & & a = (1,2)\\
0.2, & & a = (2,0) \\
0.05, & & a = (2,1) \\
0.05, & & a = (2,2)
\end{array}
\right.
\end{align*}
\] 通过海量并发模拟后,修订成如下的action概率分布,然后通过policy
iteration迭代新的网络来逼近 \(p'\)
就提高了棋力。 \[
p'(a|s) =
\begin{align*}
\left\lbrace
\begin{array}{r@{}l}
0, & & a = (0,2) \\
0, & & a = (1,0) \\
0.9, & & a = (1,1) \\
0, & & a = (1,2)\\
0, & & a = (2,0) \\
0, & & a = (2,1) \\
0.1, & & a = (2,2)
\end{array}
\right.
\end{align*}
\]
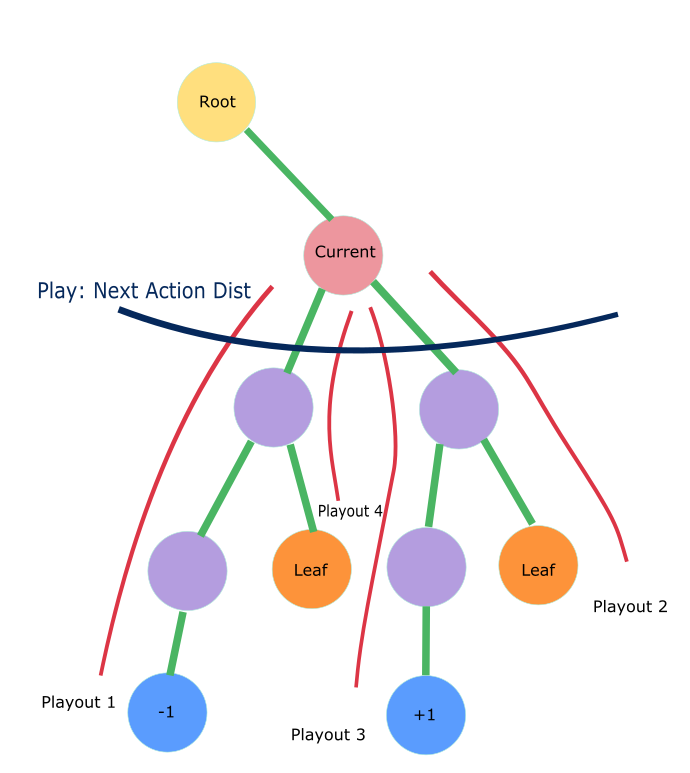
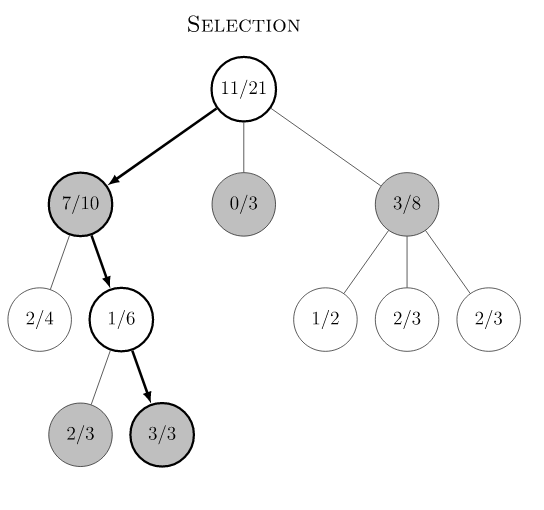
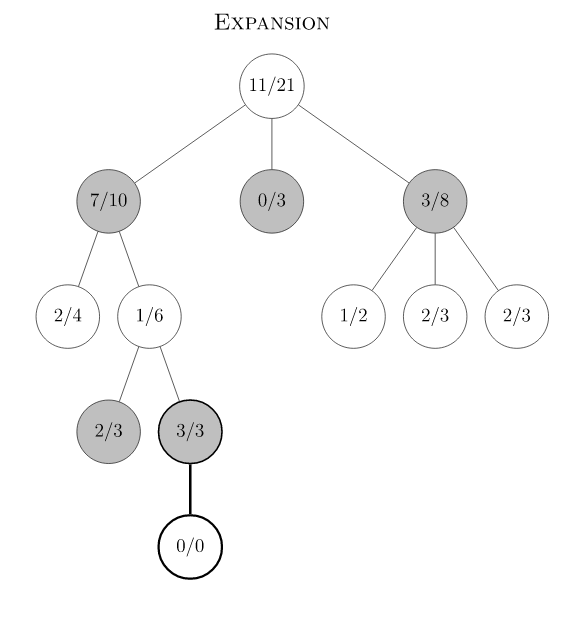
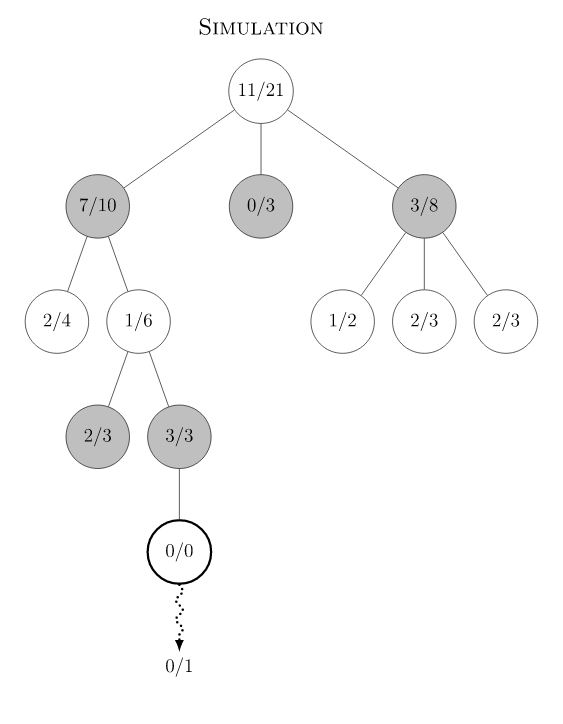
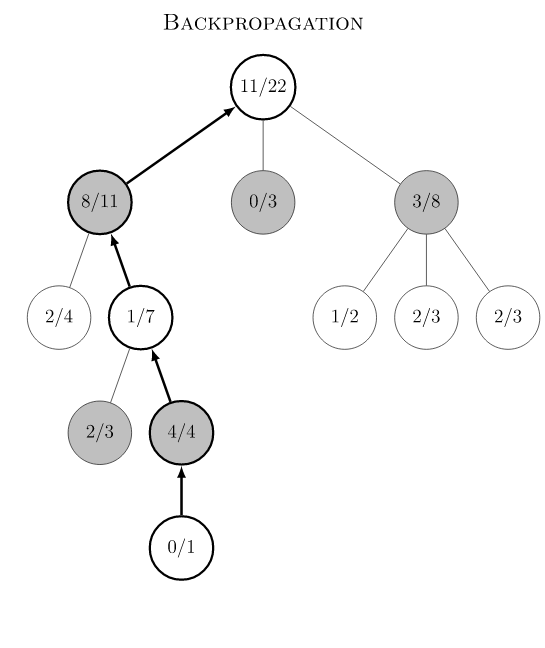
蒙特卡洛树搜索(MCTS)概述
Monte Carlo Tree Search 是Monte Carlo
在棋类游戏中的变种,棋类游戏的一大特点是可以用动作(move)联系的决策树来表示,树的节点数量取决于分支的数量和树的深度。MCTS的目的是在树节点非常多的情况下,通过实验模拟(rollout,
playout)的方式来收集尽可能多的局面输赢情况,并基于这些统计信息,将搜索资源的重点均衡地放在未被探索的节点和值得探索的节点上,减少在大概率输的节点上的模拟资源投入。传统MCTS有四个过程:Selection,
Expansion, Simulation 和Backpropagation。下图是Wikipedia
的例子:
前一代的AlphaGo已经战胜了世界冠军,取得了空前的成就,AlphaGo Zero
的设计目标变得更加General,去除围棋相关的处理和知识,用统一的框架和算法来解决棋类问题。
1. 无人工先验数据
改进之前需要专家棋手对弈数据来冷启动初始棋力
无特定游戏特征工程
无需围棋特定技巧,只包含下棋规则,可以适用到所有棋类游戏
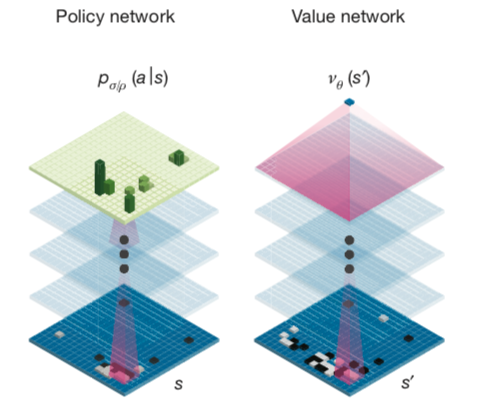
单一神经网络
统一Policy Network和Value
Network,使用一个共享参数的双头神经网络
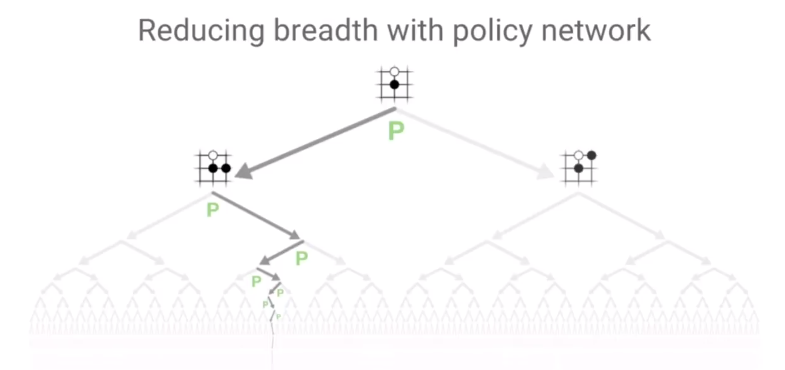
简单树搜索
去除传统MCTS的Rollout
方式,用神经网络来指导MCTS更有效产生搜索策略
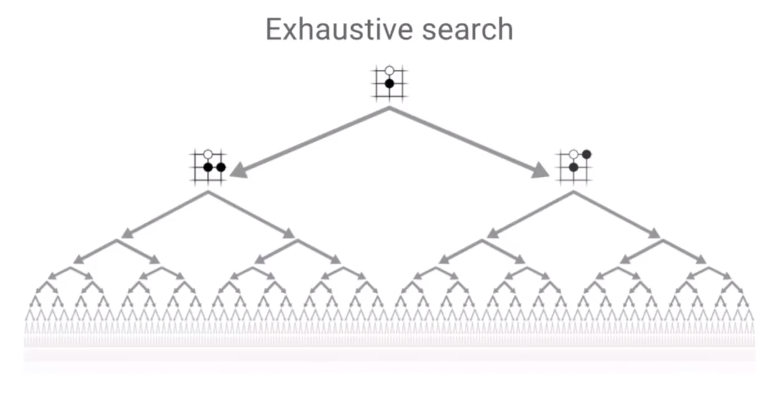
搜索空间的两个优化原则
尽管理论上围棋是有解的,即先手必赢、被逼平或必输,通过遍历所有可能局面可以求得解。同理,通过海量模拟所有可能游戏局面,也可以无限逼近所有局面下的真实输赢概率,直至收敛于局面落子的确切最佳结果。但由于围棋棋局的数目远远大于宇宙原子数目,3^361
>>
10^80,因此需要将计算资源有效的去模拟值得探索的局面,例如对于显然的被动局面减小模拟次数,所以如何有效地减小搜索空间是AlphaGo
Zero 需要解决的重大问题。David Silver 在Deepmind
AlphaZero - Mastering Games Without Human Knowledge中提到AlphaGo
Zero 采用两个原则来有效减小搜索空间。
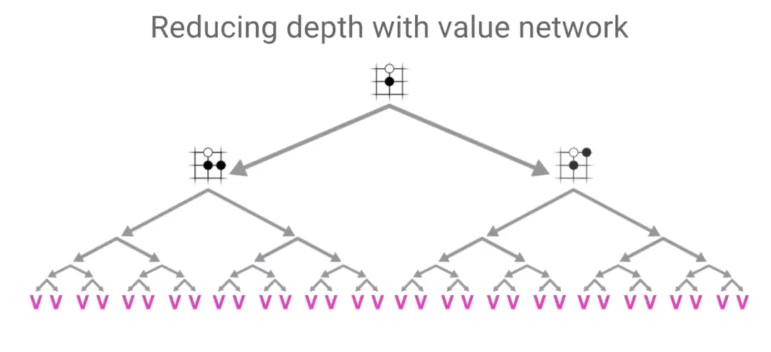
原则1: 通过Value
Network减少搜索的深度
Value Network
通过预测给定局面的value来直接预测最终结果,思想和上一期Minimax DP
策略中直接缓存当前局面的胜负状态一样,减少每次必须靠模拟到最后才能知道当前局面的输赢概率,或者需要多层树搜索才能知道输赢概率。
defreset(self) -> ConnectNGame: """Resets the state of the environment and returns an initial observation. Returns: observation (object): the initial observation. """ raise NotImplementedError
defstep(self, action: Tuple[int, int]) -> Tuple[ConnectNGame, int, bool, None]: """Run one timestep of the environment's dynamics. When end of episode is reached, you are responsible for calling `reset()` to reset this environment's state. Accepts an action and returns a tuple (observation, reward, done, info). Args: action (object): an action provided by the agent Returns: observation (object): agent's observation of the current environment reward (float) : amount of reward returned after previous action done (bool): whether the episode has ended, in which case further step() calls will return undefined results info (dict): contains auxiliary diagnostic information (helpful for debugging, and sometimes learning) """ raise NotImplementedError
defrender(self, mode='human'): """ Renders the environment. The set of supported modes varies per environment. (And some environments do not support rendering at all.) By convention, if mode is: - human: render to the current display or terminal and return nothing. Usually for human consumption. - rgb_array: Return an numpy.ndarray with shape (x, y, 3), representing RGB values for an x-by-y pixel image, suitable for turning into a video. - ansi: Return a string (str) or StringIO.StringIO containing a terminal-style text representation. The text can include newlines and ANSI escape sequences (e.g. for colors). Note: Make sure that your class's metadata 'render.modes' key includes the list of supported modes. It's recommended to call super() in implementations to use the functionality of this method. Args: mode (str): the mode to render with """ raise NotImplementedError
defaction(self, game: ConnectNGame) -> Tuple[int, Tuple[int, int]]: game = copy.deepcopy(game)
player = game.currentPlayer bestResult = player * -1# assume opponent win as worst result bestMove = None for move in game.getAvailablePositions(): game.move(*move) status = game.getStatus() game.undo()
result = self.dpMap[status]
if player == ConnectNGame.PLAYER_A: bestResult = max(bestResult, result) else: bestResult = min(bestResult, result) # update bestMove if any improvement bestMove = move if bestResult == result else bestMove print(f'move {move} => {result}')
classSolution: deftictactoe(self, moves: List[List[int]]) -> str: board = [[0] * 3for _ inrange(3)] for idx, xy inenumerate(moves): player = 1if idx % 2 == 0else -1 board[xy[0]][xy[1]] = player
turn = 0 row, col = [0, 0, 0], [0, 0, 0] diag1, diag2 = False, False for r inrange(3): for c inrange(3): turn += board[r][c] row[r] += board[r][c] col[c] += board[r][c] if r == c: diag1 += board[r][c] if r + c == 2: diag2 += board[r][c]
oWin = any(row[r] == 3for r inrange(3)) orany(col[c] == 3for c inrange(3)) or diag1 == 3or diag2 == 3 xWin = any(row[r] == -3for r inrange(3)) orany(col[c] == -3for c inrange(3)) or diag1 == -3or diag2 == -3
if (north + south + 1 >= 3) or (east + west + 1 >= 3) or \ (south_east + north_west + 1 >= 3) or (north_east + south_west + 1 >= 3): returnTrue returnFalse
defgetConnectedNum(self, r: int, c: int, dr: int, dc: int) -> int: player = self.board[r][c] result = 0 i = 1 whileTrue: new_r = r + dr * i new_c = c + dc * i if0 <= new_r < 3and0 <= new_c < 3: if self.board[new_r][new_c] == player: result += 1 else: break else: break i += 1 return result
deftictactoe(self, moves: List[List[int]]) -> str: self.board = [[0] * 3for _ inrange(3)] for idx, xy inenumerate(moves): player = 1if idx % 2 == 0else -1 self.board[xy[0]][xy[1]] = player
# only check last move r, c = moves[-1] win = self.checkWin(r, c) if win: return"A"iflen(moves) % 2 == 1else"B"
def__init__(self, n:int): """ Initialize your data structure here. :type n: int """ self.row, self.col, self.diag1, self.diag2, self.n = [0] * n, [0] * n, 0, 0, n
defmove(self, row:int, col:int, player:int) -> int: """ Player {player} makes a move at ({row}, {col}). @param row The row of the board. @param col The column of the board. @param player The player, can be either 1 or 2. @return The current winning condition, can be either: 0: No one wins. 1: Player 1 wins. 2: Player 2 wins. """ if player == 2: player = -1
self.row[row] += player self.col[col] += player if row == col: self.diag1 += player if row + col == self.n - 1: self.diag2 += player
if self.n in [self.row[row], self.col[col], self.diag1, self.diag2]: return1 if -self.n in [self.row[row], self.col[col], self.diag1, self.diag2]: return2 return0
井字棋最佳策略
井字棋的规模可以很自然的扩展成四子棋或五子棋等,区别在于棋盘大小和胜利时的连子数量。这类游戏最一般的形式为
M,n,k-game,中文可能翻译为战略井字游戏,表示棋盘大小为M
x N,当k连子时获胜。
下面的ConnectNGame类实现了战略井字游戏(M=N)中,两个玩家轮流下子、更新棋盘状态和判断每次落子输赢等逻辑封装。其中undo方法用于撤销最后一个落子,方便在后续寻找最佳策略时回溯。
defgetAvailablePositions(self) -> List[Tuple[int, int]]: return [(i,j) for i inrange(self.board_size) for j inrange(self.board_size) if self.board[i][j] == ConnectNGame.AVAILABLE]
defgetStatus(self) -> Tuple[Tuple[int, ...]]: returntuple([tuple(self.board[i]) for i inrange(self.board_size)])
defminimax(self) -> Tuple[int, Tuple[int, int]]: game = self.game bestMove = None assertnot game.gameOver if game.currentPlayer == ConnectNGame.PLAYER_A: ret = -math.inf for pos in game.getAvailablePositions(): move = pos result = game.move(*pos) if result isNone: assertnot game.gameOver result, oppMove = self.minimax() game.undo() ret = max(ret, result) bestMove = move if ret == result else bestMove if ret == 1: return1, move return ret, bestMove else: ret = math.inf for pos in game.getAvailablePositions(): move = pos result = game.move(*pos) if result isNone: assertnot game.gameOver result, oppMove = self.minimax() game.undo() ret = min(ret, result) bestMove = move if ret == result else bestMove if ret == -1: return -1, move return ret, bestMove
if gameStatus in self.dpMap: return self.dpMap[gameStatus]
game = self.game bestMove = None assertnot game.gameOver if game.currentPlayer == ConnectNGame.PLAYER_A: ret = -math.inf for pos in game.getAvailablePositions(): move = pos result = game.move(*pos) if result isNone: assertnot game.gameOver result, oppMove = self.minimax(game.getStatus()) self.dpMap[game.getStatus()] = result, oppMove else: self.dpMap[game.getStatus()] = result, move game.undo() ret = max(ret, result) bestMove = move if ret == result else bestMove self.dpMap[gameStatus] = ret, bestMove return ret, bestMove else: ret = math.inf for pos in game.getAvailablePositions(): move = pos result = game.move(*pos)
if result isNone: assertnot game.gameOver result, oppMove = self.minimax(game.getStatus()) self.dpMap[game.getStatus()] = result, oppMove else: self.dpMap[game.getStatus()] = result, move game.undo() ret = min(ret, result) bestMove = move if ret == result else bestMove self.dpMap[gameStatus] = ret, bestMove return ret, bestMove
if __name__ == '__main__': tic_tac_toe = ConnectNGame(N=3, board_size=3) strategy = CountingMinimaxStrategy() strategy.action(tic_tac_toe) print(f'Game States Number {len(strategy.dpMap)}')
defalpha_beta(self, gameStatus: Tuple[Tuple[int, ...]], alpha:int=None, beta:int=None) -> Tuple[int, Tuple[int, int]]: game = self.game bestMove = None assertnot game.gameOver if game.currentPlayer == ConnectNGame.PLAYER_A: ret = -math.inf for pos in game.getAvailablePositions(): move = pos result = game.move(*pos) if result isNone: assertnot game.gameOver result, oppMove = self.alpha_beta(game.getStatus(), alpha, beta) game.undo() alpha = max(alpha, result) ret = max(ret, result) bestMove = move if ret == result else bestMove if alpha >= beta or ret == 1: return ret, move return ret, bestMove else: ret = math.inf for pos in game.getAvailablePositions(): move = pos result = game.move(*pos) if result isNone: assertnot game.gameOver result, oppMove = self.alpha_beta(game.getStatus(), alpha, beta) game.undo() beta = min(beta, result) ret = min(ret, result) bestMove = move if ret == result else bestMove if alpha >= beta or ret == -1: return ret, move return ret, bestMove
@lru_cache(maxsize=None) defalpha_beta_dp(self, gameStatus: Tuple[Tuple[int, ...]]) -> Tuple[int, Tuple[int, int]]: alpha, beta = self.alphaBetaStack[-1] game = self.game bestMove = None assertnot game.gameOver if game.currentPlayer == ConnectNGame.PLAYER_A: ret = -math.inf for pos in game.getAvailablePositions(): move = pos result = game.move(*pos) if result isNone: assertnot game.gameOver self.alphaBetaStack.append((alpha, beta)) result, oppMove = self.alpha_beta_dp(game.getStatus()) self.alphaBetaStack.pop() game.undo() alpha = max(alpha, result) ret = max(ret, result) bestMove = move if ret == result else bestMove if alpha >= beta or ret == 1: return ret, move return ret, bestMove else: ret = math.inf for pos in game.getAvailablePositions(): move = pos result = game.move(*pos) if result isNone: assertnot game.gameOver self.alphaBetaStack.append((alpha, beta)) result, oppMove = self.alpha_beta_dp(game.getStatus()) self.alphaBetaStack.pop() game.undo() beta = min(beta, result) ret = min(ret, result) bestMove = move if ret == result else bestMove if alpha >= beta or ret == -1: return ret, move return ret, bestMove
# TLE # Time Complexity: O(exponential) classSolution_BruteForce:
defcanWinNim(self, n: int) -> bool: if n <= 3: returnTrue for i inrange(1, 4): ifnot self.canWinNim(n - i): returnTrue returnFalse
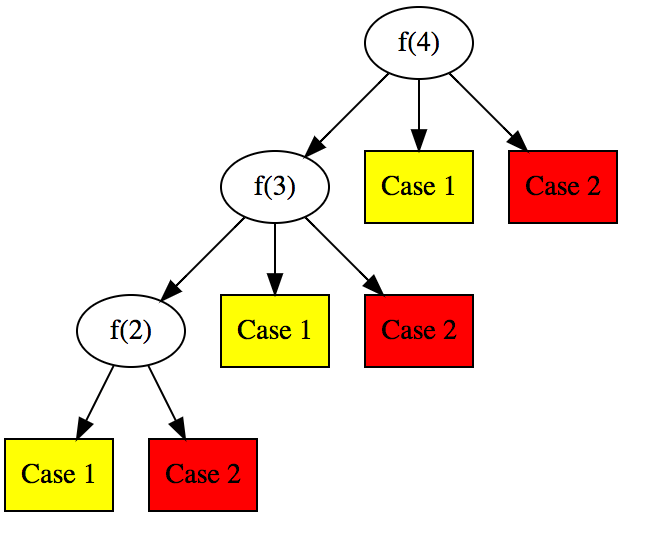
以上的递归公式和代码很像fibonacci数的递归定义和暴力解法,因此对应的时间复杂度也是指数级的,提交代码以后会TLE。下图画出了当n=7时的递归调用,注意
5 被扩展向下重复执行了两次,4重复了4次。
292 Nim Game 暴力解法调用图 n=7
我们采用和fibonacci一样的方式来优化算法:缓存较小n的结果以此来计算较大n的结果。
Python 中,我们可以只加一行lru_cache
decorator,来取得这种动态规划效果,下面的代码将复杂度降到了 \(O(N)\)。
{linenos
1 2 3 4 5 6 7 8 9 10 11 12
# RecursionError: maximum recursion depth exceeded in comparison n=1348820612 # Time Complexity: O(N) classSolution_DP: from functools import lru_cache @lru_cache(maxsize=None) defcanWinNim(self, n: int) -> bool: if n <= 3: returnTrue for i inrange(1, 4): ifnot self.canWinNim(n - i): returnTrue returnFalse
再来画出调用图:这次5和4就不再被展开重复计算,图中绿色的节点表示缓存命中。
292 Nim Game 动归解法调用图 n=7
# TLE for 1348820612 # Time Complexity: O(N) classSolution: defcanWinNim(self, n: int) -> bool: if n <= 3: returnTrue last3, last2, last1 = True, True, True for i inrange(4, n+1): this = not (last3 and last2 and last1) last3, last2, last1 = last2, last1, this return last1
defminimax(node: Node, depth: int, maximizingPlayer: bool) -> int: if depth == 0or is_terminal(node): return evaluate_terminal(node) if maximizingPlayer: value:int = −∞ for child in node: value = max(value, minimax(child, depth − 1, False)) return value else: # minimizing player value := +∞ for child in node: value = min(value, minimax(child, depth − 1, True)) return value
# AC classSolution: from functools import lru_cache @lru_cache(maxsize=None) # currentTotal < desiredTotal defminimax(self, status: int, currentTotal: int, isMaxPlayer: bool) -> int: import math if status == self.allUsed: return0# draw: no winner
if isMaxPlayer: value = -math.inf for i inrange(1, self.maxChoosableInteger + 1): ifnot (status >> i & 1): new_status = 1 << i | status if currentTotal + i >= self.desiredTotal: return1# shortcut value = max(value, self.minimax(new_status, currentTotal + i, not isMaxPlayer)) if value == 1: return1 return value else: value = math.inf for i inrange(1, self.maxChoosableInteger + 1): ifnot (status >> i & 1): new_status = 1 << i | status if currentTotal + i >= self.desiredTotal: return -1# shortcut value = min(value, self.minimax(new_status, currentTotal + i, not isMaxPlayer)) if value == -1: return -1 return value
# AC classSolution: from functools import lru_cache @lru_cache(maxsize=None) # currentTotal < desiredTotal defalpha_beta(self, status: int, currentTotal: int, isMaxPlayer: bool, alpha: int, beta: int) -> int: import math if status == self.allUsed: return0# draw: no winner
if isMaxPlayer: value = -math.inf for i inrange(1, self.maxChoosableInteger + 1): ifnot (status >> i & 1): new_status = 1 << i | status if currentTotal + i >= self.desiredTotal: return1# shortcut value = max(value, self.alpha_beta(new_status, currentTotal + i, not isMaxPlayer, alpha, beta)) alpha = max(alpha, value) if alpha >= beta: return value return value else: value = math.inf for i inrange(1, self.maxChoosableInteger + 1): ifnot (status >> i & 1): new_status = 1 << i | status if currentTotal + i >= self.desiredTotal: return -1# shortcut value = min(value, self.alpha_beta(new_status, currentTotal + i, not isMaxPlayer, alpha, beta)) beta = min(beta, value) if alpha >= beta: return value return value
// AC classSolution{ publicbooleanPredictTheWinner(int[] nums){ int n = nums.length; int[][] dp = newint[n][n]; for (int i = 0; i < n; i++) { dp[i][i] = nums[i]; }
for (int l = n - 1; l >= 0; l--) { for (int r = l + 1; r < n; r++) { dp[l][r] = Math.max( nums[l] - dp[l + 1][r], nums[r] - dp[l][r - 1]); } } return dp[0][n - 1] >= 0; } }
C++ AC Code
{linenos
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
// AC classSolution { public: boolPredictTheWinner(vector<int>& nums){ int n = nums.size(); vector<vector<int>> dp(n, vector<int>(n, 0)); for (int i = 0; i < n; i++) { dp[i][i] = nums[i]; } for (int l = n - 1; l >= 0; l--) { for (int r = l + 1; r < n; r++) { dp[l][r] = max(nums[l] - dp[l + 1][r], nums[r] - dp[l][r - 1]); } } return dp[0][n - 1] >= 0; } };
for (let i = 0; i < n; i++) { dp[i][i] = nums[i]; } for (let l = n - 1; l >=0; l--) { for (let r = i + 1; r < n; r++) { dp[l][r] = Math.max(nums[l] - dp[l + 1][r],nums[r] - dp[l][r - 1]); } } return dp[0][n-1] >=0; };





.png)
.png)