This is fifth episode of series: TSP From DP to Deep Learning. In this episode, we turn to Reinforcement Learning technology, in particular, a model-free policy gradient method that embeds pointer network to learn minimal tour without supervised best tour label in dataset. Full list of this series is listed below.
Episode 1: AC TSP on AIZU with recursive DP
Episode 2: TSP DP on a Euclidean Dataset
Episode 3: Pointer Networks in PyTorch
Episode 4: Search for Most Likely Sequence
Pointer Network Refresher
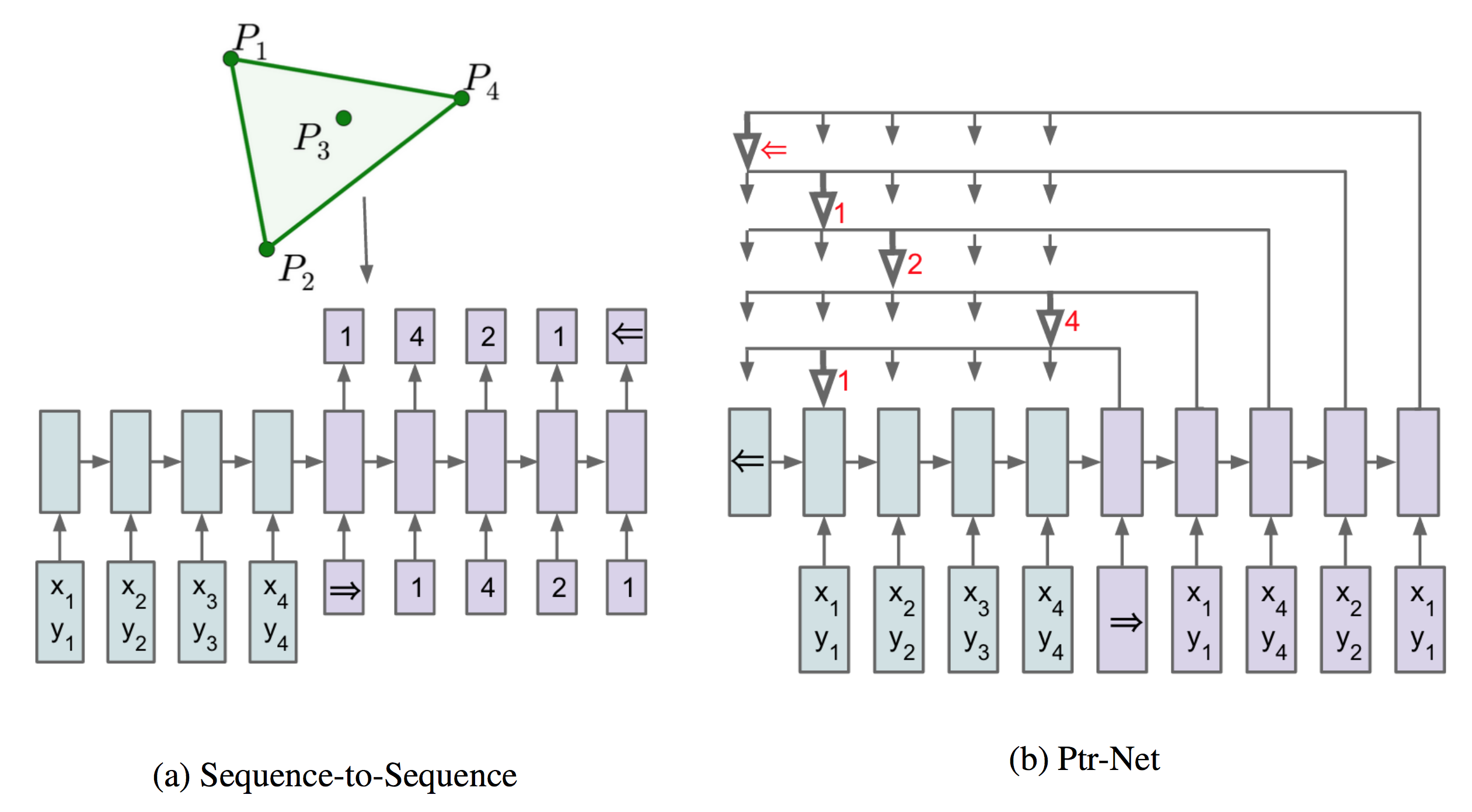
In previous episode Pointer Networks in PyTorch, we implemented Pointer Networks in PyTorch with a 2D Euclidean dataset.
Recall that the input is a graph as a sequence of \(n\) cities in a two dimensional space\[ s=\{\mathbf{x_i}\}_{i=1}^n, \mathbf{x}_{i} \in \mathbb{R}^{2} \]
The output is a permutation of the points \(\pi\), that visits each city exactly once and returns to starting point with minimal distance.
Let us define the total distance of a \(\pi\) with respect to \(s\) as \(L\)
\[ L(\pi | s)=\left\|\mathbf{x}_{\pi(n)}-\mathbf{x}_{\pi(1)}\right\|_{2}+\sum_{i=1}^{n-1}\left\|\mathbf{x}_{\pi(i)}-\mathbf{x}_{\pi(i+1)}\right\|_{2} \]
The stochastic policy \(p(\pi | s; \theta)\), parameterized by \(\theta\), is aiming to assign high probabilities to short tours and low probabilities to long tours. The joint probability assumes independency to allow factorization.
\[ p(\pi | s; \theta) = \prod_{i=1}^{n} p\left({\pi(i)} | {\pi(1)}, \ldots, {\pi(i-1)} , s; \theta\right) \]
The loss of the model is cross entropy between the network’s output probabilities \(\pi\) and the best tour \(\hat{\pi}\) generated by a TSP solver.
Contribution made by Pointer networks is that it addressed the constraint in that it allows for dynamic index value given by the particular test case, instead of from a fixed-size vocabulary.
Reinforcement Learning
Neural Combinatorial Optimization with Reinforcement Learning combines the power of Reinforcement Learning (RL) and Deep Learning to further eliminate the constraint required by Pointer Networks that the training dataset has to have supervised labels of best tour. With deep RL, test cases do not need to have a solution which is common pattern in deep RL. In the paper, a model-free policy-based RL method is adopted.
Model-Free Policy Gradient Methods
In the authoritative RL book, chapter 8 Planning and Learning with Tabular Methods, there are two major approaches in RL. One is model-based RL and the other is model-free RL. Distinction between the two relies on concept of model, which is stated as follows:
By a model of the environment we mean anything that an agent can use to predict how the environment will respond to its actions.
So model-based methods demand a model of the environment, and hence dynamic programming and heuristic search fall into this category. With model in mind, utility of the state can be computed in various ways and planning stage that essentially builds policy is needed before agent can take any action. In contrast, model-free methods, without building a model, are more direct, ignoring irrelevant information and just focusing on the policy which is ultimately needed. Typical examples of model-free methods are Monte Carlo Control and Temporal-Difference Learning. >Model-based methods rely on planning as their primary component, while model-free methods primarily rely on learning.
In TSP problem, the model is fully determined by all points given, and no feedback is generated for each decision made. So it's unclear to how to map state value with a tour. Therefore, we turn to model-free methods. In chapter 13 Policy Gradient Methods, a particular approximation model-free method that learns a parameterized policy that can select actions without consulting a value function. This approach fits perfectly with aforementioned pointer networks where the parameterized policy \(p(\pi | s; \theta)\) is already defined.
Training objective is obvious, the expected tour length of \(\pi_\theta\) which, given an input graph \(s\)\[ J(\theta | s) = \mathbb{E}_{\pi \sim p_{\theta}(\cdot | s)} L(\pi | s) \]
Monte Carlo Policy Gradient: REINFORCE with Baseline
In order to find largest reward, a typical way is to optimize the parameters \(\theta\) in the direction of derivative: \(\nabla_{\theta} J(\theta | s)\).
\[ \nabla_{\theta} J(\theta | s)=\nabla_{\theta} \mathbb{E}_{\pi \sim p_{\theta}(\cdot | s)} L(\pi | s) \]
RHS of equation above is the derivative of expectation that we have no idea how to compute or approximate. Here comes the well-known REINFORCE trick that turns it into form of expectation of derivative, which can be approximated easily with Monte Carlo sampling, where the expectation is replaced by averaging.
\[ \nabla_{\theta} J(\theta | s)=\mathbb{E}_{\pi \sim p_{\theta}(. | s)}\left[L(\pi | s) \nabla_{\theta} \log p_{\theta}(\pi | s)\right] \]
Another common trick, subtracting a baseline \(b(s)\), leads the derivative of reward to the following equation. Note that \(b(s)\) denotes a baseline function that must not depend on \(\pi\). \[ \nabla_{\theta} J(\theta | s)=\mathbb{E}_{\pi \sim p_{\theta}(. | s)}\left[(L(\pi | s)-b(s)) \nabla_{\theta} \log p_{\theta}(\pi | s)\right] \]
The trick is explained in as:
Because the baseline could be uniformly zero, this update is a strict generalization of REINFORCE. In general, the baseline leaves the expected value of the update unchanged, but it can have a large effect on its variance.
Finally, the equation can be approximated with Monte Carlo sampling, assuming drawing \(B\) i.i.d: \(s_{1}, s_{2}, \ldots, s_{B} \sim \mathcal{S}\) and sampling a single tour per graph: $ {i} p{}(. | s_{i}) $, as follows \[ \nabla_{\theta} J(\theta) \approx \frac{1}{B} \sum_{i=1}^{B}\left(L\left(\pi_{i} | s_{i}\right)-b\left(s_{i}\right)\right) \nabla_{\theta} \log p_{\theta}\left(\pi_{i} | s_{i}\right) \]
Actor Critic Methods
REINFORCE with baseline works quite well but it also has disadvantage.
REINFORCE with baseline is unbiased and will converge asymptotically to a local minimum, but like all Monte Carlo methods it tends to learn slowly (produce estimates of high variance) and to be inconvenient to implement online or for continuing problems.
A typical improvement is actor–critic methods, that not only learn approximate policy, the actor job, but also learn approximate value funciton, the critic job. This is because it reduces variance and accelerates learning via a bootstrapping critic that introduce bias which is often beneficial. Detailed algorithm in the paper illustrated below.
\[ \begin{align*} &\textbf{Algorithm Actor-critic training} \\ &1: \quad \textbf{ procedure } \text{ TRAIN(training set }S \text{, training steps }T \text{, batch size } B \text{)} \\ &2: \quad \quad \text{Initialize pointer network params } \theta \\ &3: \quad \quad \text{Initialize critic network params } \theta_{v} \\ &4: \quad \quad \textbf{for }t=1 \text{ to } T \textbf{ do }\\ &5: \quad \quad \quad s_{i} \sim \operatorname{SAMPLE INPUT } (S) \text{ for } i \in\{1, \ldots, B\} \\ &6: \quad \quad \quad \pi_{i} \sim \operatorname{SAMPLE SOLUTION } \left(p_{\theta}\left(\cdot | s_{i}\right)\right) \text{ for } i \in\{1, \ldots, B\} \\ &7: \quad \quad \quad b_{i} \leftarrow b_{\theta_{v}}\left(s_{i}\right) \text{ for } i \in\{1, \ldots, B\} \\ &8: \quad \quad \quad g_{\theta} \leftarrow \frac{1}{B} \sum_{i=1}^{B}\left(L\left(\pi_{i} | s_{i}\right)-b_{i}\right) \nabla_{\theta} \log p_{\theta}\left(\pi_{i} | s_{i}\right) \\ &9: \quad \quad \quad \mathcal{L}_{v} \leftarrow \frac{1}{B} \sum_{i=1}^{B} \left\| b_{i}-L\left(\pi_{i}\right) \right\| _{2}^{2} \\ &10: \quad \quad \quad \theta \leftarrow \operatorname{ADAM} \left( \theta, g_{\theta} \right) \\ &11: \quad \quad \quad \theta_{v} \leftarrow \operatorname{ADAM}\left(\theta_{v}, \nabla_{\theta_{v}} \mathcal{L}_{v}\right) \\ &12: \quad \quad \textbf{end for} \\ &13: \quad \textbf{return } \theta \\ &14: \textbf{end procedure} \end{align*} \]
Implementation in PyTorch
Beam Search in OpenNMT-py
In Episode 4 Search for Most Likely Sequence, an 3x3 rectangle trellis is given and several decoding methods are illustrated in plain python. In PyTorch version, there is a package OpenNMT-py that supports efficient batched beam search. But due to its complicated BeamSearch usage, previous problem is demonstrated using its API. For its details, please refer to Implementing Beam Search — Part 1: A Source Code Analysis of OpenNMT-py
1 | from copy import deepcopy |
The output is as follows. When \(k=2\) and 3 steps, the most likely sequence is \(0 \rightarrow 1 \rightarrow 0\), whose probability is 0.084.
1 | step 0 beam results: |
RL with PointerNetwork
The complete code is on github TSP RL. Below are partial core classes.
1 | class CombinatorialRL(nn.Module): |