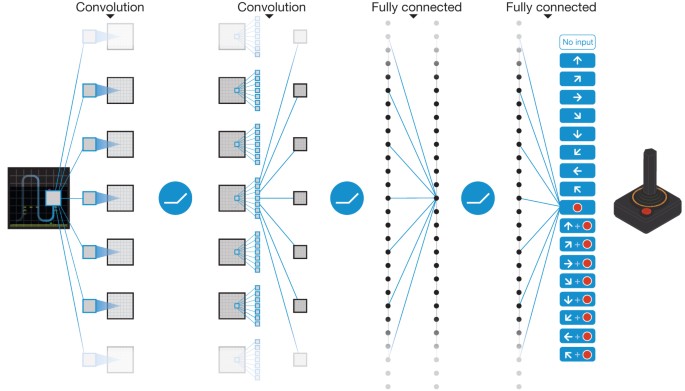
上一期 MyEncyclopedia公众号文章 SARSA、Q-Learning和Expected
SARSA时序差分算法训练CartPole 中,我们通过CartPole的OpenAI
Gym环境实现了Q-learning算法,这一期,我们将会分析Q-learning算法面临的maximization
bias 问题和提出double learning算法来改进。接着,我们将tabular
Q-learning算法扩展到用带参函数来近似 Q(s, a),这就是Deepmind
在2015年Nature上发表的Deep Q Network
(DQN)思想:用神经网络结合Q-learning算法实现超越人类玩家打Atari游戏的水平。
Q-Learning 回顾
\[
\begin{align*}
&\textbf{Q-learning (off-policy TD Control) for estimating } \pi
\approx \pi_{*} \\
& \text{Algorithm parameters: step size }\alpha \in ({0,1}]\text{,
small }\epsilon > 0 \\
& \text{Initialize }Q(s,a), \text{for all } s \in \mathcal{S}^{+},
a \in \mathcal{A}(s) \text{, arbitrarily except that } Q(terminal,
\cdot) = 0 \\
& \text{Loop for each episode:}\\
& \quad \text{Initialize }S\\
& \quad \text{Loop for each step of episode:} \\
& \quad \quad \text{Choose } A \text{ from } S \text{ using policy
derived from } Q \text{ (e.g., } \epsilon\text{-greedy)} \\
& \quad \quad \text{Take action }A, \text { observe } R, S^{\prime}
\\
& \quad \quad Q(S,A) \leftarrow Q(S,A) + \alpha[R+\gamma
\max_{a}Q(S^{\prime}, a) - Q(S,A)] \\
& \quad \quad S \leftarrow S^{\prime}\\
& \quad \text{until }S\text{ is terminal} \\
\end{align*}
\]
在SARSA、Q-Learning和Expected
SARSA时序差分算法训练CartPole 中,我们实现了同样基于 \(\epsilon\) -greedy
策略的Q-learning算法和SARSA算法,两者代码上的区别确实不大,但本质上Q-learning是属于
off-policy 范畴而 SARSA却属于 on-policy
范畴。一种理解方式是,Q-learning相比于SARSA少了第二次从 \(\epsilon\) -greedy
策略采样出下一个action,即S, A, R', S', A'
五元组中最后一个A',而直接通过max操作去逼近 \(q^{*}\) 。如此,Q-learning并没有像SARSA完成一次完整的GPI(Generalized
Policy Iteration),缺乏on-policy的策略迭代的特点,故而 Q-learning
属于off-policy方法。我们也可以从另一个角度来分析两者的区别。注意到这两个算法不是一定非要使用
\(\epsilon\) -greedy
策略的。对于Q-learning来说,完全可以使用随机策略,理论上已经证明,只要保证每个action以后依然有几率会被探索下去,Q-learning
最终会收敛到最优策略。Q-learning使用 \(\epsilon\) -greedy
是为了能快速收敛。对于SARSA算法来说,则无法使用随机策略,因为随机策略无法形成策略提升。而
\(\epsilon\) -greedy
策略却可以形成策略迭代,完成策略提升,当然,\(\epsilon\) -greedy 策略在 SARSA
算法中也可以保证快速收敛。因此,尽管两者都使用 \(\epsilon\) -greedy
策略再借由环境产生reward和state,它们的作用并非完全一样。至此,我们可以体会到on-policy和off-policy本质的区别。
收敛条件
Tabular Q-Learning 收敛到最佳Q函数的条件如下[2]:
\[
\Sigma^{\infty}_{n=0} \alpha_{n} = {\infty} \quad \text{ AND } \quad
\Sigma^{\infty}_{n=0} \alpha^2_{n} \lt {\infty}
\]
一种方式是将 \(\alpha\) 设置成 (s,
a)访问次数的倒数:\(\alpha_{n}(s,a) = 1/ n(s,a
)\)
则整体更新公式为
\[
Q(s,a) \leftarrow Q(s,a) + \alpha_n(s, a)[R+\gamma
\max_{a^{\prime}}Q(s^{\prime}, a^{\prime}) - Q(s, a)]
\]
Q-Learning 最大化偏差问题
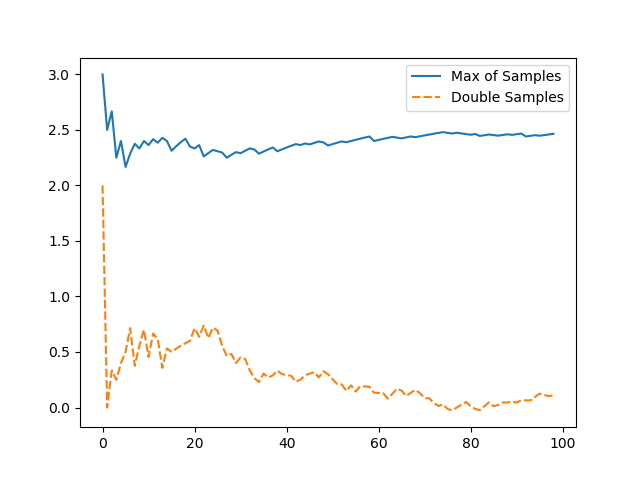
Q-Learning 会产生最大化偏差问题(Maximization Bias,在Sutton
教材6.7节),它的原因是用估计值中取最大值去估计真实值中最大是有偏的。这个可以做如下试验来模拟,若有5个
[-3, 3] 的离散均匀分布 \(d_i\) ,\(\max(\mathbb{E}[d_i]) =
0\) ,但是若我们用单批采样 \(x_i \sim
d_i\) 来估算 \(\mathbb{E}[d_i]\) 在取max的话,\(\mathbb{E}[{\max(x_i)]}\)
是有bias的。但是如果我们将这个过程分解成选择最大action和评估其值两步,每一步用独立的采样集合就可以做到无偏,这个改进方法称为double
learning。具体过程为第一步在\(Q_1\) 集合中找到最大的action,第二步在\(Q_2\) 中返回此action值,即:
\[
\begin{align*}
A^{\star} = \operatorname{argmax}_{a}Q_1(a) \\
Q_2(A^{\star}) = Q_2(\operatorname{argmax}_{a}Q_1(a))
\end{align*}
\]
则无限模拟后结果是无偏的:\(\mathbb{E}[Q_2(A^{\star})] = q(A^{\star})\)
下面是简单模拟试验两种方法的均值比较
Maximization Bias
试验完整代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import randomfrom math import floorimport numpy as npimport pandas as pdimport seaborn as snsdef uniform (a: int , b: int ) -> int : u = random.random() return a + floor((b - a + 1 ) * u) if __name__ == "__main__" : total_max_bias = 0 avgs_max_bias = [] total_double_sampling = 0 avgs_double_sampling = [] for e in range (1 , 100 ): samples = np.array([uniform(-3 , 3 ) for _ in range (5 )]) max_sample = max (samples) total_max_bias += max_sample avgs_max_bias.append(total_max_bias / e) samples2 = np.array([uniform(-3 , 3 ) for _ in range (5 )]) total_double_sampling += samples2[np.argmax(samples)] avgs_double_sampling.append(total_double_sampling / e) df = pd.DataFrame({'Max of Samples' : avgs_max_bias, 'Double Samples' : avgs_double_sampling}) import matplotlib.pyplot as plt sns.lineplot(data=df) plt.show()
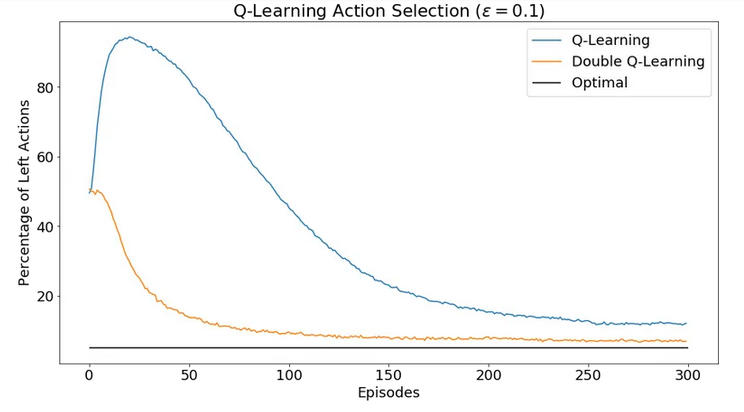
回到Q-learning 中使用的 \(\epsilon\) -greedy策略,Q-learning可以保证随着\(\epsilon\) 的减小,最大化偏差会
asymptotically 趋近于真实值,但是double learning
可以更快地趋近于真实值。
Maximization Bias vs Double learning
下面是Sutton 强化学习第二版6.7节中完整的Double Q-learning算法。
\[
\begin{align*}
&\textbf{Double Q-learning, for estimating } Q_1 \approx Q_2
\approx q_{*} \\
& \text{Algorithm parameters: step size }\alpha \in ({0,1}]\text{,
small }\epsilon > 0 \\
& \text{Initialize }Q_1(s,a), \text{ and } Q_2(s,a) \text{, for all
} s \in \mathcal{S}^{+}, a \in \mathcal{A}(s) \text{, such that }
Q(terminal, \cdot) = 0 \\
& \text{Loop for each episode:}\\
& \quad \text{Initialize }S\\
& \quad \text{Loop for each step of episode:} \\
& \quad \quad \text{Choose } A \text{ from } S \text{ using policy }
\epsilon\text{-greedy in } Q_1 + Q_2 \\
& \quad \quad \text{Take action }A, \text { observe } R, S^{\prime}
\\
& \quad \quad \text{With 0.5 probability:} \\
& \quad \quad \quad Q_1(S,A) \leftarrow Q_1(S,A) + \alpha \left (
R+\gamma Q_2(S^{\prime}, \operatorname{argmax}_{a}Q_1(S^{\prime}, a)) -
Q_1(S,A) \right )\\
& \quad \quad \text{else:} \\
& \quad \quad \quad Q_1(S,A) \leftarrow Q_1(S,A) + \alpha \left (
R+\gamma Q_2(S^{\prime}, \operatorname{argmax}_{a}Q_1(S^{\prime}, a)) -
Q_1(S,A) \right )\\
& \quad \quad S \leftarrow S^{\prime}\\
& \quad \text{until }S\text{ is terminal} \\
\end{align*}
\]
更详细内容,可以参考 Hado V. Hasselt 的 Double Q-learning paper
[3]。
Gradient Q-Learning
Tabular
Q-learning由于受制于维度爆炸,无法扩展到高维状态空间,一般近似解决方案是用
approximating function来逼近Q函数。即我们将状态抽象出一组特征 \(s = \vec x= [x_1, x_2, ..., x_n]^T\) ,Q
用一个 x 的函数来近似表达 \(Q(s, a) \approx
g(\vec x;
\theta)\) ,如此,就联系起了深度神经网络。有了函数表达,深度学习还必须的元素是损失函数,这个很自然的可以用
TD
error。至此,问题转换成深度学习的几个要素均已具备,Q-learning算法改造成了深度学习中的有监督问题。
估计值:\(Q\left(s, a ;
\theta\right)\)
目标值:\(r+\gamma \max _{a^{\prime}}
Q\left(s^{\prime}, a^{\prime} ; \theta\right)\)
损失函数:
\[
L\left(\theta\right)=\mathbb{E}_{\left(s, a, r, s^{\prime}\right) \sim
\mathrm{U}(D)}\left[\left(r+\gamma \max _{a^{\prime}} Q\left(s^{\prime},
a^{\prime} ; \theta\right)-Q\left(s, a ; \theta\right)\right)^{2}\right]
\]
收敛性分析
首先明确一点,至此 gradient q-learning 和 tabular Q-learning
一样,都是没有记忆的,即对于一个新的环境产生的 sample 去做 stochastic
online update。
若Q函数是状态特征的线性函数,即 \(Q(s, a;
\theta) = \Sigma_i w_i x_i\) ,那么线性Gradient
Q-learning的收敛条件和Tabular Q-learning 一样,也为
\[
\Sigma^{\infty}_{n=0} \alpha_{n} = {\infty} \quad \text{ AND } \quad
\Sigma^{\infty}_{n=0} \alpha^2_{n} \lt {\infty}
\]
若Q函数是非线性函数,即使符合上述条件,也无法保证收敛,本质上源于改变
\(\theta\) 使得 Q 值在 (s, a)
点上减小误差会影响 (s, a) 周边点的误差。
DQN减少不收敛的两个技巧
\(\theta_{i-1} \rightarrow
\theta_{i}\) 改变导致max中的估计值和目标值中的Q同时变化,面临着
chasing its own tail
的问题。解决的方法是使用不同的参数来parameterize两个Q,并且目标值的Q网络参数固定一段时间产生一批固定策略下的环境采样。这个技巧称为
Target Network。引入这个 trick 后深度学习的要素变成
估计值:\(Q\left(s, a ;
\theta_{i}\right)\)
目标值:\(r+\gamma \max _{a^{\prime}}
Q\left(s^{\prime}, a^{\prime} ; \theta_i^{-}\right)\)
损失函数,DQN在Nature上的loss函数: \[
L\left(\theta_{i}\right)=\mathbb{E}_{\left(s, a, r, s^{\prime}\right)
\sim \mathrm{U}(D)}\left[\left(r+\gamma \max _{a^{\prime}}
Q\left(s^{\prime}, a^{\prime} ; \theta_{i}^{-}\right)-Q\left(s, a ;
\theta_{i}\right)\right)^{2}\right]
\]
尽管目标值的 \(Q(;\theta^{-})\) 固定了,但是\(\theta_{i-1} \rightarrow \theta_{i}\)
还会使得估计值的 \(Q(s, a;\theta_i)\)
在变化的同时影响其他的 \(Q(s_k,
a_j;\theta_i)\) ,让之前训练过的 (s,
a)的点的损失值发生变化,解决的办法是将 online stochastic 改成 batch
gradient,也就是将最近的一系列采样值保存下来,这个方法称为 experience
replay。
有了这两个优化,Deep Q
Network投入实战效果就容易收敛了,以下是Deepmind 发表在Nature 的
Human-level control through deep reinforcement learning [1]
的完整算法流程。
\[
\begin{align*}
&\textbf{Deep Q-learning with experience replay}\\
& \text{Initialize replay memory } D\text{ to capacity } N \\
& \text{Initialize action-value function } Q \text{ with random
weights } \theta \\
& \text{Initialize target action-value function } \hat{Q} \text{
with weights } \theta^{-} = \theta \\
& \textbf{For} \text{ episode = 1, } M \textbf{ do} \\
& \text{Initialize sequences } s_1 = \{x_1\} \text{ and preprocessed
sequence } \phi_1 = \phi(s_1)\\
& \quad \textbf{For } t=\text{ 1, T }\textbf{ do} \\
& \quad \quad \text{With probability }\epsilon \text{ select a
random action } a_t \\
& \quad \quad \text{otherwise select } a_t =
\operatorname{argmax}_{a}Q(\phi(s_t), a; \theta)\\
& \quad \quad \text{Execute action } a_t \text{ in emulator and
observe reward } r_t \text{ and image }x_{t+1}\\
& \quad \quad \text{Set } s_{t+1} = s_t, a_t, x_{t+1} \text{ and
preprocess } \phi_{t+1} = \phi(s_{t+1})\\
& \quad \quad \text{Store transition } (\phi_t, a_t, r_t,
\phi_{t+1}) \text{ in } D\\
& \quad \quad \text{Sample random minibatch of transitions }
(\phi_j, a_j, r_j, \phi_{j+1}) \text{ from } D\\
& \quad \quad \text{Set } y_j=
\begin{cases}
r_j \quad \quad\quad\quad\text{if episode terminates at step
j+1}\\
r_j + \gamma \max_{a^{\prime}}\hat Q(\phi_{j+1}, a^{\prime};
\theta^{-}) \quad \text { otherwise}\\
\end{cases} \\
& \quad \quad \text{Perform a gradient descent step on } (y_j -
Q(\phi_j, a_j; \theta))^2 \text{ with respect to the network parameters
} \theta\\
& \quad \quad \text{Every C steps reset } \hat Q = Q\\
& \quad \textbf{End For} \\
& \textbf{End For}
\end{align*}
\]
DQN with Double Q-Learning
DQN 算法和 Double Q-Learning 能不能结合起来呢?Hado van Hasselt 在
Deep Reinforcement Learning with Double Q-learning [4] 中提出参考 Double
Q-learning 将 DQN
的目标值改成如下函数,可以进一步提升最初DQN的效果。
目标值:\(r+\gamma Q(s^{\prime}, \max
_{a^{\prime}} Q\left(s^{\prime}, a^{\prime}; \theta_t\right);
\theta_t^{-})\)
参考资料
Human-level control through deep reinforcement
learning Volodymyr Mnih, Koray Kavukcuoglu, David Silver
(2015)
CS885 Reinforcement Learning Lecture 4b: May 11, 2018
Double Q-learning Hado V. Hasselt
(2010)
Deep Reinforcement Learning with Double
Q-learning Hado van Hasselt, Arthur Guez, David Silver
(2015)