PaddleOCR CPU 镜像
本期和大家分享一个一键就可以开箱集用的OCR docker 本地服务。
众所周知 PaddleOCR 是一个百度 PaddlePaddle 中非常有名的OCR框架,它包含了丰富的中英文模型。官方也提供给了 GPU 的 docker 镜像,但是基于 GPU 的镜像,对于很多小伙伴来说有点大材小用了。因为很多小伙伴不需要去训练自己的数据集和调参,只要用成熟的模型就足够了。另外,无论在 Windows 还是 Linux 中,大家配置安装 nvidia GPU 镜像都是比较麻烦。因此,这次特地为大家打造了这样一个 CPU 的 PaddleOCR 镜像,并且把常规的模型都预装到镜像中了,大家一键就能部署强悍的本地 OCR 服务。只需要安装 Docker 即可,也支持 Mac。
文字效果
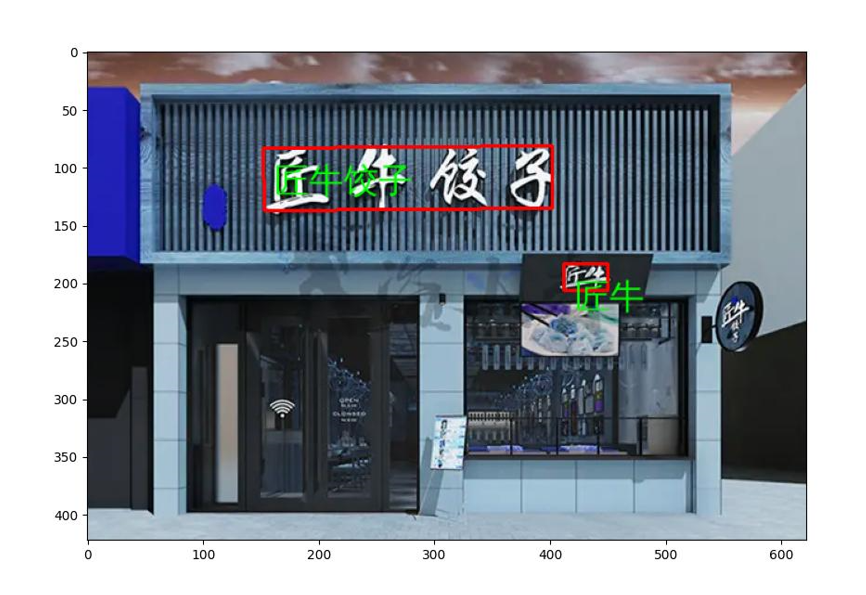
先来看一个文字识别的效果吧,图片中这家店铺使用了非常规的中文字体,但PaddleOCR依然完全识别了出来。
获取镜像
具体获取方式为:关注 MyEncyclopedia 公众号,回复
docker-paddleocr
下面的命令一键起了这个镜像,注意,大家要将
me-paddleocr 替换成公众号中的镜像名。
1 | docker run -it me-paddleocr bash |
进入容器后,我们已经在 /proj目录,通过 ls
可以发现有如下文件,三个图片demo输入文件,scene.png,
engtest.jpg, me.png 和
demo_ch.py。
命令行识别
通过 PaddleOCR 内置的命令可以最快捷地识别文字,命令格式如下。
1 | paddleocr --image_dir scene.png --use_angle_cls true --lang ch --use_gpu false |
输出为,最后两行为识别出的两处文字及其位置。
1 | ppocr INFO: **********scene.png********** |
代码识别
当然了,为了方便查看结果,需要通过代码来实现。下面展示镜像内置的三个demo图片的执行python
代码 demo_ch.py 后的输出效果。
结果展示
图片一:门头照片
图片二:中英文混合的试卷 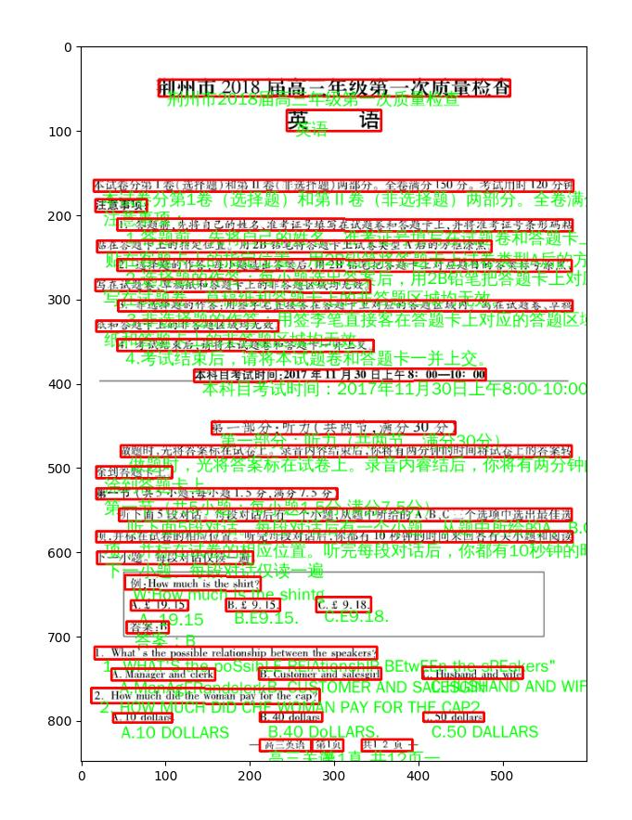
图片三:中英文混合Logo 
demo_ch.py
附上 demo_ch.py 源代码,不做赘述。
1 | from paddleocr import PaddleOCR |
结束语
PaddleOCR最为市面上最好的开源中文 OCR 引擎之一,其强悍的效果可以达到开箱即用,本期基于 CPU 的预制镜像更降低了大家使用的门槛。本系列后续会和大家分享如何在 PaddleOCR GPU 镜像中去训练自己的数据集,来提升特定字体的准确度,大家喜欢的话不要忘记一键三连哦。同时也可以关注 MyEncyclopedia 微信公众号以及B站频道,下次再见。