for v inrange(N): next_q.put(PQItem(initial[v], str(v)))
for l inrange(1, L): current_q = next_q next_q = PriorityQueue() k = K whilenot current_q.empty() and k > 0: item = current_q.get() prob, route, prev_v = item.prob, item.route, item.last_v k -= 1 for v inrange(N): nextItem = PQItem(prob * transition[prev_v][v], route + str(v)) next_q.put(nextItem)
# AC # Runtime: 32 ms, faster than 54.28% of Python3 online submissions for Pow(x, n). # Memory Usage: 14.2 MB, less than 5.04% of Python3 online submissions for Pow(x, n).
classSolution: defmyPow(self, x: float, n: int) -> float: ret = 1.0 i = abs(n) while i != 0: if i & 1: ret *= x x *= x i = i >> 1 return1.0 / ret if n < 0else ret
对应的 Java 的代码。
{linenos
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
// AC // Runtime: 1 ms, faster than 42.98% of Java online submissions for Pow(x, n). // Memory Usage: 38.7 MB, less than 48.31% of Java online submissions for Pow(x, n).
classSolution{ publicdoublemyPow(double x, int n){ double ret = 1.0; long i = Math.abs((long) n); while (i != 0) { if ((i & 1) > 0) { ret *= x; } x *= x; i = i >> 1; }
publicint[][] matrixProd(int[][] A, int[][] B) { int R = A.length; int C = B[0].length; int P = A[0].length; int[][] ret = newint[R][C]; for (int r = 0; r < R; r++) { for (int c = 0; c < C; c++) { for (int p = 0; p < P; p++) { ret[r][c] += A[r][p] * B[p][c]; } } } return ret; }
The Fibonacci numbers, commonly denoted F(n) form a
sequence, called the Fibonacci sequence, such that each
number is the sum of the two preceding ones, starting from 0 and 1. That
is,
1 2
F(0) = 0, F(1) = 1 F(N) = F(N - 1) + F(N - 2), for N > 1.
/** * AC * Runtime: 0 ms, faster than 100.00% of Java online submissions for Fibonacci Number. * Memory Usage: 37.9 MB, less than 18.62% of Java online submissions for Fibonacci Number. * * Method: Matrix Fast Power Exponentiation * Time Complexity: O(log(N)) **/ classSolution{ publicintfib(int N){ if (N <= 1) { return N; } int[][] M = {{1, 1}, {1, 0}}; // powers = M^(N-1) N--; int[][] powerDouble = M; int[][] powers = {{1, 0}, {0, 1}}; while (N > 0) { if (N % 2 == 1) { powers = matrixProd(powers, powerDouble); } powerDouble = matrixProd(powerDouble, powerDouble); N = N / 2; }
return powers[0][0]; }
publicint[][] matrixProd(int[][] A, int[][] B) { int R = A.length; int C = B[0].length; int P = A[0].length; int[][] ret = newint[R][C]; for (int r = 0; r < R; r++) { for (int c = 0; c < C; c++) { for (int p = 0; p < P; p++) { ret[r][c] += A[r][p] * B[p][c]; } } } return ret; }
# AC # Runtime: 256 ms, faster than 26.21% of Python3 online submissions for Fibonacci Number. # Memory Usage: 29.4 MB, less than 5.25% of Python3 online submissions for Fibonacci Number.
classSolution:
deffib(self, N: int) -> int: if N <= 1: return N
import numpy as np F = np.array([[1, 1], [1, 0]])
N -= 1 powerDouble = F powers = np.array([[1, 0], [0, 1]]) while N > 0: if N % 2 == 1: powers = np.matmul(powers, powerDouble) powerDouble = np.matmul(powerDouble, powerDouble) N = N // 2
return powers[0][0]
或者也可以直接调用numpy.matrix_power() 代替手动的快速矩阵幂运算。
{linenos
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
# AC # Runtime: 116 ms, faster than 26.25% of Python3 online submissions for Fibonacci Number. # Memory Usage: 29.2 MB, less than 5.25% of Python3 online submissions for Fibonacci Number.
classSolution:
deffib(self, N: int) -> int: if N <= 1: return N
from numpy.linalg import matrix_power import numpy as np F = np.array([[1, 1], [1, 0]]) F = matrix_power(F, N - 1)
return F[0][0]
Leetcode
1411. Number of Ways to Paint N × 3 Grid (Hard)
You have a grid of size n x 3 and you want
to paint each cell of the grid with exactly one of the three colours:
Red, Yellow or Green
while making sure that no two adjacent cells have the same colour (i.e
no two cells that share vertical or horizontal sides have the same
colour).
You are given n the number of rows of the grid.
Return the number of ways you can paint this
grid. As the answer may grow large, the answer must
be computed modulo 10^9 + 7.
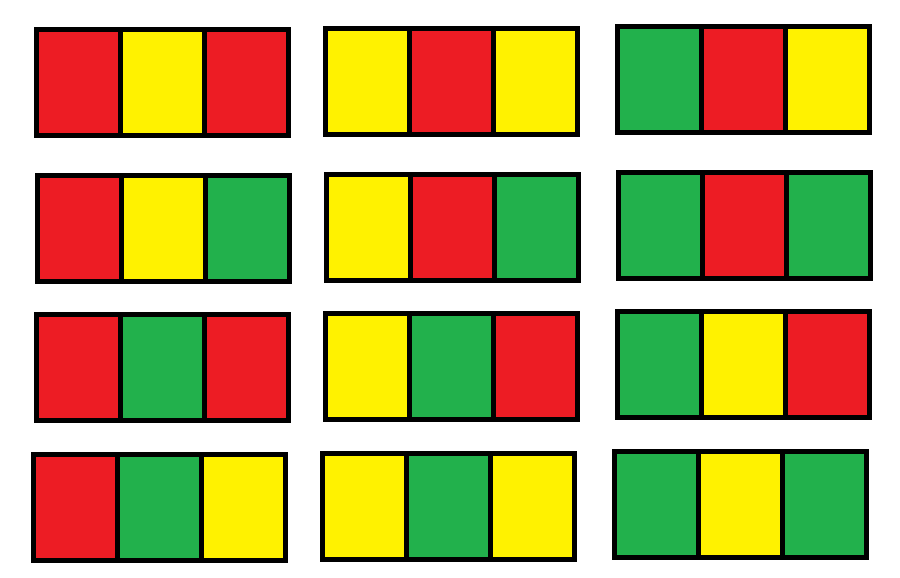
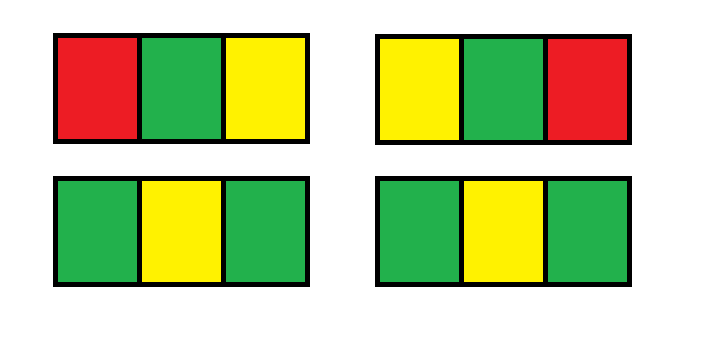
Example 1:
1 2 3
Input: n = 1 Output: 12 Explanation: There are 12 possible way to paint the grid as shown:
# AC # Runtime: 36 ms, faster than 98.88% of Python3 online submissions for Number of Ways to Paint N × 3 Grid. # Memory Usage: 13.9 MB, less than 58.66% of Python3 online submissions for Number of Ways to Paint N × 3 Grid.
classSolution: defnumOfWays(self, n: int) -> int: MOD = 10 ** 9 + 7 dp2, dp3 = 6, 6 n -= 1 while n > 0: dp2, dp3 = (dp2 * 3 + dp3 * 2) % MOD, (dp2 * 2 + dp3 * 2) % MOD n -= 1 return (dp2 + dp3) % MOD
/** AC Runtime: 0 ms, faster than 100.00% of Java online submissions for Number of Ways to Paint N × 3 Grid. Memory Usage: 35.7 MB, less than 97.21% of Java online submissions for Number of Ways to Paint N × 3 Grid. **/
classSolution{ publicintnumOfWays(int n){ long MOD = (long) (1e9 + 7); long[][] ret = {{6, 6}}; long[][] m = {{3, 2}, {2, 2}}; n -= 1; while(n > 0) { if ((n & 1) > 0) { ret = matrixProd(ret, m, MOD); } m = matrixProd(m, m, MOD); n >>= 1; } return (int) ((ret[0][0] + ret[0][1]) % MOD);
}
publiclong[][] matrixProd(long[][] A, long[][] B, long MOD) { int R = A.length; int C = B[0].length; int P = A[0].length; long[][] ret = newlong[R][C]; for (int r = 0; r < R; r++) { for (int c = 0; c < C; c++) { for (int p = 0; p < P; p++) { ret[r][c] += A[r][p] * B[p][c]; ret[r][c] = ret[r][c] % MOD; } } } return ret; }
}
Python 3实现为
{linenos
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
# AC # Runtime: 88 ms, faster than 39.07% of Python3 online submissions for Number of Ways to Paint N × 3 Grid. # Memory Usage: 30.2 MB, less than 11.59% of Python3 online submissions for Number of Ways to Paint N × 3 Grid.
classSolution: defnumOfWays(self, n: int) -> int: import numpy as np
MOD = int(1e9 + 7) ret = np.array([[6, 6]]) m = np.array([[3, 2], [2, 2]])
n -= 1 while n > 0: if n % 2 == 1: ret = np.matmul(ret, m) % MOD m = np.matmul(m, m) % MOD n = n // 2 returnint((ret[0][0] + ret[0][1]) % MOD)
for (int bitset_num = N; bitset_num >=0; bitset_num++) { while(hasNextCombination(bitset_num)) { int state = nextCombination(bitset_num); // compute dp[state][v], v-th bit is set in state for (int v = 0; v < n; v++) { for (int u = 0; u < n; u++) { // for each u not reached by this state if (!include(state, u)) { dp[state][v] = min(dp[state][v], dp[new_state_include_u][u] + dist[v][u]); } } } } }
ret: float = FLOAT_INF u_min: int = -1 for u inrange(self.g.v_num): if (state & (1 << u)) == 0: s: float = self._recurse(u, state | 1 << u) if s + edges[v][u] < ret: ret = s + edges[v][u] u_min = u dp[state][v] = ret self.parent[state][v] = u_min
当最终最短行程确定后,根据parent的信息可以按图索骥找到完整的行程顶点信息。
{linenos
1 2 3 4 5 6 7 8 9
def_form_tour(self): self.tour = [0] bit = 0 v = 0 for _ inrange(self.g.v_num - 1): v = self.parent[bit][v] self.tour.append(v) bit = bit | (1 << v) self.tour.append(0)
V = np.zeros(env.nS) changed_state_set = set(s for s inrange(env.nS))
iter = 0 whilelen(changed_state_set) > 0: changed_state_set_ = set() for s in changed_state_set: action_values = action_value(env, s, V, gamma=gamma) best_action_value = np.max(action_values) v_diff = np.abs(best_action_value - V[s]) if v_diff > theta: changed_state_set_.update(mapping[s]) V[s] = best_action_value changed_state_set = changed_state_set_ iter += 1
policy = np.zeros([env.nS, env.nA]) for s inrange(env.nS): action_values = action_value(env, s, V, gamma=gamma) best_action = np.argmax(action_values) policy[s, best_action] = 1.0
return policy, V
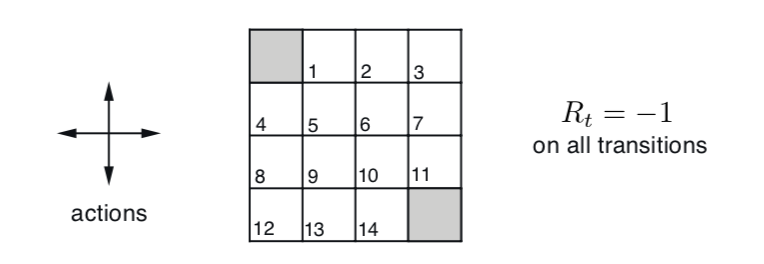
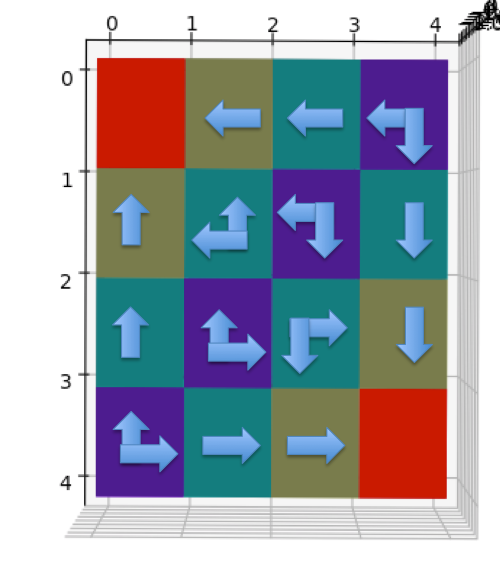
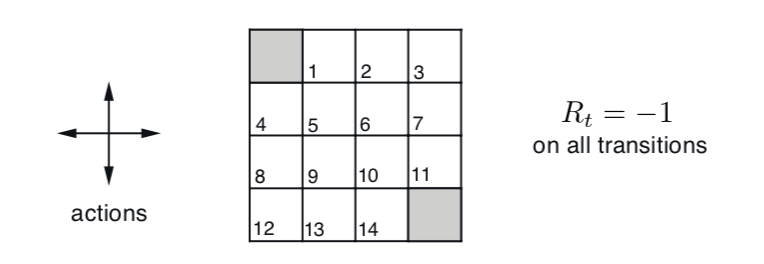
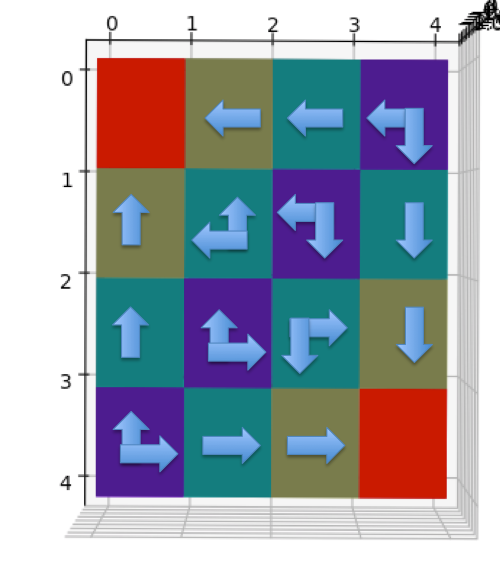
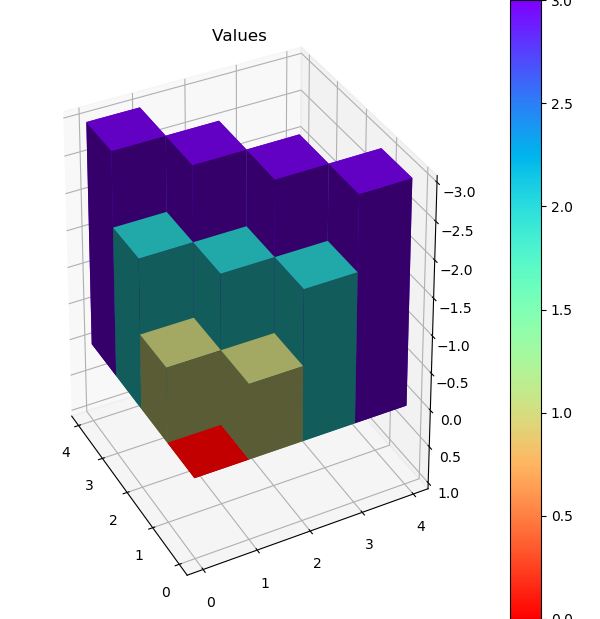
比较值迭代和异步值迭代方法后发现,值迭代用了4次循环,每次涉及所有状态,总计算状态数为
4 x 16 = 64。异步值迭代也用了4次循环,但是总计更新了54个状态。由于Grid
World
的状态数很少,异步值迭代优势并不明显,但是对于状态数众多并且迭代最终集中在少部分状态的环境下,节省的计算量还是很可观的。
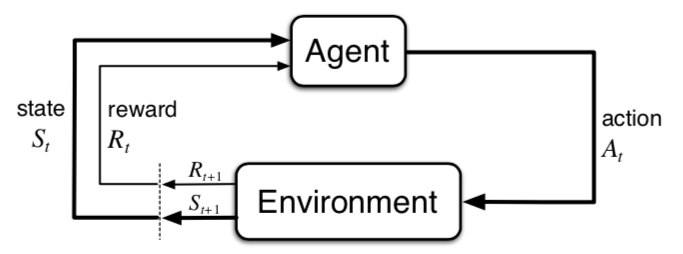
经典教材Reinforcement Learning: An Introduction
第二版由强化领域权威Richard S. Sutton 和 Andrew G. Barto
完成编写,内容深入浅出,非常适合初学者。在本篇中,引入Grid
World示例,结合强化学习核心概念,并用python代码实现OpenAI
Gym的模拟环境,进一步实现策略评价算法。
即是四元组作为输入的概率函数 \(p: S \times
R \times S \times A \rightarrow [0, 1]\)。
满足 \[
\sum_{s^{\prime} \in \mathcal{S}} \sum_{r \in \mathcal{R}}
p\left(s^{\prime}, r \mid s, a\right)=1, \text { for all } s \in
\mathcal{S}, a \in \mathcal{A}(s)
\]
\[
q_{\pi}(s, a) \doteq \mathbb{E}_{\pi}\left[G_{t} \mid S_{t}=s,
A_{t}=a\right]
\]
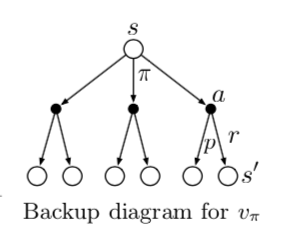
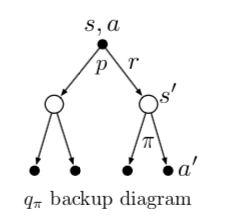
下面是 $q_{}(s, a) $ 的递推 backup diagram。
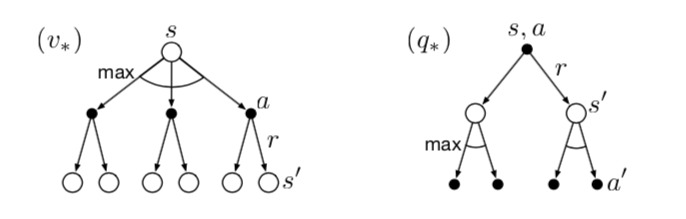
Bellman 最佳原则
对于所有状态集合\(\mathcal{S}\),策略\({\pi}\)的评价指标 \(v_{\pi}(s)\)
是一个向量,本质上是无法相互比较的。但由于存在Bellman
最佳原则(Bellman's principle of
optimality):在有限状态情况下,一定存在一个或者多个最好的策略 \({\pi}_{*}\),它在所有状态下的v值都是最好的,即
\(v_{\pi_{*}}(s) \ge v_{\pi^{\prime}}(s) \text
{ for all } s \in \mathcal{S}\)。
因此,最佳v值定义为最佳策略 \({\pi}_{*}\) 对应的 v 值
\[
v_{*}(s) \doteq \max_{\pi} v_{\pi}(s)
\]
同理,也存在最佳q值,记为 \[
\begin{aligned}
q_{*}(s, a) &\doteq \max_{\pi} q_{\pi}(s,a)
\end{aligned}
\]
旅行商问题(TSP)是计算机算法中经典的NP
hard 问题。 在本系列文章中,我们将首先使用动态规划 AC
aizu中的TSP问题,然后再利用深度学习求大规模下的近似解。深度学习应用解决问题时先以PyTorch实现监督学习算法
Pointer Network,进而结合强化学习来无监督学习,提高数据使用效率。
本系列完整列表如下:
TSP可以用图模型来表达,无论有向图或无向图,无论全连通图或者部分连通的图都可以作为TSP问题。
Wikipedia
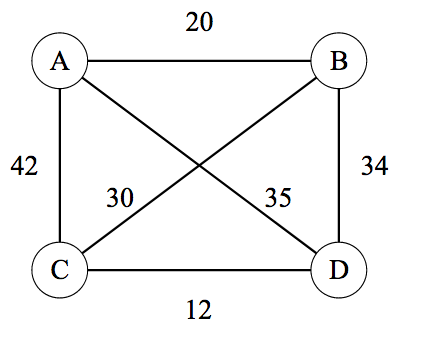
TSP
中举了一个无向全连通的TSP例子。如下图所示,四个顶点A,B,C,D构成无向全连通图。TSP问题要求在所有遍历所有点后返回初始点的回路中找到最短的回路。例如,\(A \rightarrow B \rightarrow C \rightarrow D
\rightarrow A\) 和 \(A \rightarrow C
\rightarrow B \rightarrow D \rightarrow A\)
都是有效的回路,但是TSP需要返回这些回路中的最短回路(注意,最短回路可能会有多条)。
publicGraph(int V_NUM){ this.V_NUM = V_NUM; this.edges = newint[V_NUM][V_NUM]; for (int i = 0; i < V_NUM; i++) { Arrays.fill(this.edges[i], Integer.MAX_VALUE); } } publicvoidsetDist(int src, int dest, int dist){ this.edges[src][dest] = dist; } } publicstaticclassTSP{ publicfinal Graph g; long[][] dp; publicTSP(Graph g){ this.g = g; } publiclongsolve(){ int N = g.V_NUM; dp = newlong[1 << N][N]; for (int i = 0; i < dp.length; i++) { Arrays.fill(dp[i], -1); } long ret = recurse(0, 0); return ret == Integer.MAX_VALUE ? -1 : ret; } privatelongrecurse(int state, int v){ int ALL = (1 << g.V_NUM) - 1; if (dp[state][v] >= 0) { return dp[state][v]; } if (state == ALL && v == 0) { dp[state][v] = 0; return0; } long res = Integer.MAX_VALUE; for (int u = 0; u < g.V_NUM; u++) { if ((state & (1 << u)) == 0) { long s = recurse(state | 1 << u, u); res = Math.min(res, s + g.edges[v][u]); } } dp[state][v] = res; return res; } } publicstaticvoidmain(String[] args){ Scanner in = new Scanner(System.in); int V = in.nextInt(); int E = in.nextInt(); Graph g = new Graph(V); while (E > 0) { int src = in.nextInt(); int dest = in.nextInt(); int dist = in.nextInt(); g.setDist(src, dest, dist); E--; } System.out.println(new TSP(g).solve()); } }
def__init__(self, v_num: int): self.v_num = v_num self.edges = [[INT_INF for c inrange(v_num)] for r inrange(v_num)] defsetDist(self, src: int, dest: int, dist: int): self.edges[src][dest] = dist
classTSPSolver: g: Graph dp: List[List[int]]
def__init__(self, g: Graph): self.g = g self.dp = [[Nonefor c inrange(g.v_num)] for r inrange(1 << g.v_num)] defsolve(self) -> int: return self._recurse(0, 0) def_recurse(self, v: int, state: int) -> int: """ :param v: :param state: :return: -1 means INF """ dp = self.dp edges = self.g.edges if dp[state][v] isnotNone: return dp[state][v] if (state == (1 << self.g.v_num) - 1) and (v == 0): dp[state][v] = 0 return dp[state][v] ret: int = INT_INF for u inrange(self.g.v_num): if (state & (1 << u)) == 0: s: int = self._recurse(u, state | 1 << u) if s != INT_INF and edges[v][u] != INT_INF: if ret == INT_INF: ret = s + edges[v][u] else: ret = min(ret, s + edges[v][u]) dp[state][v] = ret return ret