上一篇我们从原理层面解析了AlphaGo Zero如何改进MCTS算法,通过不断自我对弈,最终实现从零棋力开始训练直至能够打败任何高手。在本篇中,我们在已有的N子棋OpenAI Gym 环境中用Pytorch实现一个简化版的AlphaGo Zero算法。本篇所有代码在 github MyEncyclopedia/ConnectNGym 中,其中部分参考了SongXiaoJun 的 AlphaZero_Gomoku。
AlphaGo Zero MCTS 树节点
上一篇中,我们知道AlphaGo Zero 的MCTS树搜索是基于传统MCTS 的UCT (UCB for Tree)的改进版PUCT(Polynomial Upper Confidence Trees)。局面节点的PUCT值由两部分组成,分别是代表Exploitation的action value Q值,和代表Exploration的U值。 \[ PUCT(s, a) =Q(s,a) + U(s,a) \] U值计算由这些参数决定:系数\(c_{puct}\),节点先验概率P(s, a) ,父节点访问次数,本节点的访问次数。具体公式如下 \[ U(s, a)=c_{p u c t} \cdot P(s, a) \cdot \frac{\sqrt{\Sigma_{b} N(s, b)}}{1+N(s, a)} \]
因此在实现过程中,对于一个树节点来说,需要保存其Q值、节点访问次数 _visit_num和先验概率 _prior。其中,_prior在节点初始化后不变,Q值和 visit_num随着游戏MCTS模拟进程而改变。此外,节点保存了 parent和_children变量,用于维护父子关系。c_puct为class variable,作为全局参数。
1 | class TreeNode: |
和上面的计算公式相对应,下列代码根据节点状态计算PUCT(s, a)。
1 | class TreeNode: |
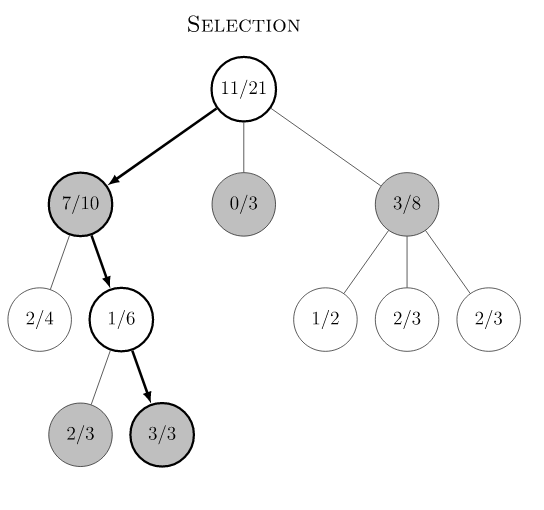
AlphaGo Zero MCTS在playout时遇到已经被展开的节点,会根据selection规则选择子节点,该规则本质上是在所有子节点中选择最大的PUCT值的节点。
\[ a=\operatorname{argmax}_a(PUCT(s, a))=\operatorname{argmax}_a(Q(s,a) + U(s,a)) \]
1 | class TreeNode: |
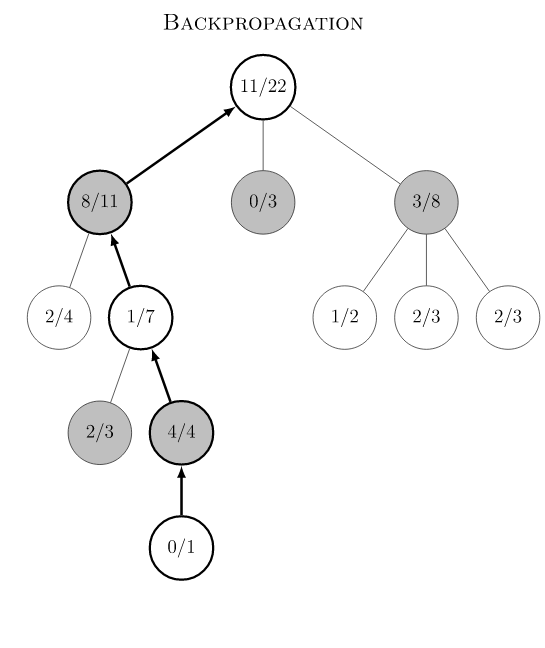
新的叶节点一旦在playout时产生,关联的 v 值会一路向上更新至根节点,具体新节点的v值将在下一节中解释。
1 | class TreeNode: |
AlphaGo Zero MCTS Player 实现
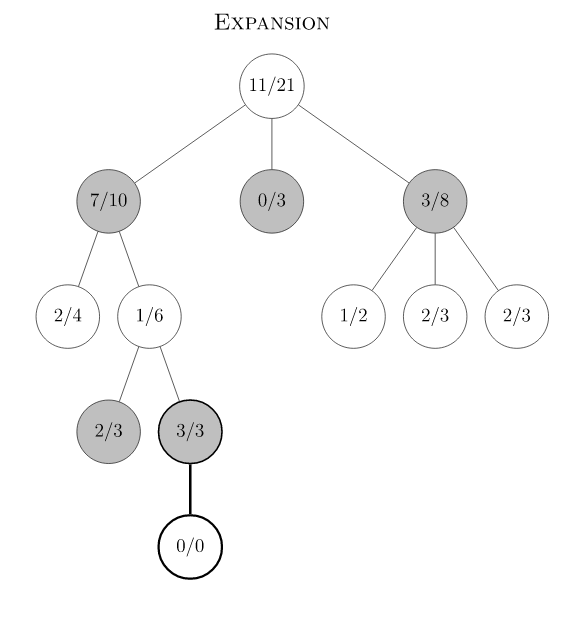
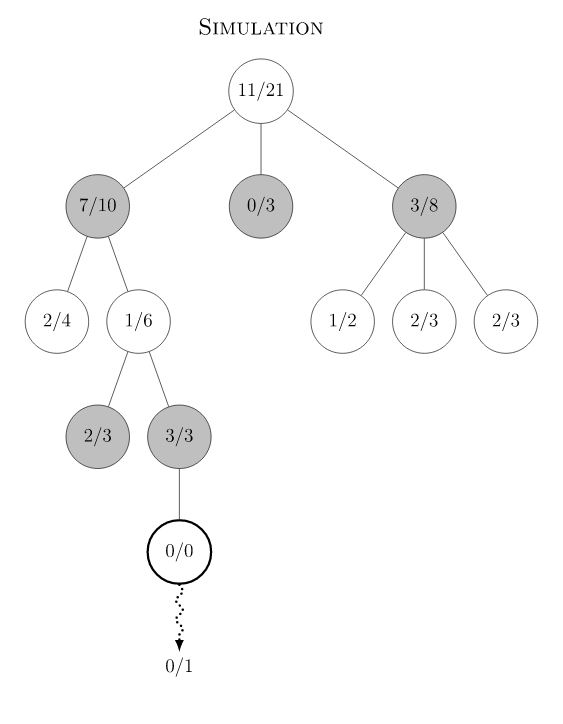
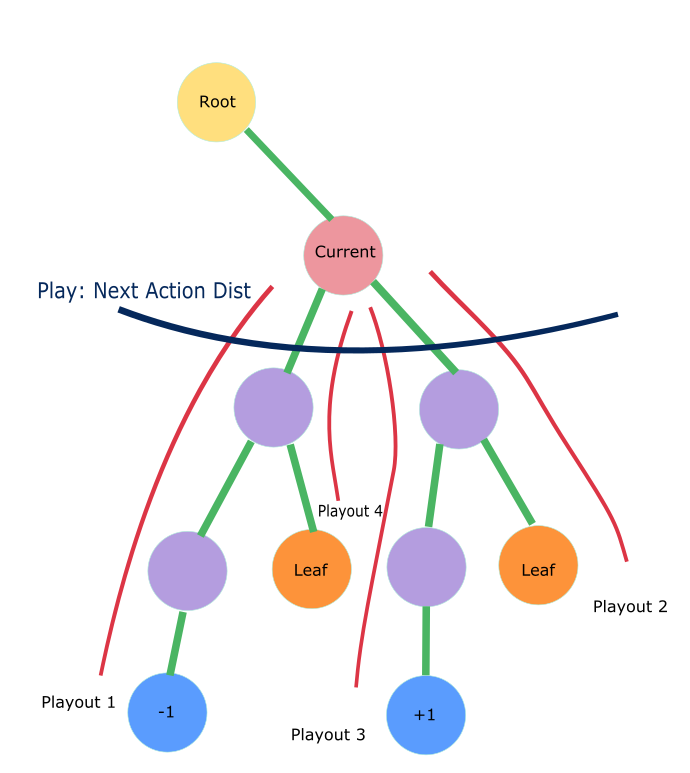
AlphaGo Zero MCTS 在训练阶段分为如下几个步骤。游戏初始局面下,整个局面树的建立由子节点的不断被探索而丰富起来。AlphaGo Zero对弈一次即产生了一次完整的游戏开始到结束的动作系列。在对弈过程中的某一游戏局面,需要采样海量的playout,又称MCTS模拟,以此来决定此局面的下一步动作。一次playout可视为在真实游戏状态树的一种特定采样,playout可能会产生游戏结局,生成真实的v值;也可能explore 到新的叶子节点,此时v值依赖策略价值网络的输出,目的是利用训练的神经网络来产生高质量的游戏对战局面。每次playout会从当前给定局面递归向下,向下的过程中会遇到下面三种节点情况。
- 若局面节点是游戏结局(叶子节点),可以得到游戏的真实价值 z。从底部节点带着z向上更新沿途节点的Q值,直至根节点(初始局面)。
- 若局面节点从未被扩展过(叶子节点),此时会将局面编码输入到策略价值双头网络,输出结果为网络预估的action分布和v值。Action分布作为节点先验概率P(s, a)来初始化子节点,预估的v值和上面真实游戏价值z一样,从叶子节点向上沿途更新到根节点。
- 若局面节点已经被扩展过,则根据PUCT的select规则继续选择下一节点。
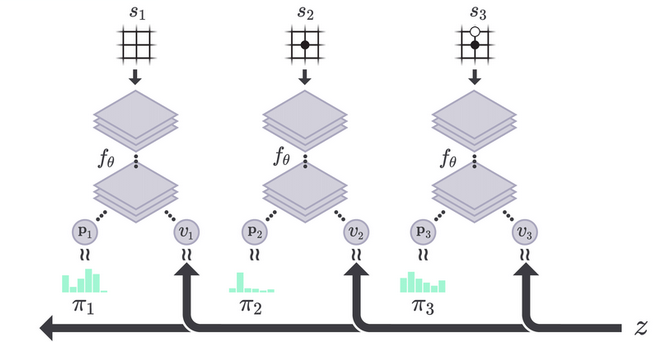
海量的playout模拟后,建立了游戏状态树的节点信息。但至此,AI玩家只是收集了信息,还仍未给定局面落子,而落子的决定由Play规则产生。下图展示了给定局面(Current节点)下,MCST模拟进行的多次playout探索后生成的局面树,play规则根据这些节点信息,产生Current 节点的动作分布 \(\pi\) ,确定下一步落子。
Play 给定局面
对于当前需要做落子决定的某游戏局面\(s_0\),根据如下play公式生成落子分布 $$ ,子局面的落子概率正比于其访问次数的某次方。其中,某次方的倒数称为温度参数(Temperature)。
\[ \pi\left(a \mid s_{0}\right)=\frac{N\left(s_{0}, a\right)^{1 / \tau}}{\sum_{b} N\left(s_{0}, b\right)^{1 / \tau}} \]
1 | class MCTSAlphaGoZeroPlayer(BaseAgent): |
在训练模式时,考虑到偏向exploration的目的,在\(\pi\) 落子分布的基础上增加了 Dirichlet 分布。
\[ P(s,a) = (1-\epsilon)*\pi(a \mid s) + \epsilon * \boldsymbol{\eta} \quad (\boldsymbol{\eta} \sim \operatorname{Dir}(0.3)) \]
1 | class MCTSAlphaGoZeroPlayer(BaseAgent): |
一次完整的对弈
一次完整的AI对弈就是从初始局面迭代play直至游戏结束,对弈生成的数据是一系列的 $(s, , z) $。
如下图 s0 到 s5 是某次井字棋的对弈。最终结局是先手黑棋玩家赢,即对于黑棋玩家 z = +1。需要注意的是:z = +1 是对于所有黑棋面临的局面,即s0, s2, s4,而对应的其余白棋玩家来说 z = -1。

\[ \begin{align*} &0: (s_0, \vec{\pi_0}, +1) \\ &1: (s_1, \vec{\pi_1}, -1) \\ &2: (s_2, \vec{\pi_2}, +1) \\ &3: (s_3, \vec{\pi_3}, -1) \\ &4: (s_4, \vec{\pi_4}, +1) \end{align*} \]
以下代码展示如何在AI对弈时收集数据 $(s, , z) $
1 | class MCTSAlphaGoZeroPlayer(BaseAgent): |
Playout 代码实现
一次playout会从当前局面根据PUCT selection规则下沉到叶子节点,如果此叶子节点非游戏终结点,则会扩展当前节点生成下一层新节点,其先验分布由策略价值网络输出的action分布决定。一次playout最终会得到叶子节点的 v 值,并沿着MCTS树向上更新沿途的所有父节点 Q值。 从上一篇文章已知,游戏节点的数量随着参数而指数级增长,举例来说,井字棋(k=3,m=n=3)的状态数量是5478,k=3,m=n=4时是6035992 ,k=m=n=4时是9722011 。如果我们将初始局面节点作为根节点,同时保存海量playout探索得到的局面节点,实现时会发现我们无法将所有探索到的局面节点都保存在内存中。这里的一种解决方法是在一次self play中每轮playout之后,将根节点重置成落子的节点,从而有效控制整颗局面树中的节点数量。
1 | class MCTSAlphaGoZeroPlayer(BaseAgent): |
编码游戏局面
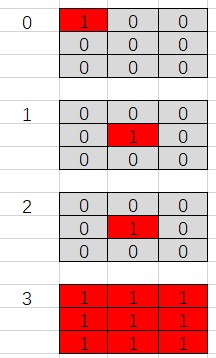
为了将信息有效的传递给策略神经网络,必须从当前玩家的角度编码游戏局面。局面不仅要反映棋盘上黑白棋子的位置,也需要考虑最后一个落子的位置以及是否为当前玩家棋局。因此,我们将某局面按照当前玩家来编码,返回类型为4个棋盘大小组成的ndarray,即shape [4, board_size, board_size],其中
- 第一个数组编码当前玩家的棋子位置
- 第二个数组编码对手玩家棋子位置
- 第三个表示最后落子位置
- 第四个全1表示此局面为先手(黑棋)局面,全0表示白棋局面
例如之前游戏对弈中的前四步:
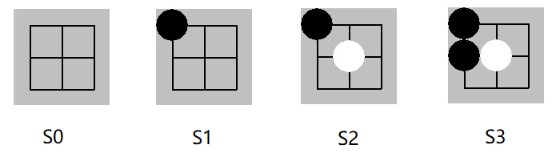
s1->s2 后局面s2的编码:当前玩家为黑棋玩家,编码局面s2 返回如下ndarray,数组[0] 为s2黑子位置,[1]为白子位置,[2]表示最后一个落子(1, 1) ,[3] 全1表示当前是黑棋落子的局面。
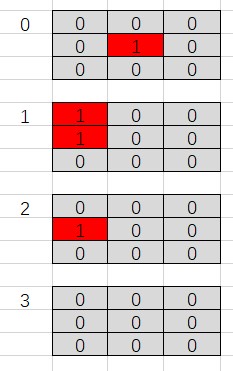
具体代码实现如下。
1 | NetGameState = NDArray[(4, Any, Any), np.int] |
策略价值网络训练
策略价值网络是一个共享参数 \(\theta\) 的双头网络,给定上面的游戏局面编码会产生预估的p和v。
\[ \vec{p_{\theta}}, v_{\theta}=f_{\theta}(s) \] 结合真实游戏对弈后产生三元组数据 $(s, , z) $ ,按照论文中的loss 来训练神经网络。 \[ l=\sum_{t}\left(v_{\theta}\left(s_{t}\right)-z_{t}\right)^{2}-\vec{\pi_{t}} \cdot \log \left(\vec{p_{\theta}}\left(s_{t}\right)\right) + c {\lVert \theta \rVert}^2 \]
下面代码为Pytorch backward部分。
1 | def backward_step(self, state_batch: List[NetGameState], probs_batch: List[ActionProbs], |
参考资料
Youtube, Deepmind AlphaZero - Mastering Games Without Human Knowledge, David Silver
Mastering the game of Go with deep neural networks and tree search
Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm