这期继续Sutton强化学习第二版,第五章蒙特卡洛方法。在上期21点游戏的策略蒙特卡洛值预测学习了如何用Monte Carlo来预估给定策略 \(\pi\) 的 \(V_{\pi}\) 值之后,这一期我们用Monte Carlo方法来解得21点游戏最佳策略 \(\pi_{*}\)。
蒙特卡洛策略提升
回顾一下,在Grid World 策略迭代和值迭代中由于存在Policy Improvement Theorem,我们可以利用环境dynamics信息计算出策略v值,再选取最greedy action的方式改进策略,形成策略提示最终能够不断逼近最佳策略。 \[ \pi_{0} \stackrel{\mathrm{E}}{\longrightarrow} v_{\pi_{0}} \stackrel{\mathrm{I}}{\longrightarrow} \pi_{1} \stackrel{\mathrm{E}}{\longrightarrow} v_{\pi_{1}} \stackrel{\mathrm{I}}{\longrightarrow} \pi_{2} \stackrel{\mathrm{E}}{\longrightarrow} \cdots \stackrel{\mathrm{I}}{\longrightarrow} \pi_{*} \stackrel{\mathrm{E}}{\longrightarrow} v_{*} \] Monte Carlo Control方法搜寻最佳策略 \(\pi{*}\),是否也能沿用同样的思路呢?答案是可行的。不过,不同于第四章中我们已知环境MDP就知道状态的前后依赖关系,进而从v值中能推断出策略 \(\pi\),在Monte Carlo方法中,环境MDP是未知的,因而我们只能从action-value中下手,通过海量Monte Carlo试验来近似 \(q_{\pi}\)。有了策略 Q 值,再和MDP策略迭代方法一样,选取最greedy action的策略,这种策略提示方式理论上被证明了最终能够不断逼近最佳策略。 \[ \pi_{0} \stackrel{\mathrm{E}}{\longrightarrow} q_{\pi_{0}} \stackrel{\mathrm{I}}{\longrightarrow} \pi_{1} \stackrel{\mathrm{E}}{\longrightarrow} q_{\pi_{1}} \stackrel{\mathrm{I}}{\longrightarrow} \pi_{2} \stackrel{\mathrm{E}}{\longrightarrow} \cdots \stackrel{\mathrm{I}}{\longrightarrow} \pi_{*} \stackrel{\mathrm{E}}{\longrightarrow} q_{*} \]
但是此方法有一个前提要满足,由于数据是依据策略 \(\pi_{i}\) 生成的,理论上需要保证在无限次的模拟过程中,每个状态都必须被无限次访问到,才能保证最终每个状态的Q估值收敛到真实的 \(q_{*}\)。满足这个前提的一个简单实现是强制随机环境初始状态,保证每个状态都能有一定概率被生成。这个思路就是 Monte Carlo Control with Exploring Starts算法,伪代码如下:
\[ \begin{align*} &\textbf{Monte Carlo ES (Exploring Starts), for estimating } \pi \approx \pi_{*} \\ & \text{Initialize:} \\ & \quad \pi(s) \in \mathcal A(s) \text{ arbitrarily for all }s \in \mathcal{S} \\ & \quad Q(s, a) \in \mathbb R \text{, arbitrarily, for all }s \in \mathcal{S}, a \in \mathcal A(s) \\ & \quad Returns(s, a) \leftarrow \text{ an empty list, for all }s \in \mathcal{S}, a \in \mathcal A(s)\\ & \\ & \text{Loop forever (for episode):}\\ & \quad \text{Choose } S_0\in \mathcal{S}, A_0 \in \mathcal A(S_0) \text{ randomly such that all pairs have probability > 0} \\ & \quad \text{Generate an episode from } S_0, A_0 \text{, following } \pi : S_0, A_0, R_1, S_1, A_1, R_2, ..., S_{T-1}, A_{T-1}, R_T\\ & \quad G \leftarrow 0\\ & \quad \text{Loop for each step of episode, } t = T-1, T-2, ..., 0:\\ & \quad \quad \quad G \leftarrow \gamma G + R_{t+1}\\ & \quad \quad \quad \text{Unless the pair } S_t, A_t \text{ appears in } S_0, A_0, S_1, A_1, ..., S_{t-1}, A_{t-1}\\ & \quad \quad \quad \quad \text{Append } G \text { to }Returns(S_t, A_t) \\ & \quad \quad \quad \quad Q(S_t, A_t) \leftarrow \operatorname{average}(Returns(S_t, A_t))\\ & \quad \quad \quad \quad \pi(S_t) \leftarrow \operatorname{argmax}_a Q(S_t, a)\\ \end{align*} \]
下面我们实现21点游戏的Monte Carlo ES 算法。21点游戏只有200个有效的状态,可以满足算法要求的生成episode前先随机选择某一状态的前提条件。
相对于上一篇,我们增加 ActionValue和Policy的类型定义,ActionValue表示 \(q(s, a)\) ,是一个State到动作分布的Dict,Policy 类型也一样。Actions为一维ndarray,维数是离散动作数量。
1 | State = Tuple[int, int, bool] |
下面代码示例如何给定 Policy后,依据指定状态state的动作分布采样,决定下一动作。
1 | policy: Policy |
整个算法的 python 代码实现如下:
1 | def mc_control_exploring_starts(env: BlackjackEnv, num_episodes, discount_factor=1.0) \ |
在MC Exploring Starts 算法中,我们需要指定环境初始状态,一种做法是env.reset()时接受初始状态,但是考虑到不去修改第三方实现的 BlackjackEnv类,采用一个取巧的办法,在调用reset()后直接改写env 的私有变量,这个逻辑封装在 reset_env_with_s0 方法中。
1 | def reset_env_with_s0(env: BlackjackEnv, s0: State) -> BlackjackEnv: |
算法结果的可视化和理论对比
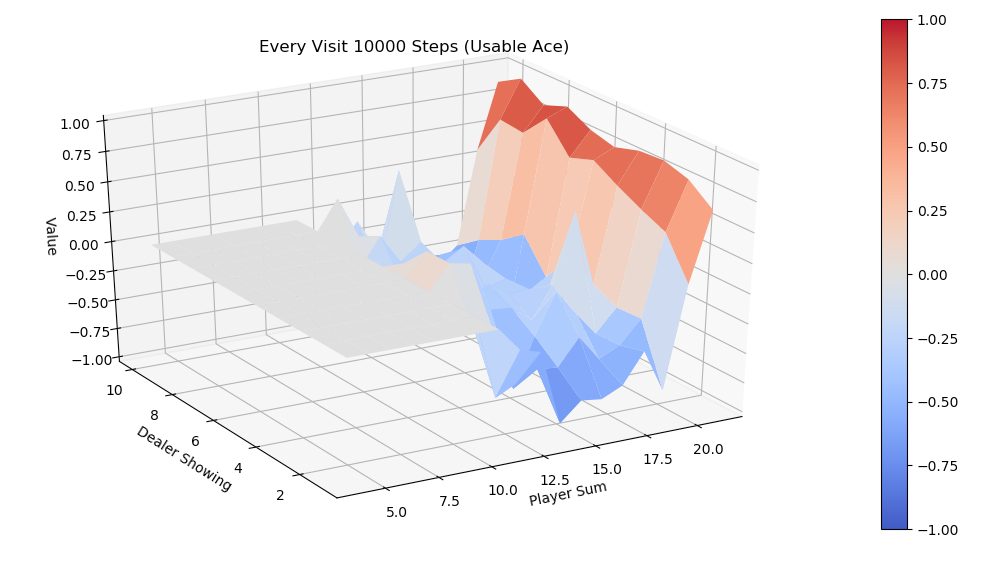
下图是有Usable Ace情况下的理论最优策略。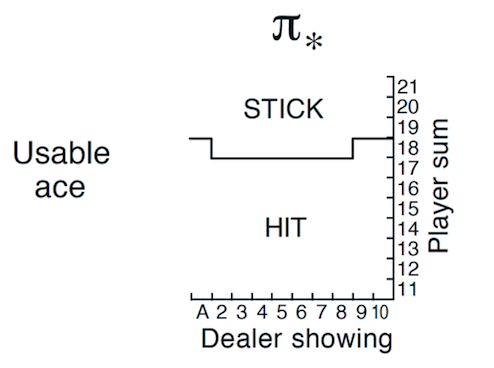
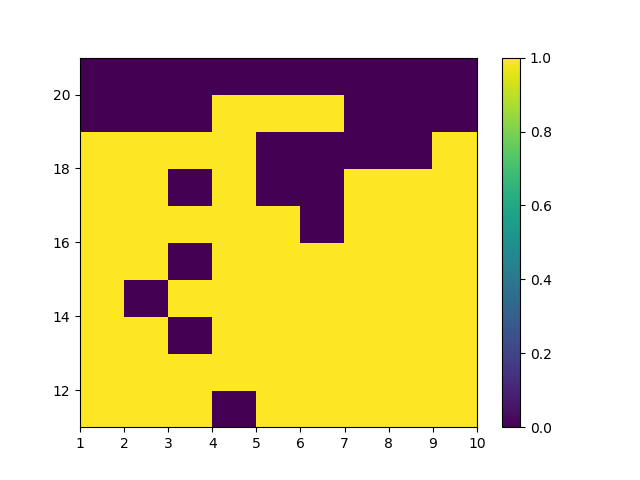
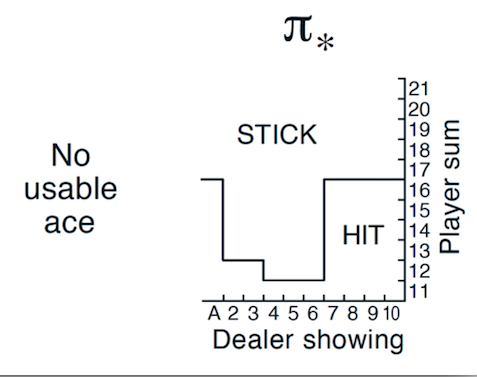
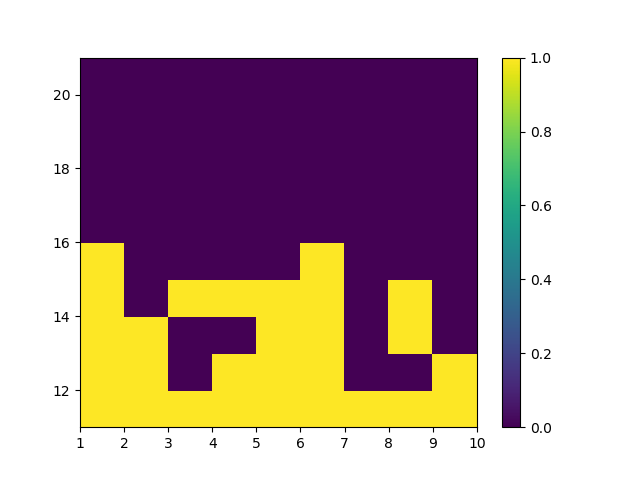
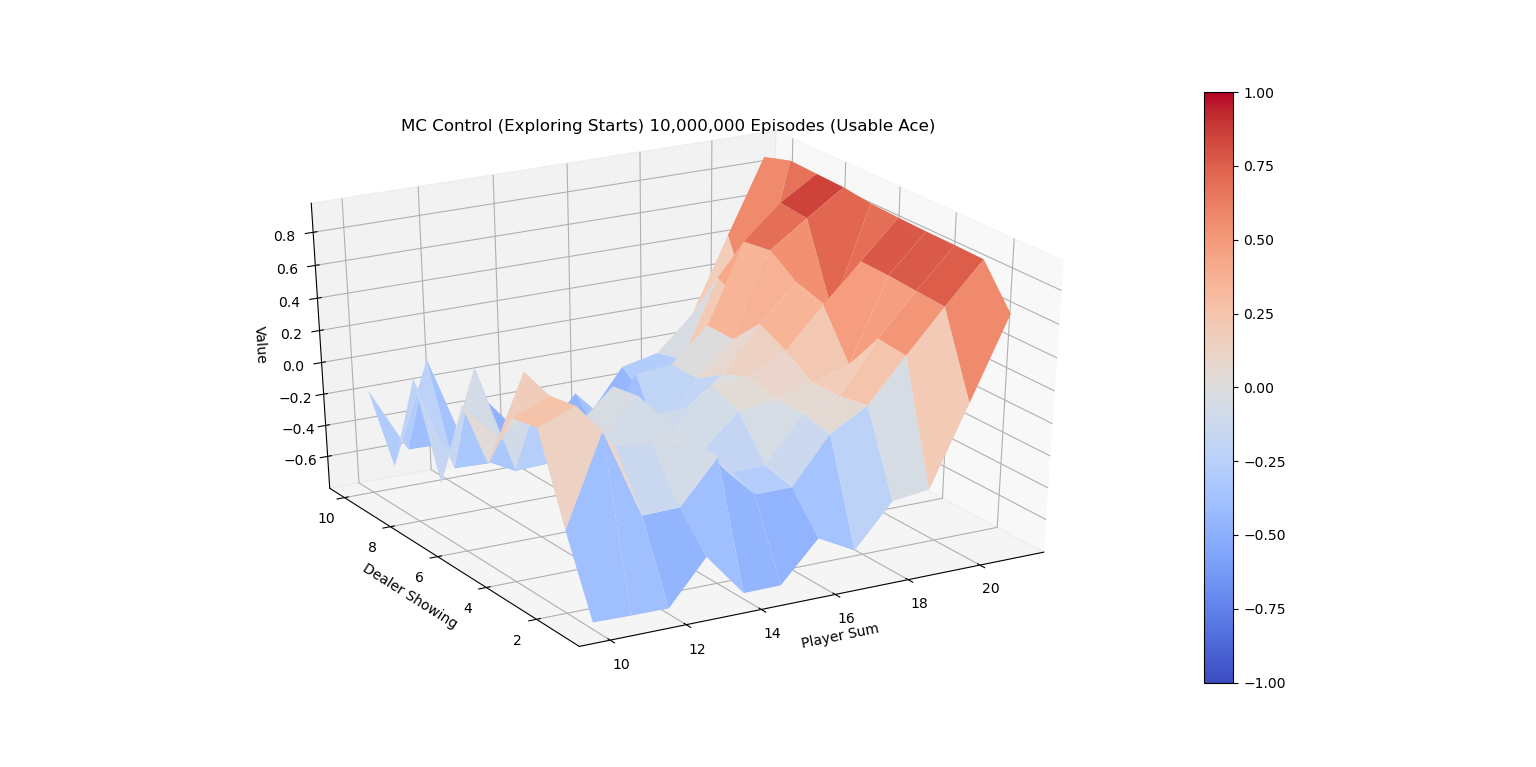
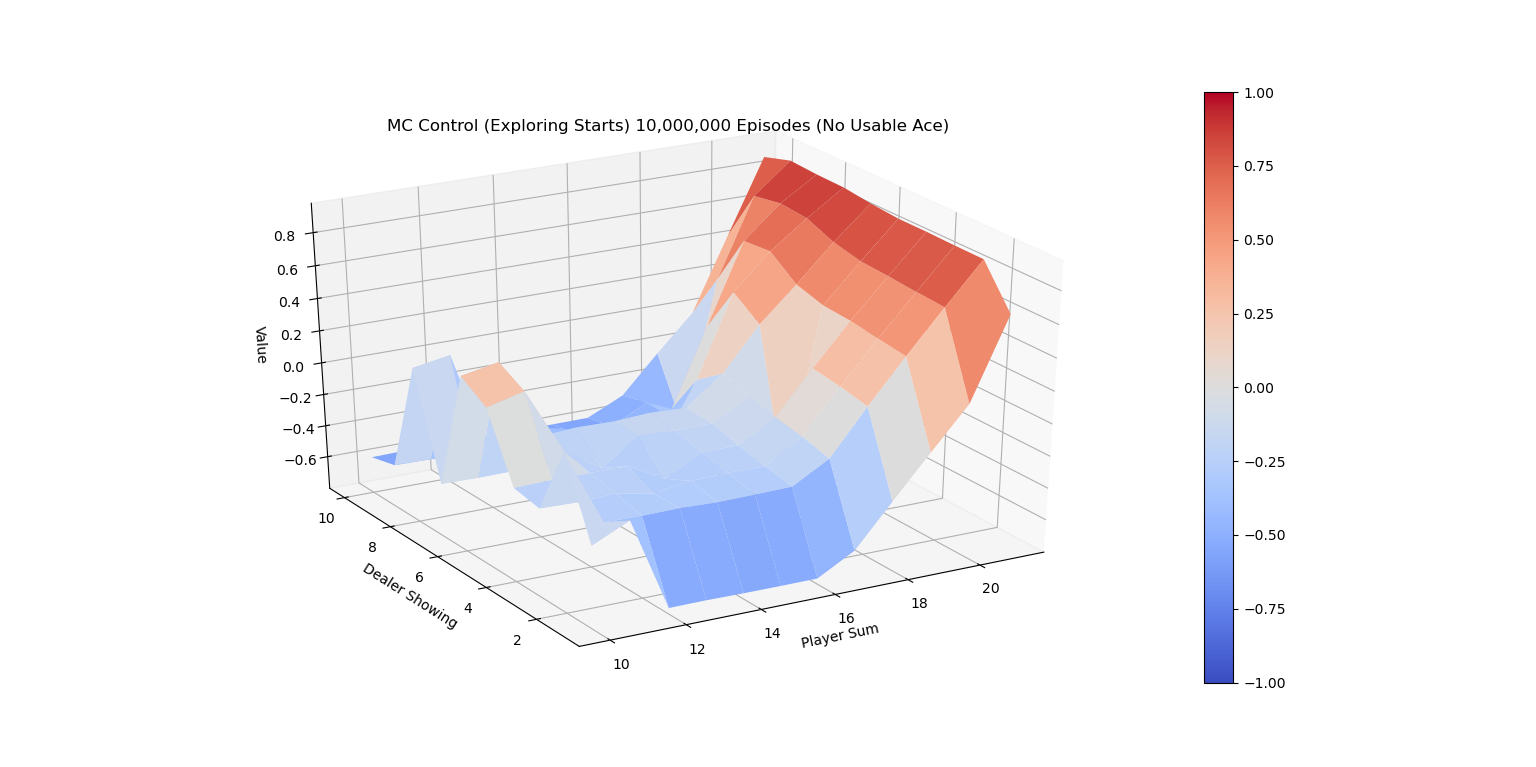
Exploring Starts 蒙特卡洛控制改进
为了避免Monte Carlo ES Control在初始时必须访问到任意状态的限制,教材中介绍了一种改进算法,On-policy first-visit MC control for \(\epsilon \text{-soft policies}\) ,它同样基于Monte Carlo 预估Q值,但用 \(\epsilon \text{-soft}\) 策略来代替最有可能的action策略作为下一次迭代策略,\(\epsilon \text{-soft}\) 本质上来说就是对于任意动作都保留 \(\epsilon\) 小概率的访问可能,权衡了exploration和exploitation,由于每个动作都可能被无限次访问到,Explorting Starts中的强制随机初始状态就可以去除了。Monte Carlo ES Control 和 On-policy first-visit MC control for \(\epsilon \text{-soft policies}\) 都属于on-policy算法,其区别于off-policy的本质在于预估 \(q_{\pi}(s,a)\)时是否从同策略\(\pi\)生成的数据来计算。一个比较subtle的例子是著名的Q-Learning,因为根据这个定义,Q-Learning属于off-policy。
\[ \begin{align*} &\textbf{On-policy first-visit MC control (for }\epsilon \textbf{-soft policies), estimating } \pi \approx \pi_{*} \\ & \text{Algorithm parameter: small } \epsilon > 0 \\ & \text{Initialize:} \\ & \quad \pi \leftarrow \text{ an arbitrary } \epsilon \text{-soft policy} \\ & \quad Q(s, a) \in \mathbb R \text{, arbitrarily, for all }s \in \mathcal{S}, a \in \mathcal A(s) \\ & \quad Returns(s, a) \leftarrow \text{ an empty list, for all }s \in \mathcal{S}, a \in \mathcal A(s)\\ & \\ & \text{Repeat forever (for episode):}\\ & \quad \text{Generate an episode following } \pi : S_0, A_0, R_1, S_1, A_1, R_2, ..., S_{T-1}, A_{T-1}, R_T\\ & \quad G \leftarrow 0\\ & \quad \text{Loop for each step of episode, } t = T-1, T-2, ..., 0:\\ & \quad \quad \quad G \leftarrow \gamma G + R_{t+1}\\ & \quad \quad \quad \text{Unless the pair } S_t, A_t \text{ appears in } S_0, A_0, S_1, A_1, ..., S_{t-1}, A_{t-1}\\ & \quad \quad \quad \quad \text{Append } G \text { to }Returns(S_t, A_t) \\ & \quad \quad \quad \quad Q(S_t, A_t) \leftarrow \operatorname{average}(Returns(S_t, A_t))\\ & \quad \quad \quad \quad A^{*} \leftarrow \operatorname{argmax}_a Q(S_t, a)\\ & \quad \quad \quad \quad \text{For all } a \in \mathcal A(S_t):\\ & \quad \quad \quad \quad \quad \pi(a|S_t) \leftarrow \begin{cases} 1 - \epsilon + \epsilon / |\mathcal A(S_t)| & \text{ if } a = A^{*}\\ \epsilon / |\mathcal A(S_t)| & \text{ if } a \neq A^{*}\\ \end{cases} \\ \end{align*} \]
伪代码对应的 Python 实现如下。
1 | def mc_control_epsilon_greedy(env: BlackjackEnv, num_episodes, discount_factor=1.0, epsilon=0.1) \ |
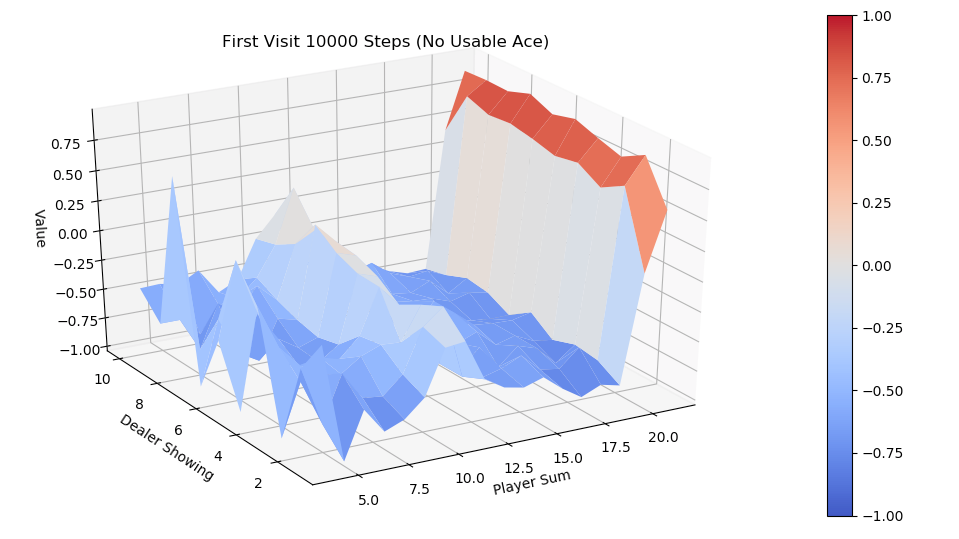
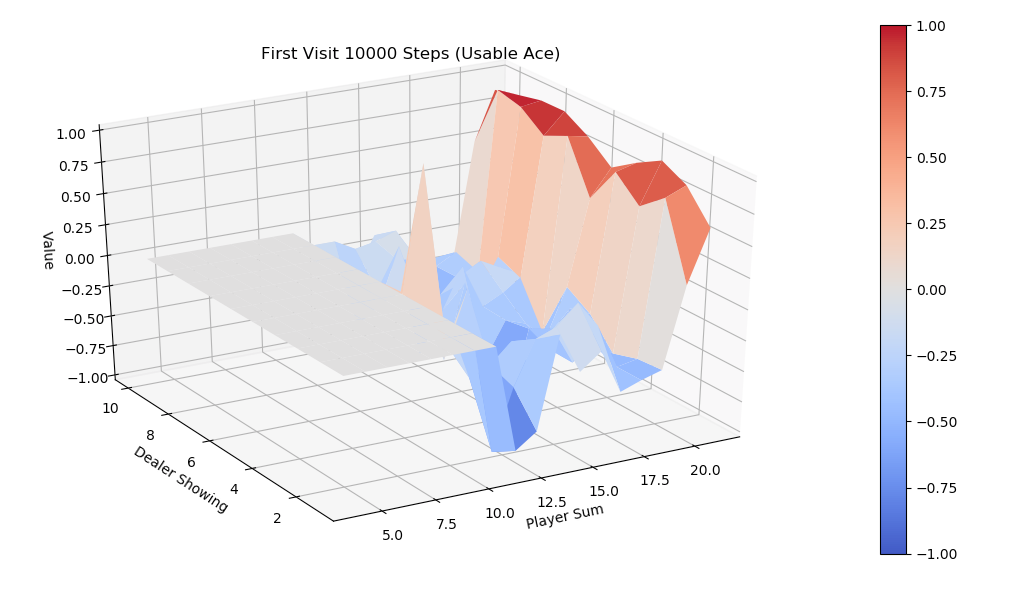
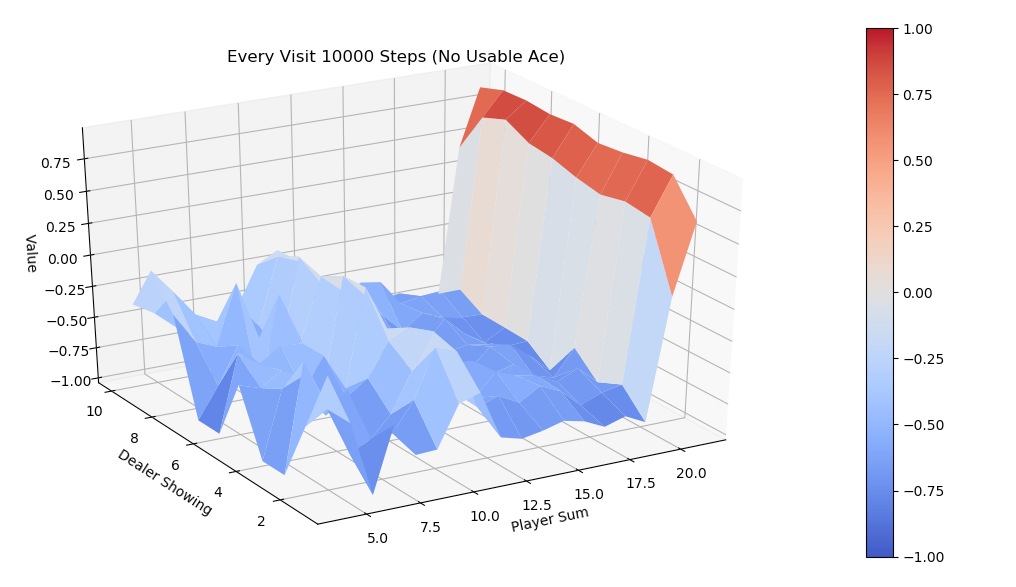
.png)
.png)