请在桌面浏览器中打开此链接,保证最好的浏览体验
关注公众号后回复
docker-geometric,获取 Docker Image

1 | # 导入image |
在学习了一些基本的统计变量生成法之后,这次我们来看看如何生成正态分布。它就是大名鼎鼎的 Box-Muller 方法,Box-Muller 的理解过程可以体会到统计模拟的一些精妙思想。
我们先尝试通过标准的逆变换方法来生成正态分布。
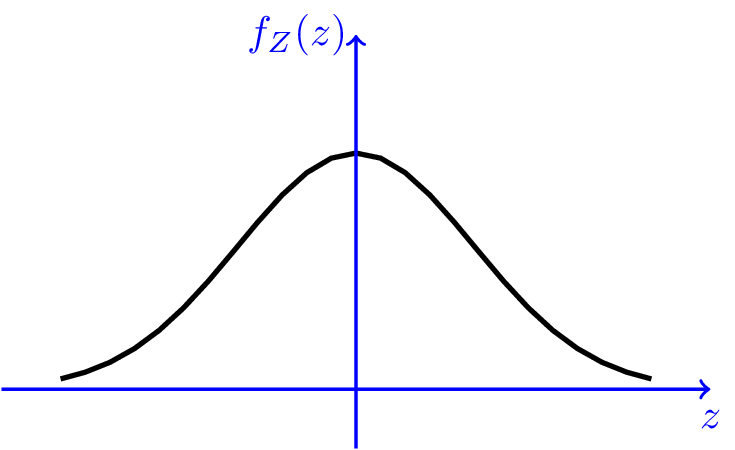
正态分布的 PDF 表达式为
\[ f_Z(z) = \frac{1}{\sqrt{2 \pi}} \exp\left\{-\frac{z^2}{2}\right\} \]
对应的函数图形是钟形曲线
根据 PDF,其 CDF 的积分形式为 \[ \Phi(x)=\frac{1}{\sqrt{2 \pi}} \int_{-\infty}^{x} e^{-t^{2} / 2} d t \]
和所有 PDF CDF 关系一样,\(\Phi(x)\) 表示 \(f_Z\) 累积到 \(x\) 点的面积。
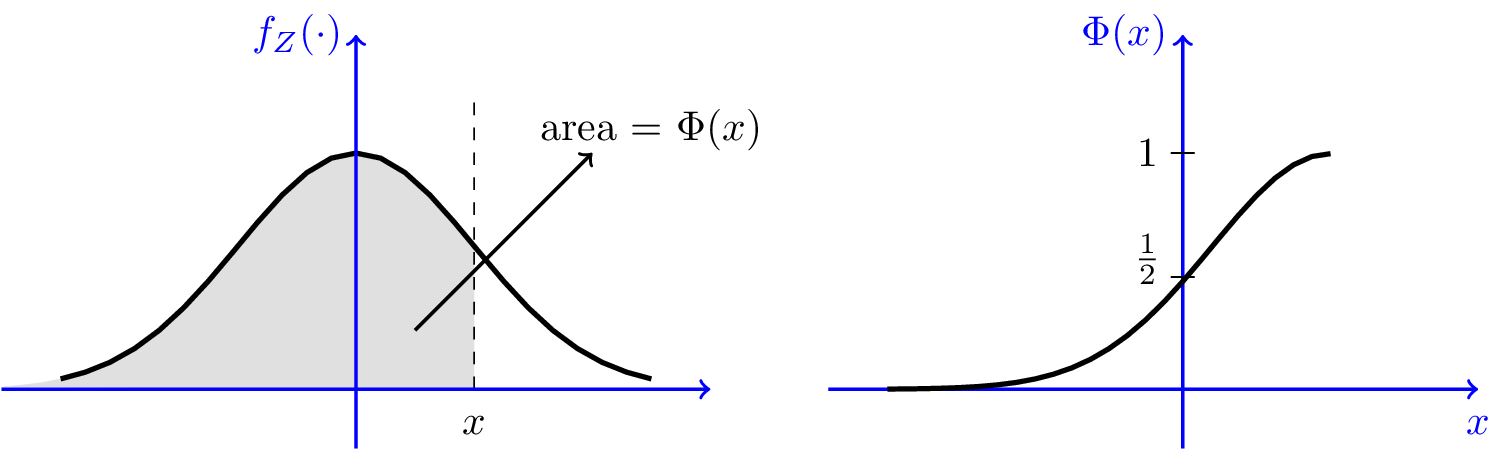
很不幸的是,\(\Phi(x)\) 无法写出一般数学表达式,因而也无法直接用逆变换方法。
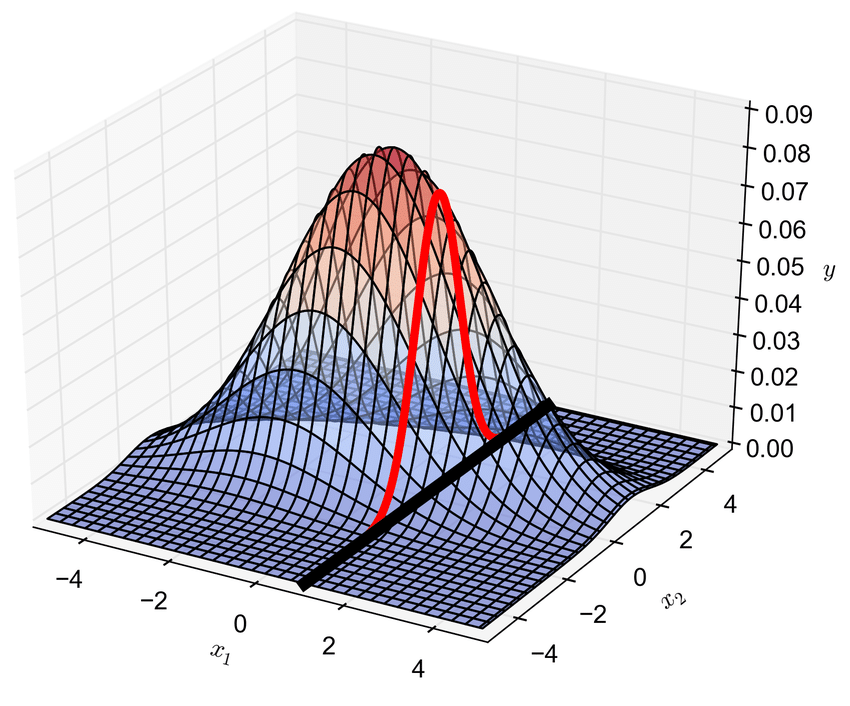
我们知道,高维正态分布有特殊的性质:它的每一维的分量都是正态分布;单个维度对于其他维度的条件概率分布也是正态分布。
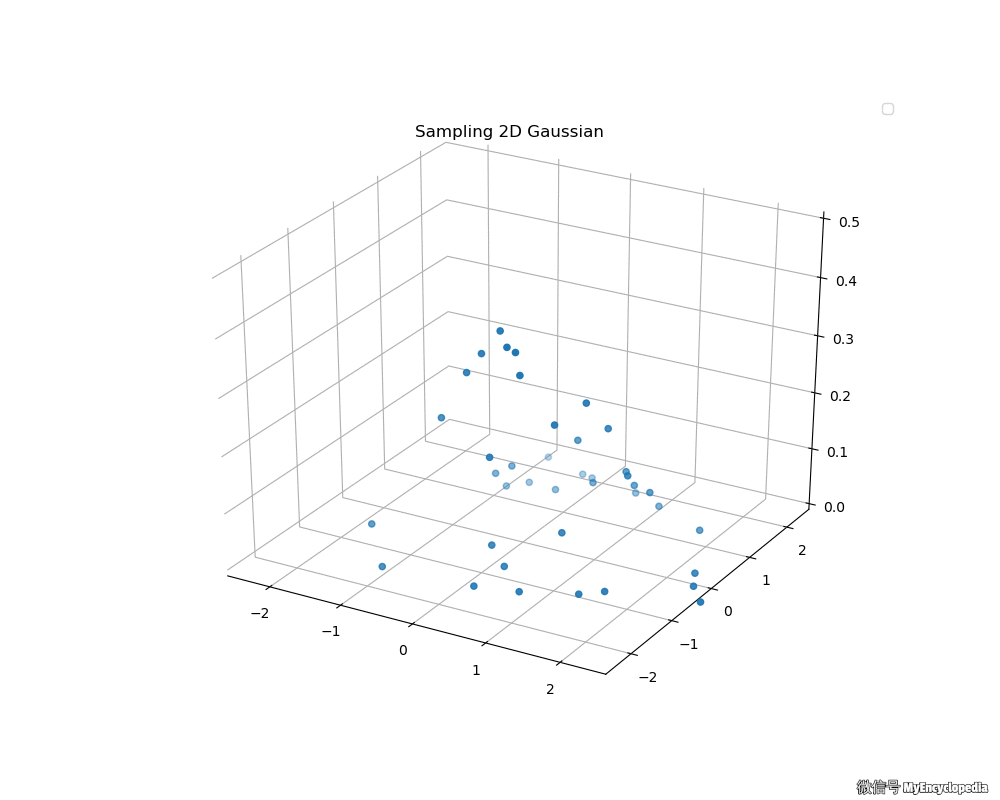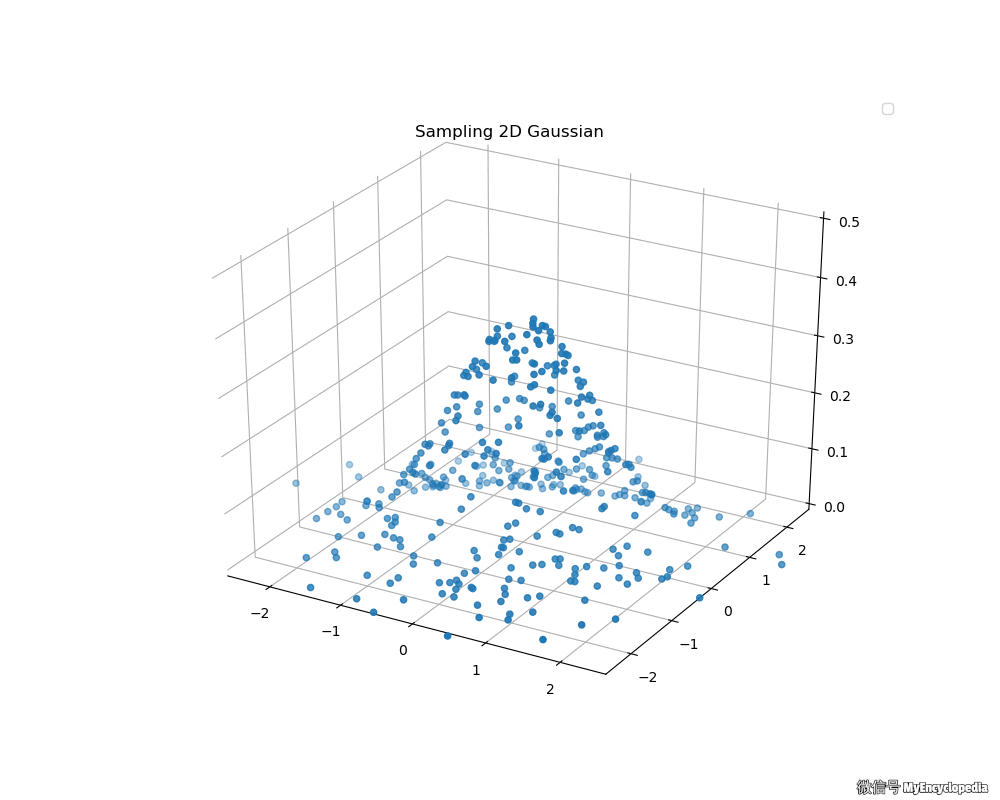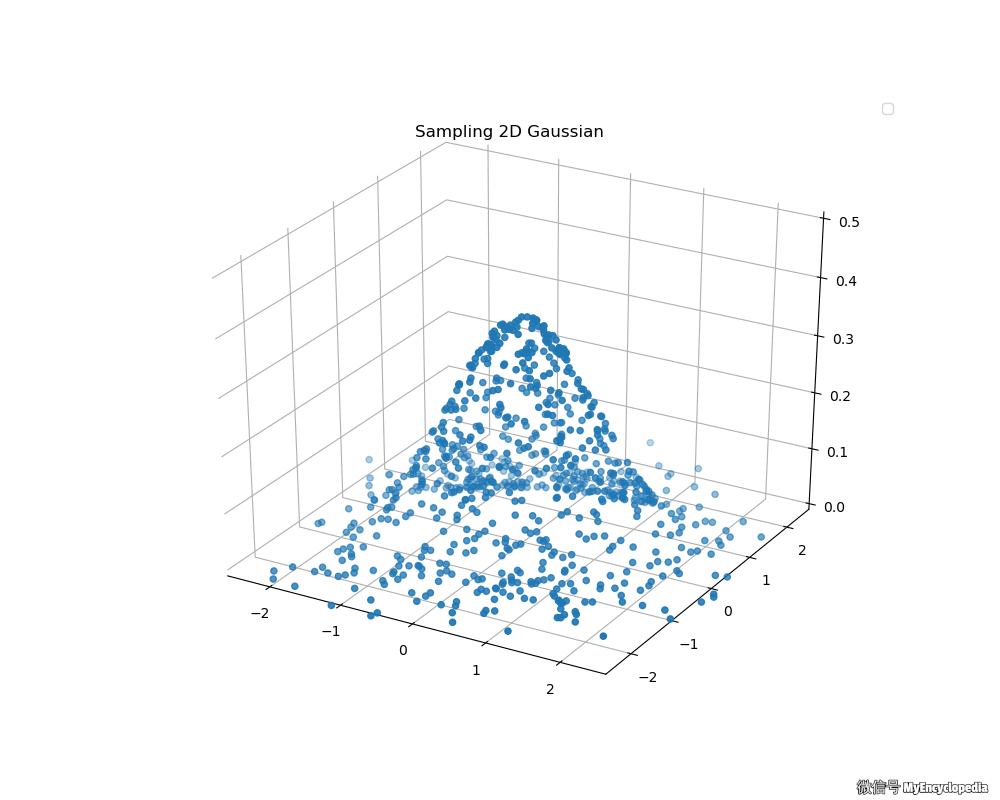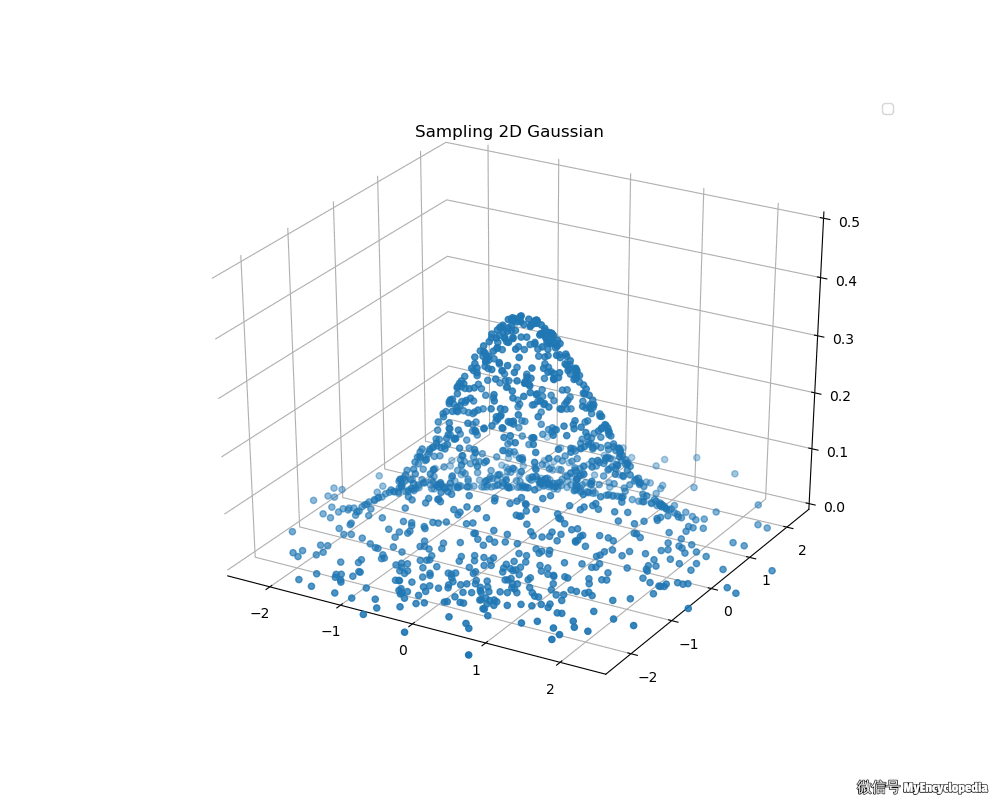
用图来理解这两条性质就是,对于下图的二维正态分布 $ x = [x_1, x_2]^T $,单独的 \(x_1\) 和 \(x_2\) 都服从一维正态分布。
条件概率 \(p(x_2|x_1 \approx1)\) 的PDF 对应图中的红线,显然也是一维正态分布。
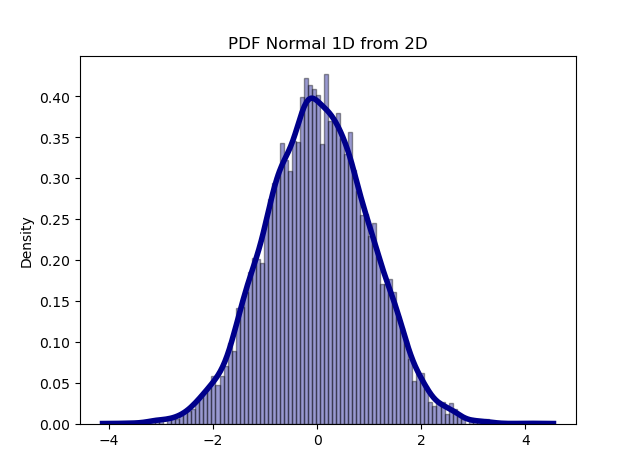
写一段简单的代码验证二维正态分布的单个分量服从正态分布。
代码中,我们用np.random.normal生成了 10000
个服从二维正态分布的 x, y 点,然后我们丢弃 y,只保留 x,并画出 10000 个
x 的分布。
1 | def plot_normal_1d(): |
虽然无法直接用逆变换方法生成一维正态分布,但我们却能通过先生成二维的正态分布,利用上面一节的性质,生成一维正态分布。
而 Box-Muller 就是巧妙生成二维正态分布样本点的方法。
首先,我们来看看二维正态分布可以认为是两个维度是独立的,每个维度都是正态分布。此时,其 PDF 可以写成两个一维正态分布 PDF 的乘积。
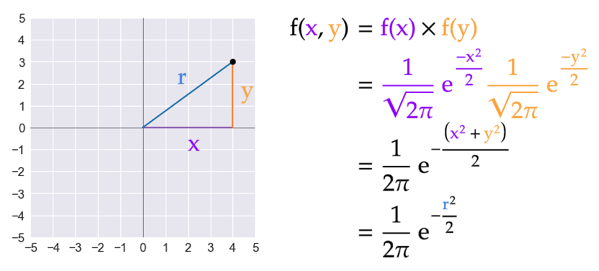
这种写法表明,二维正态分布仅用一个 r 向量就可以充分表达。注意,r 是向量,不仅有大小还有角度,有两个分量。这两个分量本质上是独立的,这就是 Box-Muller 方法的巧妙之处。也就是,Box-Muller 通过角度和半径大小两个分量的独立性分别单独生成并转换成 (x, y) 对。
角度分量是在 \(2\pi\) 范围均匀采样,这一点比较直觉好理解。
再来看看半径分量 r。我们令 \[ s = {r^2 \over 2} \Longrightarrow r = \sqrt{2s} \]
则 s 服从指数分布 \(\lambda=1\) 。
不信么?我们不妨来做个模拟实验,下图是模拟 10000次二维正态分布 (x, y) 点后转换成 s 的分布。
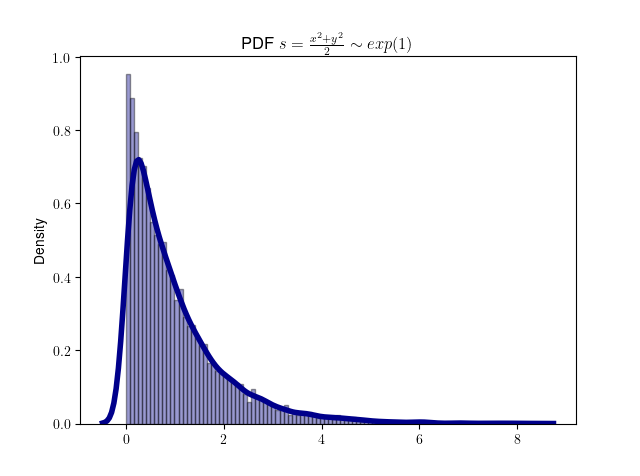
模拟和plot 代码如下
1 | def plot_r_squared(): |
确信了 s 符合指数分布,根据指数分布的 PDF,可以推出二维正态 PDF中的 $ e{-r2/2}$ 也符合指数分布,即 \[ s \sim \exp(1) \Longrightarrow e^{-r^2/2} \sim \exp(1) \]
至此,总结一下Box-Muller方法。我们视二维正态分布PDF为独立两部分的乘积,第一部分是在 \(2\pi\) 范围中的均匀分布,代表了二维平面中的角度 \(\theta\),第二部分为 \(\lambda=1\) 的指数分布,代表半径大小。
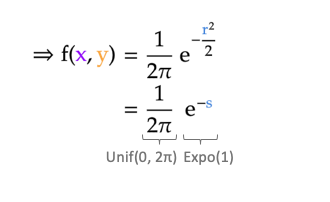
Box-Muller 方法通过两个服从 [0, 1] 均匀分布的样本 u1和u2,转换成独立的角度和半径样本,具体过程如下
生成 [0, 1] 的均匀分布 u1,利用逆变换采样方法转换成 exp(1) 样本,此为二维平面点半径 r
生成 [0, 1] 的均匀分布 u2,乘以 \(2\pi\),即为样本点的角度 \(\theta\)
将 r 和 \(\theta\) 转换成 x, y 坐标下的点。
理解了整个过程的意义,下面的代码就很直白。
1 | def normal_box_muller(): |
接下来,我们来看看 Box-Muller 法生成的二维标准正态分布动画吧
Box-Muller 方法还有一种形式,称为极坐标形式,属于拒绝采样方法。
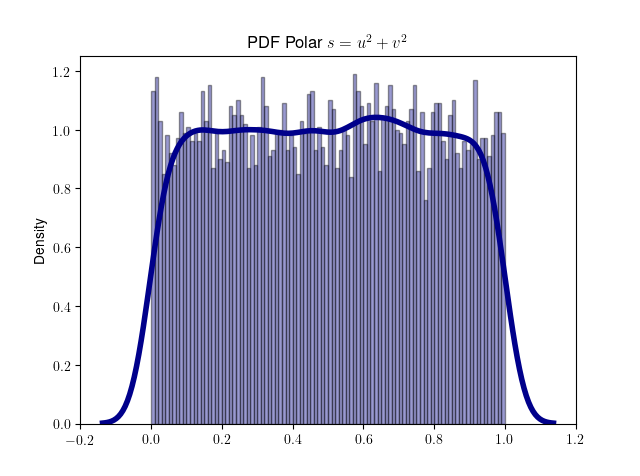
分别生成 [0, 1] 均匀分布 u 和 v。令 \(s = r^2 = u^2 + v^2\)。如果 s = 0或 s ≥ 1,则丢弃 u 和 v ,并尝试另一对 (u , v)。因为 u 和 v 是均匀分布的,并且因为只允许单位圆内的点,所以 s 的值也将均匀分布在开区间 (0, 1) 中。注意,这里的 s 的意义虽然也为半径,但不同于基本方法中的 s。这里 s 取值范围为 (0, 1) ,目的是通过 s 生成指数分布,而基本方法中的 s 取值范围为 [0, +∞],表示二维正态分布 PDF 采样点的半径。复用符号 s 的原因是为了对应维基百科中关于基本方法和极坐标方法的数学描述。
我们用代码来验证 s 服从 (0, 1) 范围上的均匀分布。
1 | def gen_polar_s(): |
若将 $s = R^2 uniform(0, 1) $ 看成是基本方法中的 u1,就可以用同样的方式转换成指数分布,用以代表二维PDF的半径。
同时,根据下图,\(\cos \theta\) 和 \(\sin \theta\) 可以直接用 u, v, R 表示出来,并不需要通过三角函数显示计算出 \(\theta\)。有了半径, \(\cos \theta\) 和 \(\sin \theta\) ,则可以直接计算出 x, y 坐标,(下面用 \(z_0, z_1\) 代替 \(x, y\))。
![]()
\[ z_{0}=\sqrt{-2 \ln U_{1}} \cos \left(2 \pi U_{2}\right)=\sqrt{-2 \ln s}\left(\frac{u}{\sqrt{s}}\right)=u \cdot \sqrt{\frac{-2 \ln s}{s}} \]
\[ z_{1}=\sqrt{-2 \ln U_{1}} \sin \left(2 \pi U_{2}\right)=\sqrt{-2 \ln s}\left(\frac{v}{\sqrt{s}}\right)=v \cdot \sqrt{\frac{-2 \ln s}{s}} \]
同样,Box-Muller 极坐标方法的代码和公式一致。
1 | def normal_box_muller_polar(): |
极坐标方法与基本方法的不同之处在于它是一种拒绝采样。因此,它会丢弃一些生成的随机数,但可能比基本方法更快,因为它计算更简单:避免使用昂贵的三角函数,并且在数值上更稳健。极坐标方法丢弃了生成总输入对的 1 − π /4 ≈ 21.46%,即需要 4/ π ≈ 1.2732 个输入随机数,输出一个随机采样。
在这篇文章中,我们从一道LeetCode 470 题目出发,通过系统地思考,引出拒绝采样(Reject Sampling)的概念,并探索比较三种拒绝采样地解法;接着借助状态转移图来定量计算采样效率;最后,我们利用同样的方法来解一道稍微复杂些的经典抛硬币求期望的统计面试题目。
已有方法 rand7 可生成 1 到 7 范围内的均匀随机整数,试写一个方法 rand10 生成 1 到 10 范围内的均匀随机整数。
不要使用系统的 Math.random() 方法。
思考
rand7()调用次数的 期望值 是多少 ?
你能否尽量少调用 rand7() ?
我们已有 rand7() 等概率生成了 [1, 7] 中的数字,我们需要等概率生成 [1, 10] 范围内的数字。第一反应是调用一次rand7() 肯定是不够的,因为覆盖的范围不够。那么,就需要至少2次调用 rand7() 才能生成一次 rand10(),但是还要保证 [1, 10] 的数字生成概率相等,这个是难点。 现在我们先来考虑反问题,给定rand10() 生成 rand7()。这个应该很简单,调用一次 rand10() 得到 [1, 10],如果是 8, 9, 10 ,则丢弃,重新开始,否则返回。想必大家都能想到这个朴素的方法,这种思想就是统计模拟中的拒绝采样(Reject Sampling)。
有了上面反问题的思考,我们可能会想到,rand7() 可以生成 rand5(),覆盖 [1, 5]的范围,如果将区间 [1, 10] 分成两个5个值的区间 [1, 5] 和 [6, 10],那么 rand7() 可以通过先等概率选择区间 [1, 5] 或 [6, 10],再通过rand7() 生成 rand5()就可以了。这个问题就等价于先用 rand7() 生成 rand2(),决定了 [1, 5] 还是 [6, 10],再通过rand7() 生成 rand5() 。
我们来实现这种解法。下图为调用两次 rand7() 生成 rand10 数值的映射关系:横轴表示第一次调用,1,2,3决定选择区间 [1, 5] ,4,5,6选择区间 [6, 10]。灰色部分表示结果丢弃,重新开始 (注,若第一次得到7无需再次调用 rand7())。
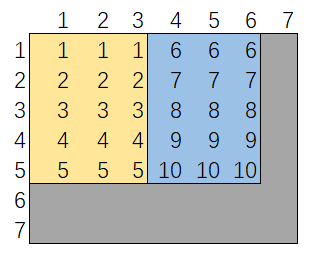
有了上图,我们很容易写出如下 AC 代码。
1 | # AC |
从提交的结果来看,第一种解法慢于多数解法。原因是我们的调用 rand7() 的采样效率比较低,第一次有 1/7 的概率结果丢弃,第二次有 2/7的概率被丢弃。
如何在第一种解法的基础上提高采样效率呢?直觉告诉我们一种做法是降低上述 7x7 表格中灰色格子的面积。此时,会想到我们通过两次 rand7() 已经构建出来 rand49()了,那么再生成 rand10() 也规约成基本问题了。
下图为 rand49() 和 rand10() 的数字对应关系。
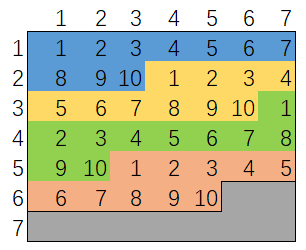
实现代码比较简单。注意,while True 可以去掉,用递归来代替。
1 | # AC |
上面的提交结果发现标准解法在运行时间上有了不少提高,处于中等位置。我们继续思考,看看能否再提高采样效率。
观察发现,rand49() 有 9/49 的概率,生成的值被丢弃,原因是 [41, 49] 只有 9 个数,不足10个。倘若此时能够将这种状态保持下去,那么只需再调用一次 rand7() 而不是从新开始情况下至少调用两次 rand7(), 就可以得到 rand10()了。也就是说,当 rand49() 生成了 [41, 49] 范围内的数的话等价于我们先调用了一次 rand9(),那么依样画葫芦,我们接着调用 rand7() 得到了 rand63()。63 分成了6个10个值的区间后,剩余 3 个数。此时,又等价于 rand3(),循环往复,调用了 rand7() 得到了 rand21(),最后若rand21() 不幸得到21,等价于 rand1(),此时似乎我们走投无路,只能回到最初的状态,一切从头再来了。
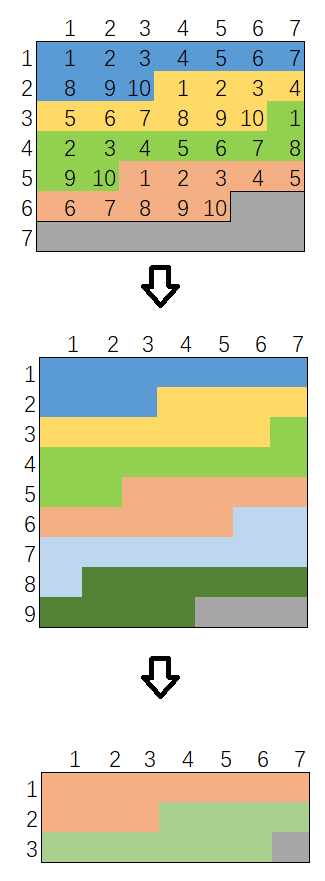
改进算法代码如下。注意这次击败了 92.7%的提交。
1 | # AC |
通过代码提交的结果和大致的分析,我们已经知道三个解法在采样效率依次变得更快。现在我们来定量计算这三个解法。
我们考虑生成一个 rand10() 平均需要调用多少次 rand7(),作为采样效率的标准。
一种思路是可以通过模拟方法,即将上述每个解法模拟多次,然后用总的 rand7() 调用次数除以 rand10() 的生成次数即可。下面以解法三为例写出代码
1 | # The rand7() API is already defined for you. |
运行代码,发现解法三的采样效率稳定在 2.19。
为了精确计算三个解法的采样效率,我们通过代码得到对应的状态转移图来帮助计算。
例如,解法一可以对应到下图:初始状态 Start 节点中的 +2 表示经过此节点会产生 2次 rand7() 的代价。从 Start 节点有 40/49 的概率到达被接受状态 AC,有 9/49 概率到达拒绝状态 REJ。REJ 需要从头开始,则用虚线表示重新回到 Start节点,也就是说 REJ 的代价等价于 Start。注意,从某个节点出发的所有边之和为1。
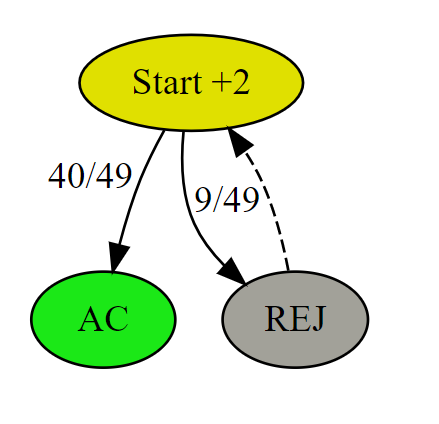
有了上述状态转移关系图,我们令初始状态的平均代价为 \(C_2\),则可以写成递归表达式,因为其中 REJ 的代价就是 \(C_2\),即
\[ C_2 = 2 + (\frac{40}{49}\cdot0 + \frac{9}{49} C_2) \]
解得 \(C_2\)
\[ C_2 = 2.45 \]
同样的,对于另外两种解法,虽然略微复杂,也可以用同样的方法求得。
解法一的状态转移图为
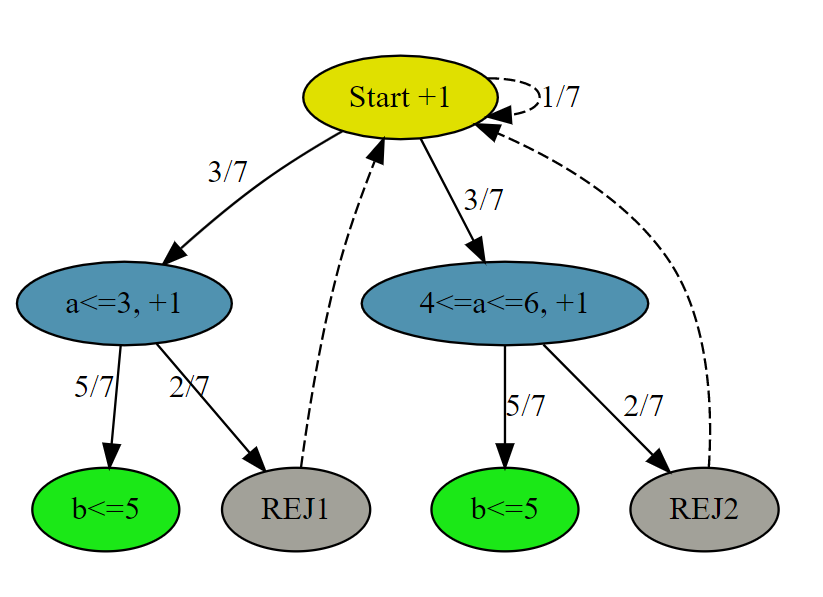
递归方程表达式为
\[ C_1 = 1+\frac{3}{7} \cdot (1+\frac{5}{7} \cdot 0 + \frac{2}{7} \cdot C_1) \cdot2+ \frac{1}{7} \cdot (C_1) \]
解得 \(C_1\)
\[ C_1 = \frac{91}{30} \approx 3.03 \]
最快的解法三状态转移图为
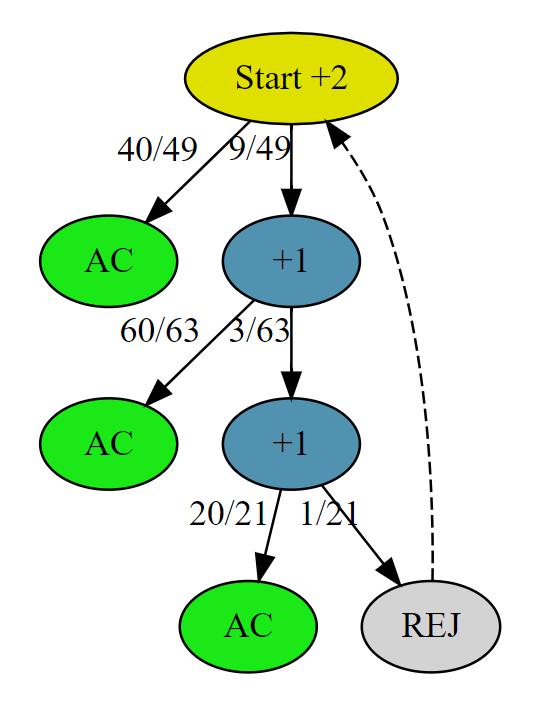
递归方程表达式为
\[ C_3 = 2+\frac{40}{49} \cdot 0 + \frac{9}{49} (1+\frac{60}{63} \cdot 0 + \frac{3}{63} \cdot (1+\frac{20}{21} \cdot 0 + \frac{1}{21} \cdot C_3)) \]
解得 \(C_3\) \[ C_3 = \frac{329}{150} \approx 2.193 \]
至此总结一下,三个解法的平均代价为 \[ C_1 \approx 3.03 > C_2 = 2.45 > C_3 \approx 2.193 \] 这些值和我们通过模拟得到的结果一致。
至此,LeetCode 470 我们已经分析透彻。现在,我们已经可以很熟练的将此类拒绝采样的问题转变成有概率的状态转移图,再写成递推公式去求平均采样的代价(即期望)。这里,如果大家感兴趣的话不妨再来看一道略微深入的经典统计概率求期望的题目。
问题:给定一枚抛正反面概率一样的硬币,求连续抛硬币直到两个正面(正面记为H,两个正面HH)的平均次数。例如:HTTHH是一个连续次数为5的第一次出现HH的序列。
分析问题画出状态转移图:我们令初始状态下得到第一个HH的平均长度记为 S,那么下一次抛硬币有 1/2 机会是 T,此时状态等价于初始状态,另有 1/2 机会是 H,我们记这个状态下第一次遇见HH的平均长度为 H(下图蓝色节点)。从此蓝色节点出发,当下一枚硬币是H则结束,是T是返回初始状态。于是构建出下图。
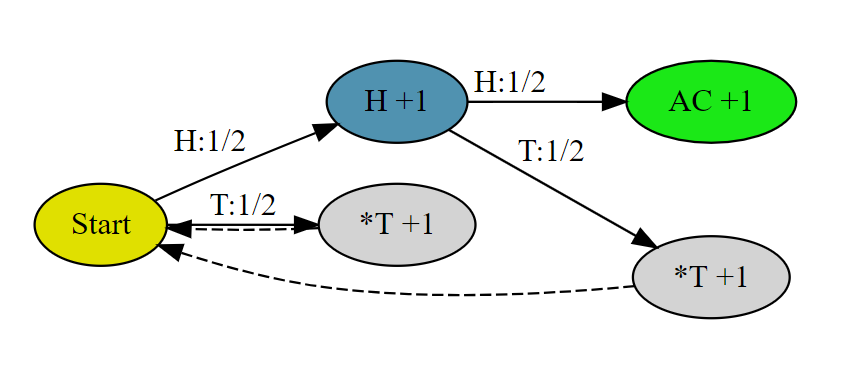
这个问题稍微复杂的地方在于我们有两个未知状态互相依赖,但问题的本质和方法是一样的,分别从 S 和 H 出发考虑状态的概率转移,可以写成如下两个方程式:
\[ \left\{ \begin{array}{c} S =&\frac{1}{2} \cdot(1+H) + \frac{1}{2} \cdot(1+S) \\ H =&\frac{1}{2} \cdot 1 + \frac{1}{2} \cdot(1+S) \end{array} \right. \]
解得
\[ \left\{ \begin{array}{c} H= 4 \\ S = 6 \end{array} \right. \]
因此,平均下来,需要6次抛硬币才能得到 HH,这个是否和你直觉的猜测一致呢?
这个问题还可以有另外一问,可以作为思考题让大家来练习一下:第一次得到 HT 的平均次数是多少?这个是否和 HH 一样呢?
本篇是深度强化学习动手系列文章,自MyEncyclopedia公众号文章深度强化学习之:DQN训练超级玛丽闯关发布后收到不少关注和反馈,这一期,让我们实现目前主流深度强化学习算法PPO来打另一个红白机经典游戏1942。
相关文章链接如下:
红白机游戏环境可以由OpenAI Retro来模拟,OpenAI Retro还在 Gym 集成了其他的经典游戏环境,包括Atari 2600,GBA,SNES等。
不过,受到版权原因,除了一些基本的rom,大部分游戏需要自行获取rom。
环境准备部分相关代码如下
1 | pip install gym-retro |
1 | python -m retro.import /path/to/your/ROMs/directory/ |
在创建 retro 环境时,可以在retro.make中通过参数use_restricted_actions指定 action space,即按键的配置。
1 | env = retro.make(game='1942-Nes', use_restricted_actions=retro.Actions.FILTERED) |
可选参数如下,FILTERED,DISCRETE和MULTI_DISCRETE 都可以指定过滤的动作,过滤动作需要通过配置文件加载。
1 | class Actions(Enum): |
DISCRETE和MULTI_DISCRETE 是 Gym 里的 Action概念,它们的基类都是gym.spaces.Space,可以通过 sample()方法采样,下面具体一一介绍。
1 | from gym.spaces import Discrete |
输出是
1 | 3 |
1 | from gym.spaces import Box |
输出是
1 | [[-0.7538084 0.96901214 0.38641307 -0.05045208] |
1 | from gym.spaces import MultiBinary |
输出是
1 | [[1 0] |
1 | from gym.spaces import MultiDiscrete |
输出是
1 | [2 1 0] |
1 | from gym.spaces import * |
输出是
1 | (array([ 0.22640526, 0.75286865, -0.6309239 ], dtype=float32), 0, 1) |
1 | from gym.spaces import * |
输出是
1 | OrderedDict([('position', 1), ('velocity', 1)]) |
了解了 gym/retro 的动作空间,我们来看看1942的默认动作空间
1 | env = retro.make(game='1942-Nes') |
1 | The size of action is: (9,) |
表示有9个 Discrete 动作,包括 start, select这些控制键。
从训练1942角度来说,我们希望指定最少的有效动作取得最好的成绩。根据经验,我们知道这个游戏最重要的键是4个方向加上 fire 键。限定游戏动作空间,官方的做法是在创建游戏环境时,指定预先生成的动作输入配置文件。但是这个方式相对麻烦,我们采用了直接指定按键的二进制表示来达到同样的目的,此时,需要设置 use_restricted_actions=retro.Actions.FILTERED。
下面的代码限制了6种按键,并随机play。
1 | action_list = [ |
来看看其游戏效果,全随机死的还是比较快。
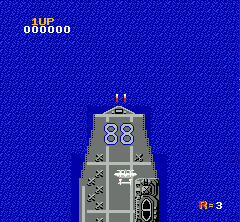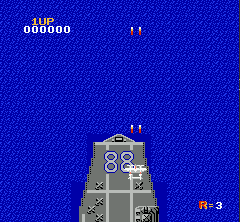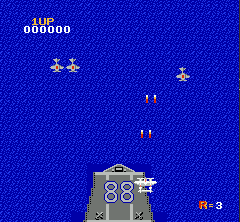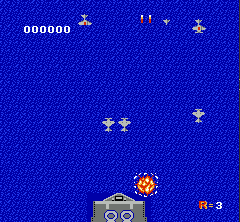
一般对于通过屏幕像素作为输入的RL end-to-end训练来说,对图像做预处理很关键。因为原始图像较大,一方面我们希望能尽量压缩图像到比较小的tensor,另一方面又要保证关键信息不丢失,比如子弹的图像不能因为图片缩小而消失。另外的一个通用技巧是将多个连续的frame合并起来组成立体的frame,这样可以有效表示连贯动作。
下面的代码通过 pipeline 将游戏每帧原始图像从shape (224, 240, 3) 转换成 (4, 84, 84),也就是原始的 width=224,height=240,rgb=3转换成 width=84,height=240,stack_size=4的黑白图像。具体 pipeline为
MaxAndSkipEnv:每两帧过滤一帧图像,减少数据量。
FrameDownSample:down sample 图像到指定小分辨率 84x84,并从彩色降到黑白。
FrameBuffer:合并连续的4帧,形成 (4, 84, 84) 的图像输入
1 | def build_env(): |
观察图像维度变换
1 | env = retro.make(game='1942-Nes', use_restricted_actions=retro.Actions.FILTERED) |
确保shape 从 (224, 240, 3) 转换成 (4, 84, 84)
1 | Initial shape: (224, 240, 3) |
FrameDownSample实现如下,我们使用了 cv2 类库来完成黑白化和图像缩放
1 | class FrameDownSample(ObservationWrapper): |
MaxAndSkipEnv,每两帧过滤一帧
1 | class MaxAndSkipEnv(Wrapper): |
FrameBuffer,将最近的4帧合并起来
1 | class FrameBuffer(ObservationWrapper): |
最后,visualize 处理后的图像,同样还是在随机play中,确保关键信息不丢失
1 | def random_play_preprocessed(env, action_list, sleep_seconds=0.01): |
matplotlib 动画输出

Actor 和 Critic 模型相同,输入是 (4, 84, 84) 的图像,输出是 [0, 5] 的action index。
1 | class Actor(nn.Module): |
先计算 \(r_t(\theta)\),这里采用了一个技巧,对 \(\pi_\theta\) 取 log,相减再取 exp,这样可以增强数值稳定性。
1 | dist = self.actor_net(state) |
surr1 对应PPO论文中的 \(L^{CPI}\)
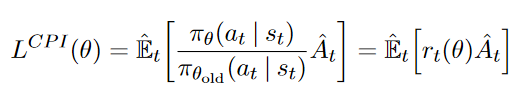
然后计算 surr2,对应 \(L^{CLIP}\) 中的 clip 部分,clip可以由 torch.clamp 函数实现。\(L^{CLIP}\) 则对应 actor_loss。
1 | surr2 = torch.clamp(ratio, 1.0 - self.clip_param, 1.0 + self.clip_param) * advantage |
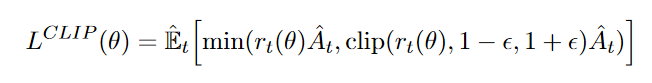
最后,计算总的 loss \(L_t^{CLIP+VF+S}\),包括 actor_loss,critic_loss 和 policy的 entropy。
1 | entropy = dist.entropy().mean() |
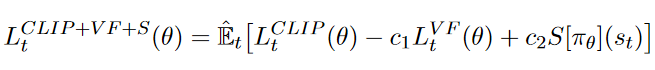
上述完整代码如下
1 | for _ in range(self.ppo_epoch): |
补充一下 GAE 的计算,advantage 根据公式
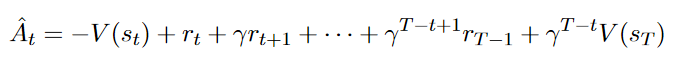
可以转换成如下代码
1 | def compute_gae(self, next_value): |
外层调用代码基于随机 play 的逻辑,agent.act()封装了采样和 forward prop,agent.step() 则封装了 backprop 和参数学习迭代的逻辑。
1 | for i_episode in range(start_epoch + 1, n_episodes + 1): |
让我们来看看学习的效果吧,注意我们的飞机学到了一些关键的技巧,躲避子弹;飞到角落尽快击毙敌机;一定程度预测敌机出现的位置并预先走到位置。
导读:极大似然估计(MLE) 是统计机器学习中最基本的概念,但是能真正全面深入地理解它的性质和背后和其他基本理论的关系不是件容易的事情。极大似然估计和以下概念都有着紧密的联系:随机变量,无偏性质(unbiasedness),一致估计(consistent),asymptotic normality,最优化(optimization),Fisher Information,MAP(最大后验估计),KL-Divergence,sufficient statistics等。在众多阐述 MLE 的文章或者课程中,总体来说都比较抽象,注重公式推导。本系列文章受3blue1brown 可视化教学的启发,坚持从第一性原理出发,通过数学原理结合模拟和动画,深入浅出地让读者理解极大似然估计。
相关链接
我们来思考这个老套问题,考虑手上有一枚硬币,旋转(抛)硬币得到正反面的概率固定(令正面概率为\(\theta^{\star}\))但未知,我们如何能通过实验推测出 \(\theta^{\star}\)

朴素的想法是,不断尝试抛硬币,随着次数 n 的增多,正面的比例会趋近于 \(\theta^{\star}\)
对应到数学形式上,令我们对于 \(\theta^{\star}\) 的估计为 \(\hat{\theta}_{n}\),则希望 \[ \hat{\theta}_n = {n_{head} \over n} \to \theta^{\star} \text{ as n } \to \infty \]
假设我们尝试了n次,每次的结果为 \(x_i\),\(x_i\)为1(正面) 或 0(反面)。比如试了三次的结果是 [1, 0, 1],则 \(x_1=1, x_2=0, x_3=1\)。一般,我们将观察到的数据写成向量形式
\[X=[x_1, x_2, x_3]^T=[1, 0, 1]^{T}\]
我们知道硬币的正反结果符合伯努利分布,也就是 \[ \begin{align*} P_{ber}(x;\theta) = \left\lbrace \begin{array}{r@{}l} \theta &\text{ if x=1} \\ 1-\theta &\text{ if x=0} \end{array} \right. \end{align*} \]
因为 x 只有0,1两种取值,因此上式也可以写成等价如下的不含条件分支的形式 \[ P_{ber} = \theta^x \cdot (1-\theta)^x \]
假设 \(\theta^{\star} = 0.7\),如果做 n=10 次试验,结果应该比较接近7个1,3个0。
下面我们来模拟一下 n=10,看看结果如何。
下面代码的实现上我们直接使用了pytorch 内置的 bernoulli 函数生成 n 个随机变量实例
1 | def gen_coins(theta, n=1): |
让我们来做三次 n=10 的试验
1 | for i in range(3): |
能发现 7个1,3个0 确实是比较可能的结果。
1 | trial 0 |
直觉告诉我们,当 \(\theta^{\star}=0.7\) 时,根据 $P_{ber}(x;) $,7个1,3个0 出现的概率应该是最大,6个1,4个0 或者 8个1,2个0 这两种情况出现概率稍小,其他的情况概率更小。通过基本概率和伯努利公式,重复 n 次试验 1和0出现的概率可以由下面公式算出。(注:7个1,3个0不是单一事件,需要乘以组合数算出实际概率)
\[ P_{X} = \theta^{heads} \cdot (1-\theta)^{tails} \cdot {n \choose heads} \]
| P(X) | |
|---|---|
| head=0 | 0.000006 |
| head=1 | 0.000138 |
| head=2 | 0.000032 |
| head=3 | 0.001447 |
| head=4 | 0.036757 |
| head=5 | 0.102919 |
| head=6 | 0.200121 |
| head=7 | 0.266828 |
| head=8 | 0.233474 |
| head=9 | 0.121061 |
| head=10 | 0.028248 |
画出图看的很明显,1出现7次的概率确实最大。
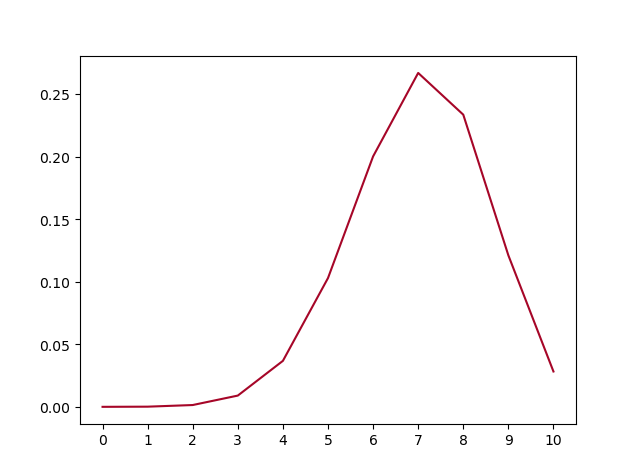
回到我们的问题,我们先假定 \(\theta^{\star} = 0.7\) 的硬币做 n=10 次试验的结果就是 7个1,3个0,或者具体序列为 [1, 0, 0, 1, 0, 1, 1, 1, 1, 1]。那么我们希望按照某种方法推测的估计值 \(\hat\theta\) 也为 0.7。
若将这个方法也记做 \(\hat\theta\),它是\(X\) 的函数,即 \(\hat\theta(X=[1, 0, 0, 1, 0, 1, 1, 1, 1, 1]^T)=0.7\)
我们如何构建这个方法呢?很显然,\(X\) 中 1 的个数就可以胜任,\(\hat\theta=\bar X\)。这个方式确实是正确的,后面的文章我们也会证明它是MLE在伯努利分布参数估计时的计算方法。
但是伯努利分布参数估计的问题中是最简单的情况,背后对应的更一般的问题是:假设我们知道某个过程或者实验生成了某种分布 P,但是不知道它的参数 \(\theta\),如何能通过反复的试验来推断 \(\theta\),同时,我们希望随着试验次数的增多,\(\hat\theta\) 能逼近 \(\theta\)。
由于过程是有随机性,试验结果 \(X\) 并不能确定一定是从 \(\hat\theta\) 生成的,因此我们需要对所有 \(\theta\) 打分。对于抛硬币试验来说,我们穷举所有在 [0, 1] 范围内的 \(\theta\),定义它的打分函数 \(f(\theta)\),并且希望我们定义的 \(f(\theta;X=[1, 0, 0, 1, 0, 1, 1, 1, 1, 1]^T)\) 在 \(\theta=0.7\) 时得分最高。推广到一般场景,有如下性质 \[ f(\theta^\star;X) >= f(\theta;X) \]
如此,我们将推测参数问题转换成了优化问题 \[ \hat\theta = \theta^{\star} = \operatorname{argmax}_{\theta} f(\theta; X) = 0.7 \]
一种朴素的想法是,由于 \(\theta^\star=0.7\),因此我们每次的结果应该稍微偏向 1,如果出现了 1,就记0.7分,出现了0,记0.3分,那么我们可以用10个结果的总分来定义总得分,即最大化函数
\[ \begin{equation*} \begin{aligned} &\operatorname{argmax}_{\theta} f(\theta) \\ =& \operatorname{argmax}_{\theta} P(x_1) + P(x_2) + ... + P(x_n) \\ =& \operatorname{argmax}_{\theta} P(x_1|\theta) + P(x_2|\theta) + ... + P(x_n|\theta) \\ =& \operatorname{argmax}_{\theta} \sum P(x_i|\theta) \\ \end{aligned} \end{equation*} \]
很可惜,我们定义的 f 并不符合 \(\theta=0.7\) 时取到最大的原则。下面画出了 \(\theta\) 在 [0, 1] 范围内 f 值,X 固定为 [1, 0, 0, 1, 0, 1, 1, 1, 1, 1]。显然,极值在 0.5 左右。
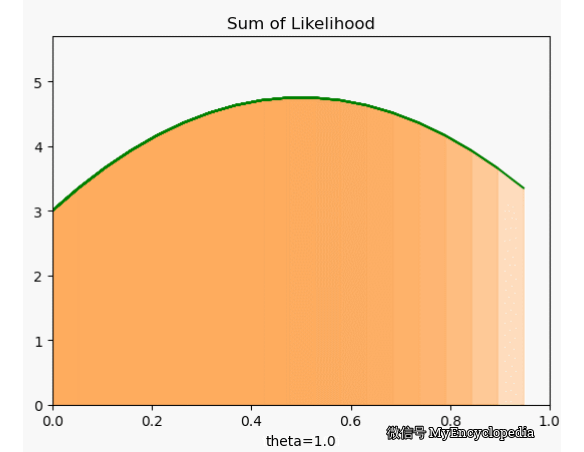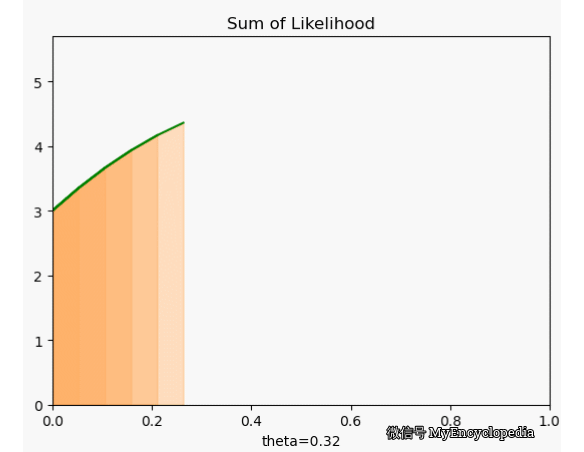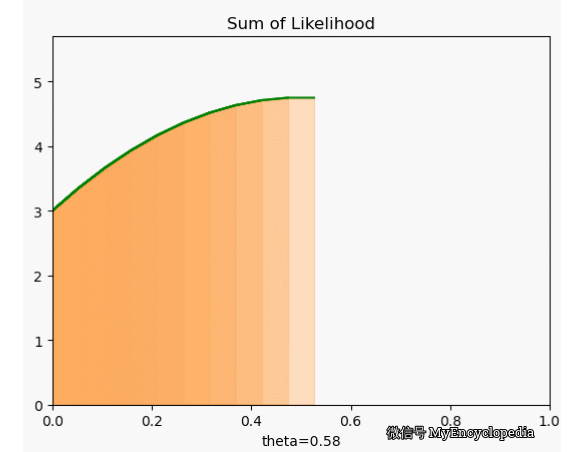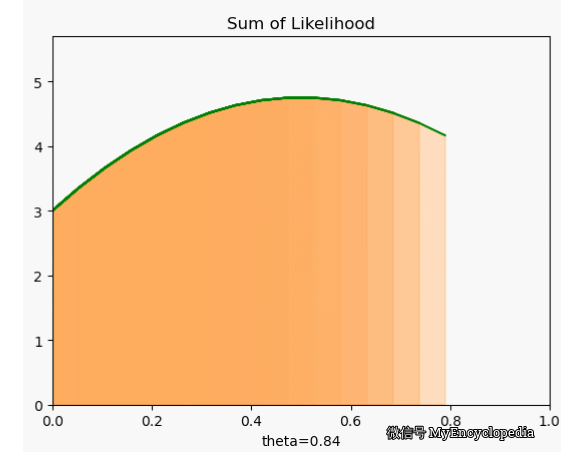
这种对于观察到的变量实例在整个参数空间打分的方法是最大似然方法的雏形。我们将每次试验结果对于不同 \(\theta\) 的打分就是似然函数的概念。
伯努利单个结果的似然函数 \(l(\theta)\) 视为 \(\theta\) 的函数,x视为给定值,它等价于概率质量函数 PMF
\[ l(\theta|x) = \theta^x \cdot (1-\theta)^x \]
有了单个结果的似然函数,我们如何定义 \(f(\theta)\) 呢?我们定义的 \(f(\theta)\) 需要满足,在 \(\theta^\star=0.7\) ,\(n=10\) 的情况下,试验最有可能的结果是 7 个1,3个0,此时 f 需要在 \(\theta=0.7\) 时取到最大值。
极大似然估计(MLE) 为我们定义了合理的 \(f(\theta)\) ,和朴素的想法类似,但是这次用单个结果的似然函数连乘而非连加 \[ L(\theta|X) = l(\theta|x_1) \cdot l(\theta|x_2) \cdot ...l(\theta|x_n) = \prod l(\theta|x_i) \]
我们再来看一下当 $X=[1, 0, 0, 1, 0, 1, 1, 1, 1, 1] $ 时 \(L\) 在 \(\theta\) 空间的取值情况,果然,MLE 能在 0.7时取到最大值。
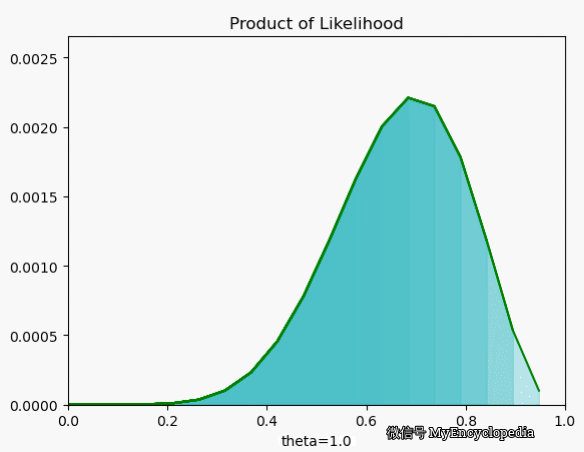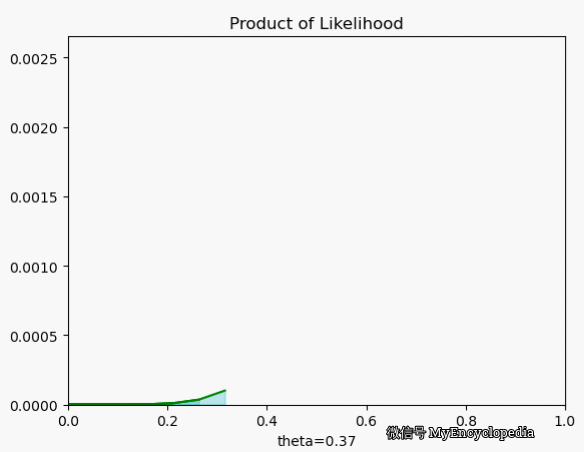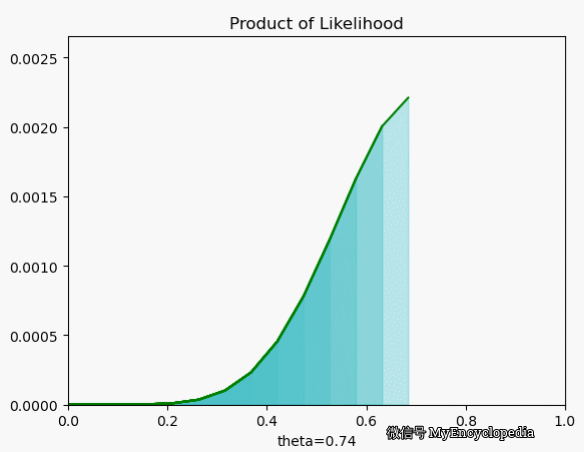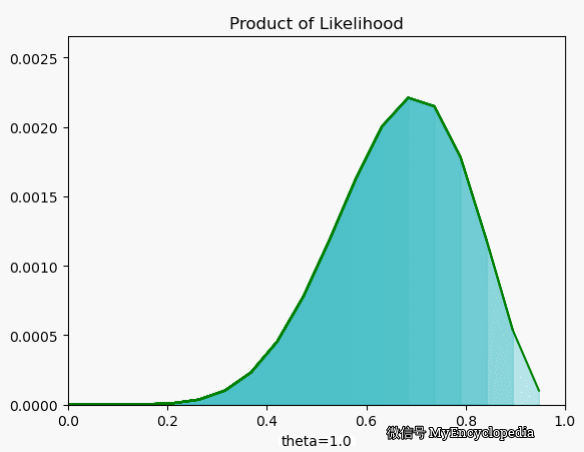
最大似然函数 $_{} L() $ 能让我们找到最可能的 \(\theta\),但现实中,我们一般采用最大其 log 的形式。
\[ \begin{equation*} \begin{aligned} &\operatorname{argmax}_{\theta} \log L(\theta|X) \\ =& \operatorname{argmax}_{\theta} \log [l(\theta|x_1) \cdot l(\theta|x_2) \cdot ... \cdot l(\theta|x_n)] \\ =& \operatorname{argmax}_{\theta} \log l(\theta|x_1) + \log l(\theta|x_2) \cdot ... + \log l(\theta|x_n) \end{aligned} \end{equation*} \]
理论能证明,最大对数似然函数得到的极值等价于最大似然函数。但这么做有什么额外好处呢?
我们先将对数似然函数画出来
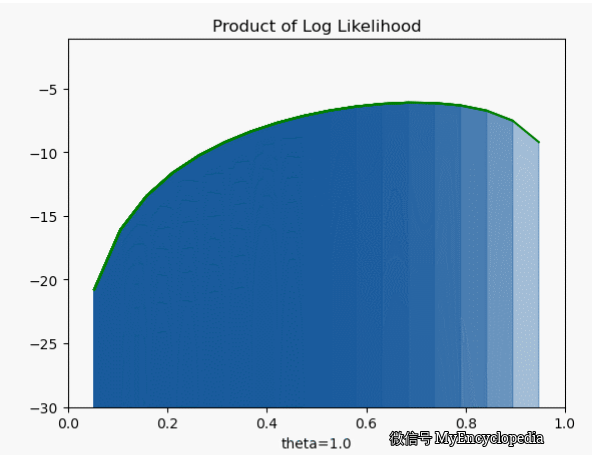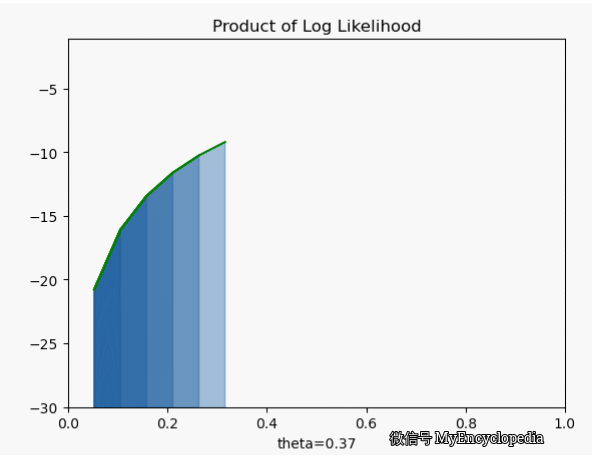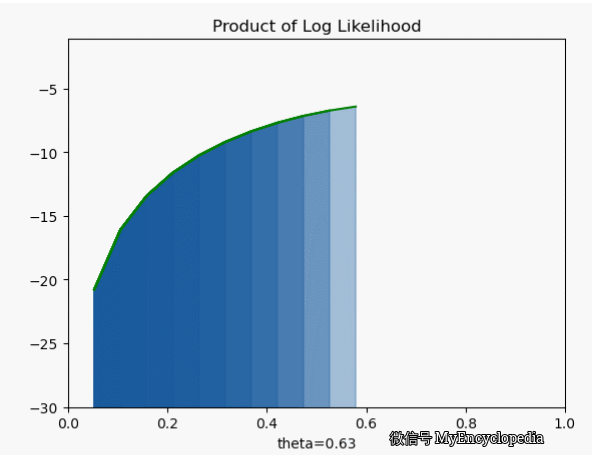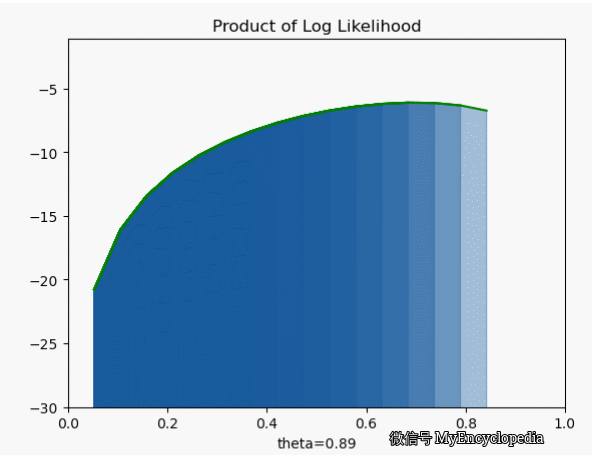
它的极大值也在 0.7,但是我们发现对数似然函数是个 concave 函数。在优化领域,最大化 concave 函数或者最小化 convex 函数可以有非常高效的解法。再仔细看之前的似然函数,它并不是一个 concave 函数。另一个非常重要的好处是,随着 n 的增大,连乘会导致浮点数 underflow,而单个点的对数似然函数的和的形式就不会有这个问题。
就让我们来实践一下,通过 pytorch 梯度上升来找到极值点。
1 | from stats.coin import gen_coins |
一点需要说明的是,在迭代过程中,我们保存最后三个导数的值,当最新的三个导数都很小时就退出迭代。
1 | if all(map(lambda x: abs(x) < 1, recent)) |
运行代码,能发现最大化对数似然函数能很稳定的找到 \(\theta\)。
现在大家对于伯努利MLE有了一定了解,接着,我们来思考一下最大化似然函数方法是否随着观察次数的增多能不断逼近真实的 \(\theta^\star\)呢?
\(\theta^\star=0.7\) 的情况下,我们来这样做试验,第一次做 n=1生成观察数据 \(X_{1}\),第二次做 n=2生成观察数据 \(X_{2}\) \[ X_1,X_2, X_3, ..., X_N \] 对于每个数据集 \(X_i\) 通过最大似然方法求得估计的 \(\hat\theta\) \[ \hat\theta_1=MLE(X_1), \hat\theta_2=MLE(X_2), ..., \hat\theta_N=MLE(X_N) \] 将这些 \(\hat\theta_i\) 画出来,可以看到,随着 \(n \to \infty\),\(\hat\theta_i \to \theta^\star=0.7\)
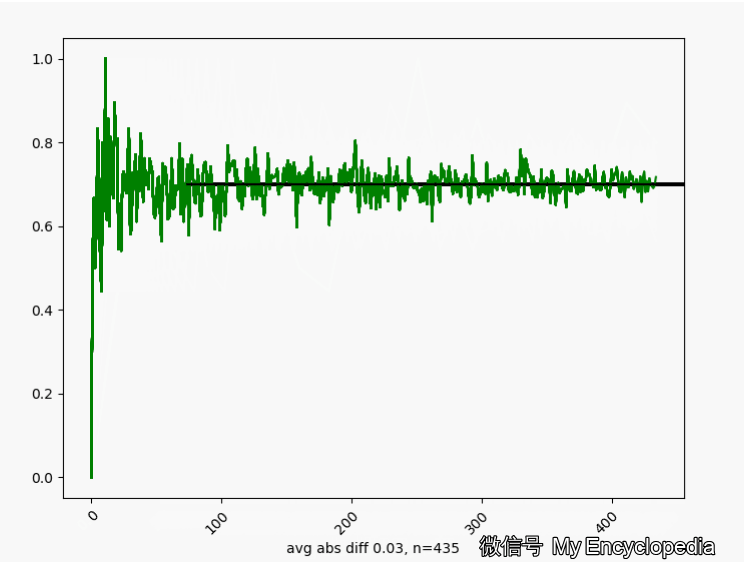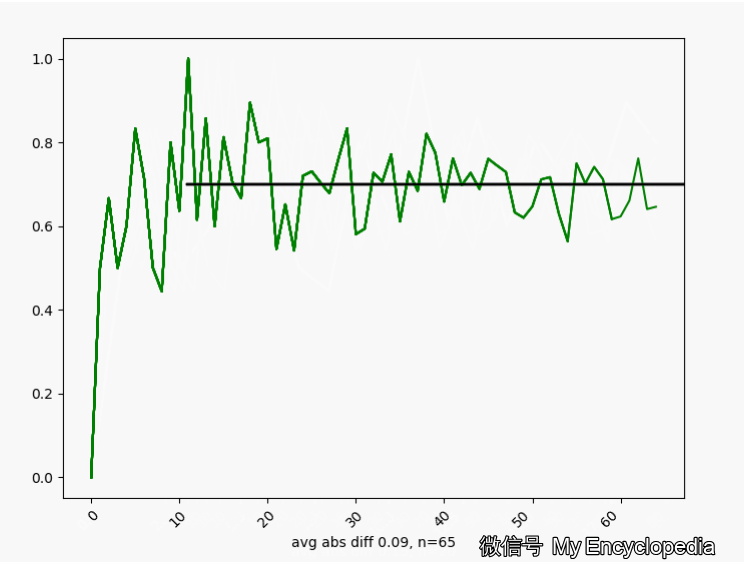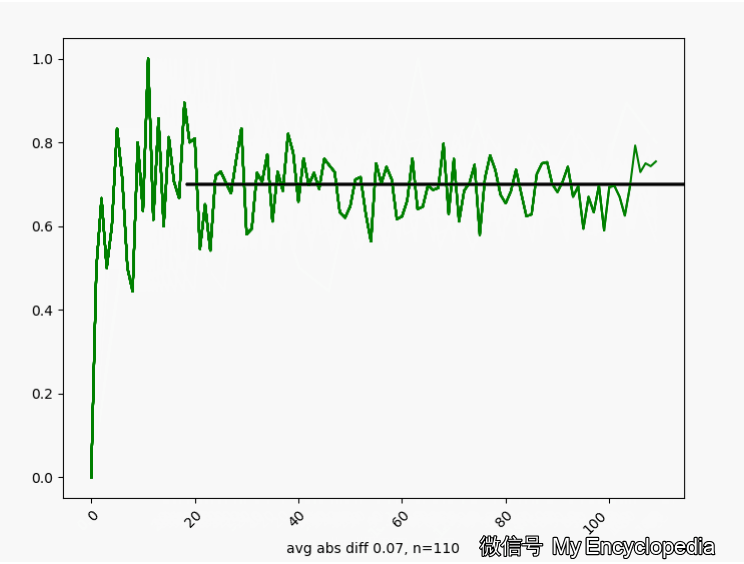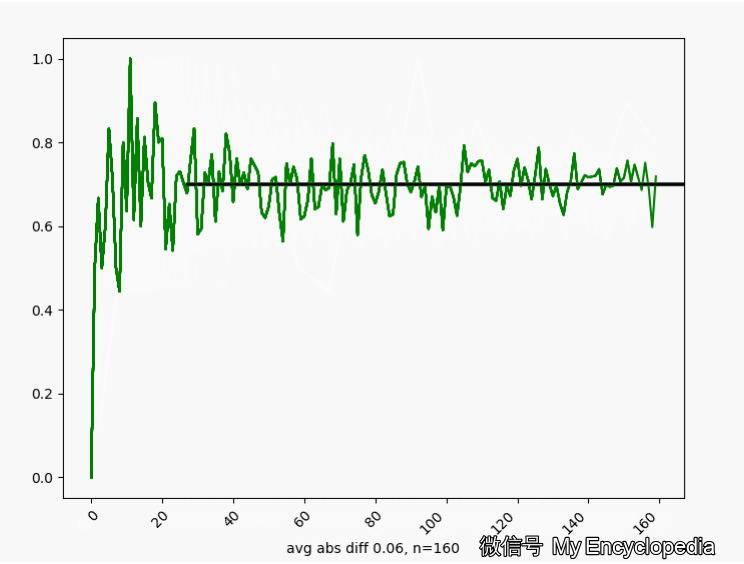
换一个角度来看一下,我们将 \(\hat\theta_i\) 数列按照顺序,离散化后再归一化比例,如下图画出来,红色的柱代表了最新的值 \(\hat\theta\)。可以发现,初始时候,\(\hat\theta\) 在较远离 0.7 的地方出现,随着 n 的增大,出现的位置比较接近 0.7。
我们已经知道 MLE 方法可以通过观察数据推测出最有可能的 \(\hat\theta\),由于观察数据 \(X\) 是伯努利过程产生的,具有随机性,那么 \(\hat\theta\) 可以看成是 \(\theta^\star\) 的随机变量。我们已经通过上面的试验知道随着试验次数的增大,我们的估计会越来越逼近真实值,现在的问题是对于固定的n,\(\hat\theta\) 的方差是多少,它的均值是否是无偏的呢?
带着这样的疑问,我们现在做如下试验:
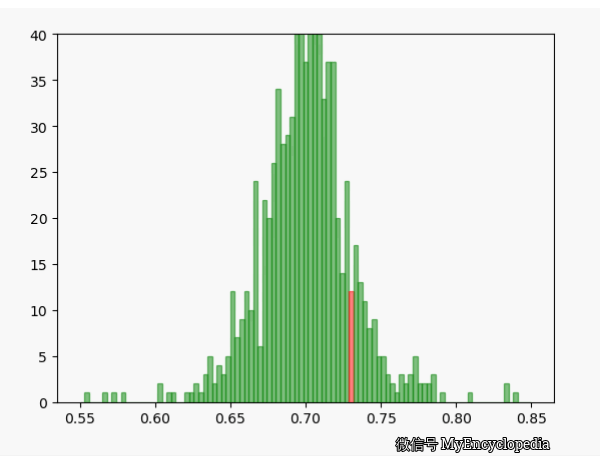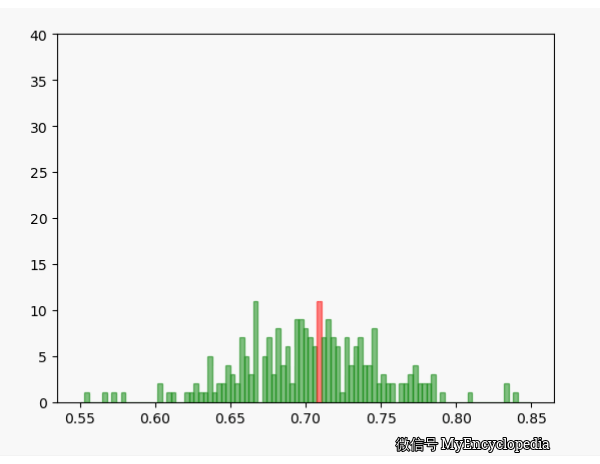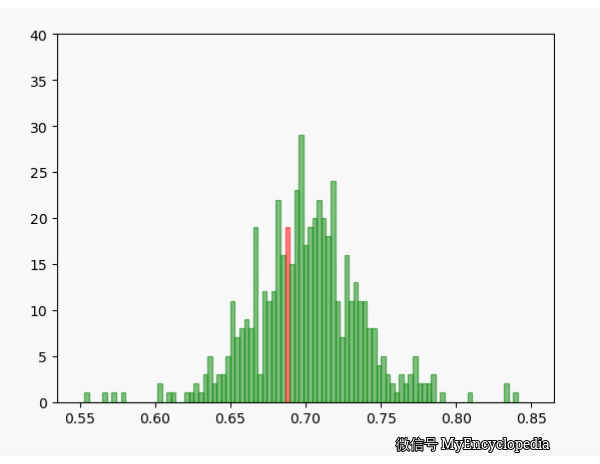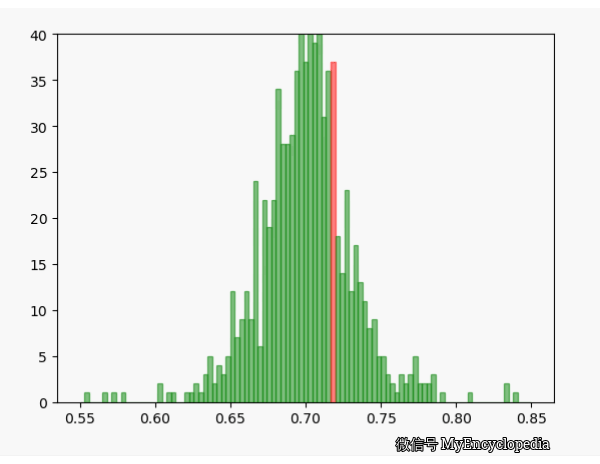
固定 n=10,重复做实验,画出随着次数增多 \(\hat\theta\) 的分布,见图中绿色部分。同样的,红色是 n=80 不断试验的分布变换。
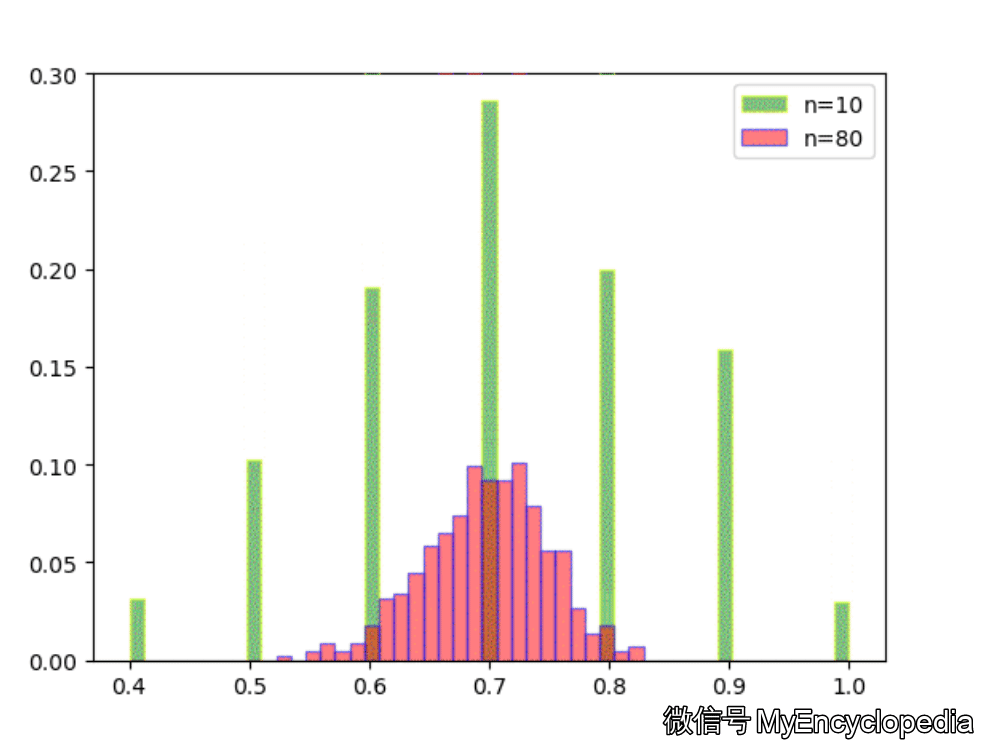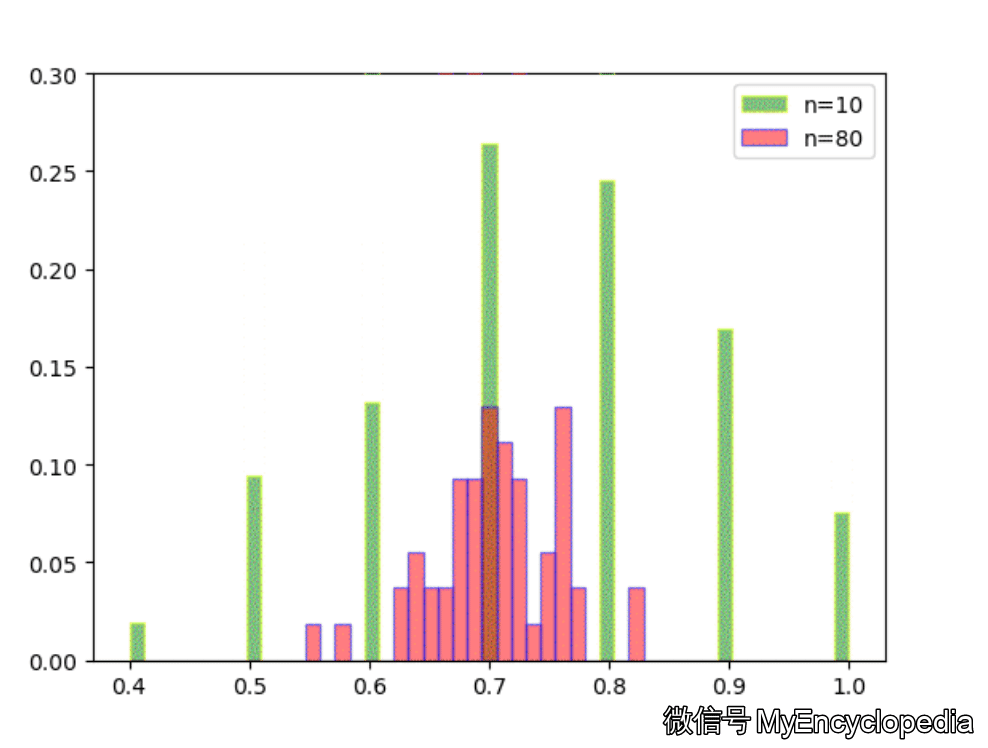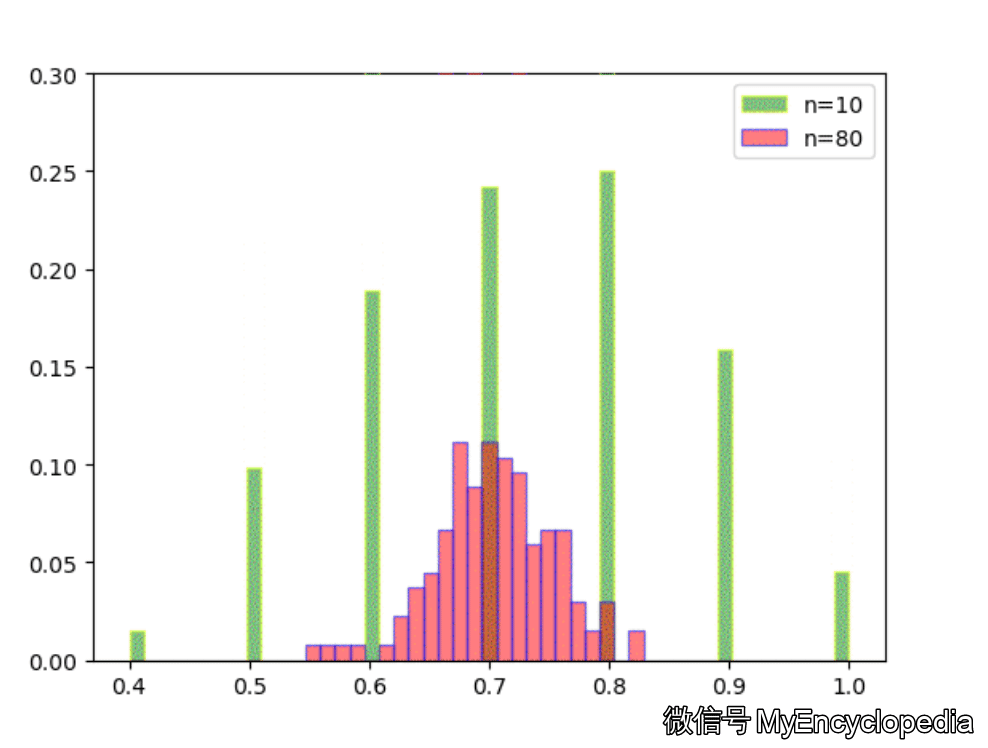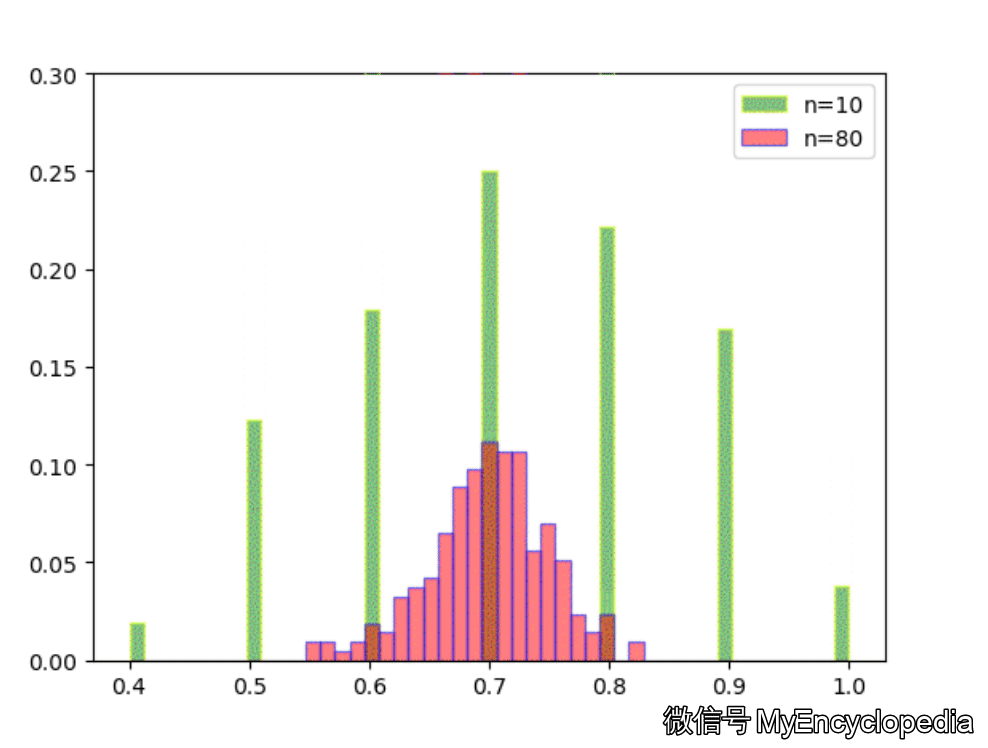
看的出来,随着试验次数的增多 - \(\hat\theta_{10}, \hat\theta_{80}\) 都趋近于正态分布
\(\hat\theta_{10}\) 的分散度比 $ _{80}$ 要大,即方差要大
\(\hat\theta_{10}, \hat\theta_{80}\) 的均值都在 0.7
公司计划面试 2N 人。第 i 人飞往 A 市的费用为 costs[i][0],飞往 B 市的费用为 costs[i][1]。
返回将每个人都飞到某座城市的最低费用,要求每个城市都有 N 人抵达。
示例:
输入:[[10,20],[30,200],[400,50],[30,20]] 输出:110 解释: 第一个人去 A 市,费用为 10。 第二个人去 A 市,费用为 30。 第三个人去 B 市,费用为 50。 第四个人去 B 市,费用为 20。 最低总费用为 10 + 30 + 50 + 20 = 110,每个城市都有一半的人在面试。
提示:
1 <= costs.length <= 100 costs.length 为偶数 1 <= costs[i][0], costs[i][1] <= 1000
链接:https://leetcode-cn.com/problems/two-city-scheduling
最直接的方式是暴力枚举出所有分组的可能。因为 2N 个人平均分成两组,总数为 \({2n \choose n}\),是 n 的指数级数量。在文章24 点游戏算法题的 Python 函数式实现: 学用itertools,yield,yield from 巧刷题,我们展示如何调用 Python 的 itertools包,这里,我们也用同样的方式产生 [0, 2N] 的所有集合大小为N的可能(保存在left_set_list中),再遍历找到最小值即可。当然,这种解法会TLE,只是举个例子来体会一下暴力做法。
1 | import math |
对于组合优化问题来说,例如TSP问题(解法链接 TSP问题从DP算法到深度学习1:递归DP方法 AC AIZU TSP问题),一般都是 NP-Hard问题,意味着没有多项次复杂度的解法。但是这个问题比较特殊,它增加了一个特定条件:去城市A和城市B的人数相同,也就是我们已经知道两个分组的数量是一样的。我们仔细思考一下这个意味着什么?考虑只有四个人的小规模情况,如果让你来手动规划,你一定不会穷举出所有两两分组的可能,而是比较人与人相对的两个城市的cost差。举个例子,有如下四个人的costs
1 | 0 A:3, B:1 |
有了这个想法,再整理一下,就会发现让某人去哪个城市和他去两个城市的cost 差 $ C_a - C_b$相关,如果这个值越大,那么他越应该去B。但是最后决定他是否去B取决于他的差在所有人中的排名,由于两组人数相等,因此差能大到排在前一半,则他就去B,在后一半就去A。
按照这个思路,很快能写出代码,代码写法有很多,下面略举一例。代码中由于用到排序,复杂度为 \(O(N \cdot \log(N))\) 。这里补充一点,理论上只需找数组中位数的值即可,最好的时间复杂度是 \(O(N)\)。
代码实现上,cost_diff_list 将每个人的在原数组的index 和他的cost差组成 pair。即
1 | [(0, cost_0), (1, cost_1), ... ] |
这样我们可以将这个数组按照cost排序,排完序后前面N个元素属于B城市。
1 | # AC |
这个问题对于略有算法经验的人来说,很类似于背包问题。它们都需要回答N个物品取或者不取,并同时最大最小化总cost。区别在它们的约束条件不一样。这道题的约束是去取(去城市A)和不取(去城市B)的数量一样。这一类问题即 integer programming,即整数规划。下面我们选取两个比较流行的优化库来展示如何调包解这道题。
首先我们先来formulate这个问题,因为需要表达两个约束条件,我们将每个人的状态分成是否去A和是否去B两个变量。
1 | x[i-th-person][0]: boolean 表示是否去 city a |
这样,问题转换成如下优化模型
\[ \begin{array}{rrclcl} \displaystyle \min_{x} & costs[i][0] \cdot x[i][0] + costs[i][1] \cdot x[i][1]\\ \textrm{s.t.} & x[i][0] + x[i][1] =1\\ &x[i][0] + x[i][1] + ... =N \\ \end{array} \]
Google OR-Tools 是业界最好的优化库,下面为调用代码,由于直接对应于上面的数学优化问题,不做赘述。当然 Leetcode上不支持这些第三方的库,肯定也不能AC。
1 | from ortools.sat.python import cp_model |
完整代码可以从我的github下载。
https://github.com/MyEncyclopedia/leetcode/blob/master/1029_Two_City_Scheduling/1029_ortool.py
类似的,另一种流行 python 优化库 PuLP 的代码为
1 | import pulp |
代码地址为
https://github.com/MyEncyclopedia/leetcode/blob/master/1029_Two_City_Scheduling/1029_pulp.py
上期 从零构建统计随机变量生成器之离散基础篇,我们从零出发构建了基于伯努利的基础离散分布,这一期我们来详细介绍广泛使用的 Inverse Transform Method(逆变换采样方法)。
Inverse Transform Method 是最基础常见的方法,可用于离散分布和连续分布。常见的分布一般都能通过此方法生成,只需要随机变量CDF的解析表达式。假设随机变量 \(X\),其CDF为 \(F^{-1}\),则 Inverse Transform Method 仅有两步
我们先举一个离散分布来直观感受一下其工作机制。有如下PMF的离散类别分布,范围在 [1, 5]。 \[ P(X = 1)=\frac{1}{15} \]
\[ P(X = 2)=\frac{2}{15} \]
\[ P(X = 3)=\frac{1}{5} \]
\[ P(X = 4)=\frac{4}{15} \]
\[ P(X = 5)=\frac{1}{3} \]
转换成CDF为
\[ P(X \leq 1)=\frac{1}{15} \]
\[ P(X \leq 2)=\frac{1}{15}+\frac{2}{15}=\frac{1}{5} \]
\[ P(X \leq 3)=\frac{1}{15}+\frac{2}{15}+\frac{1}{5}=\frac{6}{15} \]
\[ P(X \leq 4)=\frac{1}{15}+\frac{2}{15}+\frac{1}{5}+\frac{4}{15}=\frac{2}{3} \]
\[ P(X \leq 5)=\frac{1}{15}+\frac{2}{15}+\frac{1}{5}+\frac{4}{15}+\frac{1}{3}=1 \]
画出对应的CDF图
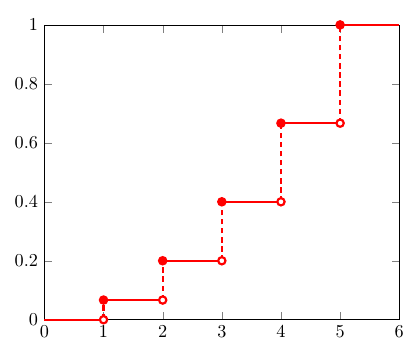
那么Inverse Transformation Method 的第一步,随机生成 0-1 之间的数 u,可以直观的认为是在 y 轴上生成一个随机的点 u。注意到5段竖虚线对应了5个离散的取值,它们的长度和为1,并且每一段长度代表了每个值的权重。因此,通过在 y 轴上的均匀采样可以生成给定PMF的 x 的分布。
离散分布的逆变换采样方法用数学公式可以表述为:找到第一个 x,其CDF的范围包括了 u,即
\[ F^{-1}(u)=\min \{x: F(x) \geq u\} \]
有了离散类别分布的直观感受,扩展到连续分布也就不难理解了。类似于微积分中将连续空间做离散切分,再通过极限的方法,连续光滑函数在 y 轴上可以切分成长度为 \(\Delta u\) 的线段,那么生成的 x 值就是其近似值。随着 $ _{u } $,最终 $ x=F^{-1}(u) $ 即为满足要求的分布。
以最为常见的指数分布为例,我们来看看具体的步骤。
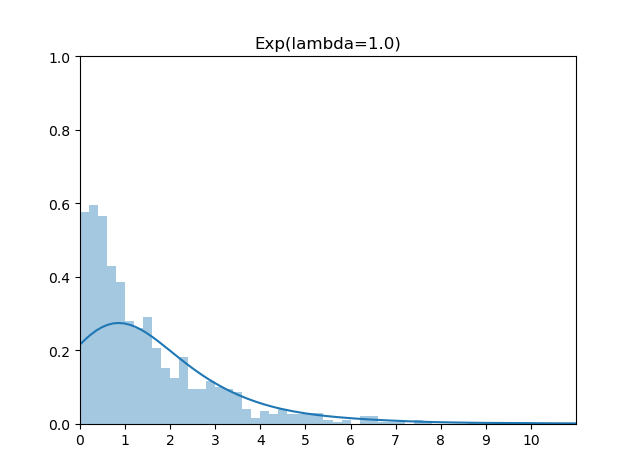
我们知道指数分布的PDF如下
\[ f(x)=\left\{\begin{array}{ll}\lambda e^{-\lambda x}, & x \geq 0 \\ 0, & x<0\end{array}\right. \]
PDF 图为
计算CDF为
\[ F(x)=\int_{-\infty}^{x} f(t) d t=\left\{\begin{array}{ll}1-e^{-\lambda x}, & x \geq 0 \\ 0, & x<0\end{array}\right. \]
CDF 图
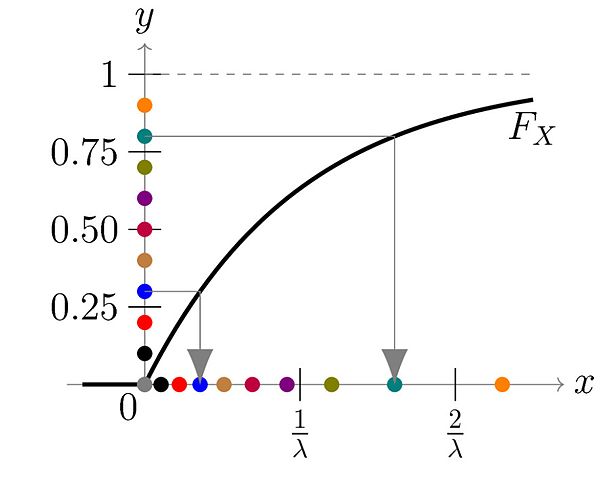
可以求得逆函数为
\[ x=F^{-1}(u)=-\frac{1}{\lambda} \ln (1-u) \]
由于 1-u 在 [0, 1] 范围上的随机数等价于 u,因此,x 的生成公式等价于
\[ x=-\frac{1}{\lambda} \ln (u) \]
对应代码很简单
1 | import random |
Github 代码地址:
https://github.com/MyEncyclopedia/stats_simulation/blob/main/distrib_sim/coutinous_exp_inv.py
我们再来看基于类别分布 Inverse Transformation Method的其他离散分布例子。在从零构建统计随机变量生成器之离散基础篇中,我们已经介绍了类别分布(Categorical Distribution)的逆变换采样算法,同时还介绍了通过模拟 Bernoulli 实验来生成二项,几何,超几何分布的方法。在这一篇中,我们通过逆变换采样算法再来生成这些分布。
先回顾一下类别分布的逆变换采样实现。
给定如下的类别分布, $p = [0.2, 0.3, 0.1, 0.4] $
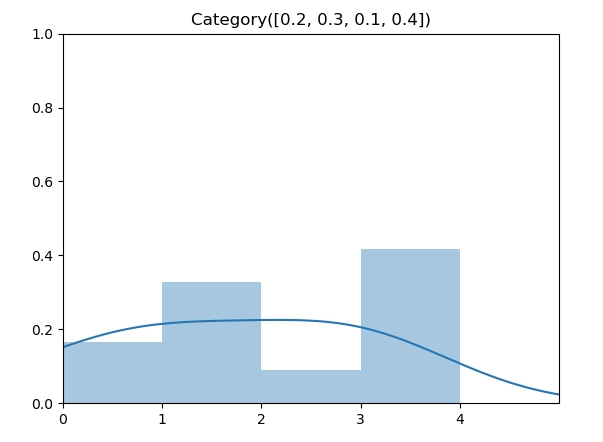
类别分布的逆变换采样实现需要找到第一个大于 u 的元素的索引序号,在我们的实现中,将 $p = [0.2, 0.3, 0.1, 0.4] $ 转换成累计概率 $c = [0.2, 0.5, 0.6, 1] $ 后,由于 \(\vec c\) 数组是非递减的,因此我们可以用二分法代替线性查找,将时间复杂度降到 \(O(log(n))\)。下面的实现中直接调用 python bisect 函数即可。
1 | import bisect |
Github 代码地址:
https://github.com/MyEncyclopedia/stats_simulation/blob/main/distrib_sim/discrete_categorical.py
二项分布(Binomial Distribution)有两个参数 n 和 p,表示伯努利实验做n次后成功的次数。图中为 n=6,p=0.5的二项分布。
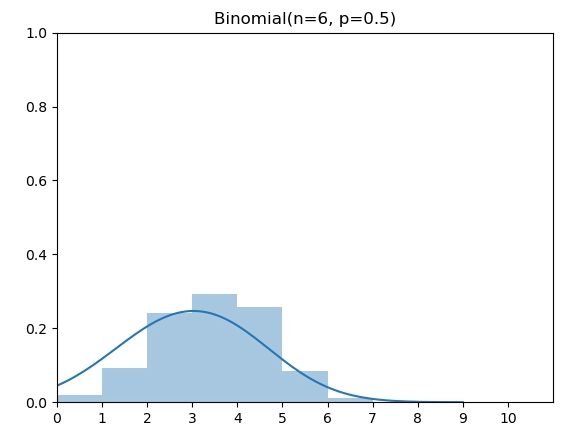
\[ \operatorname{P}_\text{Binomial}(X=k)=\left(\begin{array}{c}n \\ k\end{array}\right)p^{k}(1- p)^{n-k} \]
根据上面的PMF定义,我们将 [0, 6] 上的PMF计算出来,然后调用类别分布的逆变换采样实现即可:
1 | from scipy.special import comb |
Github 代码地址:
https://github.com/MyEncyclopedia/stats_simulation/blob/main/distrib_sim/discrete_binomial_inv.py
同样的,超几何分布(HyperGeometric Distribution)也可以如法炮制。
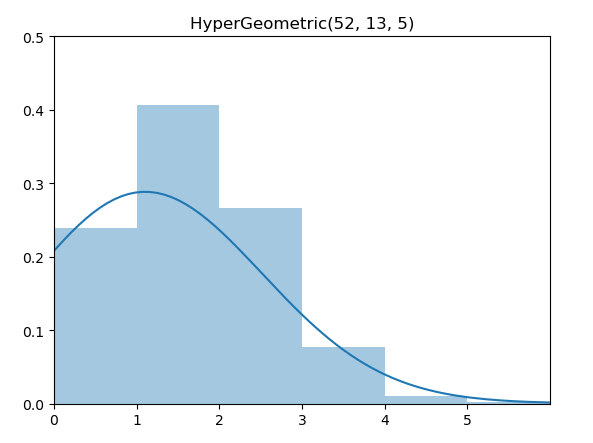
\[ \operatorname{P}_\text{Hypergeo}(X=k)=\frac{\left(\begin{array}{c}K \\ k\end{array}\right)\left(\begin{array}{c}N-k \\ n-k\end{array}\right)}{\left(\begin{array}{l}N \\ n\end{array}\right)} \]
1 | from scipy.special import comb |
Github 代码地址:
https://github.com/MyEncyclopedia/stats_simulation/blob/main/distrib_sim/discrete_hypergeometric_inv.py
几何分布(Geometric Distribution)和上面的二项分布以及超几何分布不同的是,它的 support 是所有非负整数,因此,我们无法穷举计算所有 x 的概率。但是,我们可以通过将CDF 推出 Inverse CDF的解析表达式来直接实现。
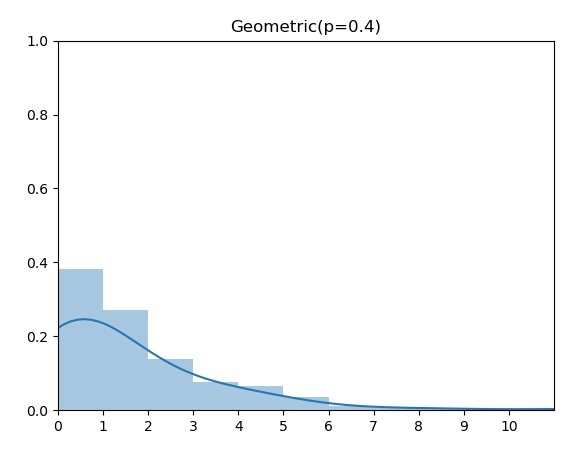
\[ \operatorname{P}_\text{Geometric}(X=k)=(1-p)^{k-1} p \]
\[ F_X(x) = 1- (1-p)^x \]
反函数求得为 \[ F^{-1}(u) = \lfloor { log(1-u) \over log(1-p) }\rfloor \]
1 | import random |
Github 代码地址:
https://github.com/MyEncyclopedia/stats_simulation/blob/main/distrib_sim/discrete_geometric_inv.py
一般,标准正态分布用Box-Muller 方法来生成,这个后续将做详细介绍。这里我们用 Schmeiser 提出的基于Inverse Transformation Method的近似方法来生成:
\[ X=F^{-1}(u) \approx \frac{u^{0.135}-(1-u)^{0.135}}{0.1975} \]
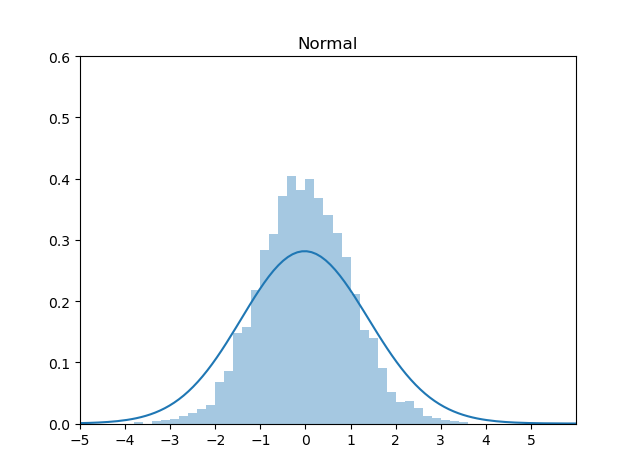
1 | import random |
Github 代码地址:
https://github.com/MyEncyclopedia/stats_simulation/blob/main/distrib_sim/coutinous_normal_apprx.py
http://www.columbia.edu/~ks20/4404-Sigman/4404-Notes-ITM.pdf
https://www.win.tue.nl/~marko/2WB05/lecture8.pdf
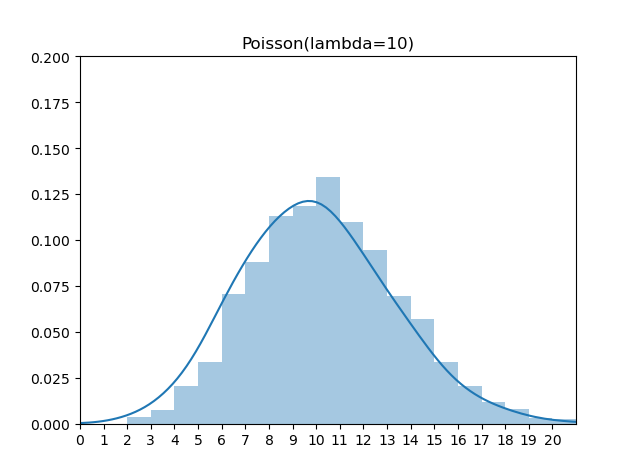
1 | import random |
https://github.com/MyEncyclopedia/stats_simulation/blob/main/distrib_sim/discrete_poisson_inv.py
1 | from numpy.random import exponential |
https://github.com/MyEncyclopedia/stats_simulation/blob/main/distrib_sim/discrete_poisson_from_exp.py
$ E_{1}, E_{2}, E_{3}, (1) $
\[ \mathbb{P}(K \geqslant k)=\mathbb{P}\left(E_{1}+\cdots+E_{k} \leqslant \lambda\right) \]
1 | from numpy.random import exponential |
Github 代码地址:
https://github.com/MyEncyclopedia/stats_simulation/blob/main/distrib_sim/discrete_poisson_from_exp.py
Policy gradient 定理作为现代深度强化学习的基石,同时也是actor-critic的基础,重要性不言而喻。但是它的推导和理解不是那么浅显,不同的资料中又有着众多形式,不禁令人困惑。本篇文章MyEncyclopedia试图总结众多资料背后的一些相通的地方,并写下自己的一些学习理解心得。
\[ \theta^{\star}=\arg \max _{\theta} J(\theta) \]
\[ {\theta}_{t+1} \doteq {\theta}_{t}+\alpha \nabla J(\theta) \]
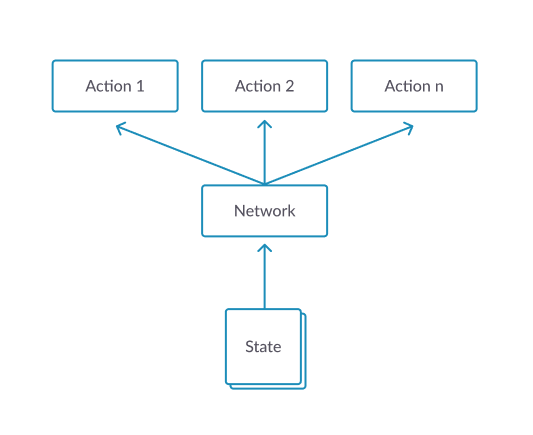
那么问题来了,首先一个如何定义 \(J(\theta)\),其次,如何求出或者估计 $ J()$。
第一个问题比较直白,用value function或者广义的expected return都可以。
这里列举一些常见的定义。对于episodic 并且初始都是 \(s_0\)状态的情况,直接定义成v值,即Sutton教程中的episodic情况下的定义
\[ J(\boldsymbol{\theta}) \doteq v_{\pi_{\boldsymbol{\theta}}}\left(s_{0}\right) \quad \quad \text{(1.1)} \]
\[ \begin{aligned} J(\theta) &= \sum_{s \in \mathcal{S}} d^{\pi}(s) V^{\pi}(s) \\ &=\sum_{s \in \mathcal{S}} d^{\pi}(s) \sum_{a \in \mathcal{A}} \pi_{\theta}(a \mid s) Q^{\pi}(s, a) \end{aligned} \quad \quad \text{(1.2)} \]
其中,状态平稳分布 \(d^{\pi}(s)\) 定义为
\[ d^{\pi}(s)=\lim _{t \rightarrow \infty} P\left(s_{t}=s \mid s_{0}, \pi_{\theta}\right) \]
\[ J(\boldsymbol{\theta}) \doteq E_{\tau \sim p_{\theta}(\tau)}\left[\sum_{t} r\left(\mathbf{s}_{t}, \mathbf{a}_{t}\right)\right] \quad \quad \text{(1.3)} \]
即$ $ 是一次trajectory,服从以 \(\theta\) 作为参数的随机变量
\[ \tau \sim p_{\theta}\left(\mathbf{s}_{1}, \mathbf{a}_{1}, \ldots, \mathbf{s}_{T}, \mathbf{a}_{T}\right) \]
\(J(\theta)\) 对于所有的可能的 \(\tau\) 求 expected return。这种视角下对于finite 和 infinite horizon来说也有变形。
Infinite horizon 情况下,通过 \((s, a)\) 的marginal distribution来计算\[ J(\boldsymbol{\theta}) \doteq E_{(\mathbf{s}, \mathbf{a}) \sim p_{\theta}(\mathbf{s}, \mathbf{a})}[r(\mathbf{s}, \mathbf{a})] \quad \quad \text{(1.4)} \]
\[ J(\boldsymbol{\theta}) \doteq \sum_{t=1}^{T} E_{\left(\mathbf{s}_{t}, \mathbf{a}_{t}\right) \sim p_{\theta}\left(\mathbf{s}_{t}, \mathbf{a}_{t}\right)} \quad \quad \text{(1.5)} \]
\[ p\left(s^{\prime}, r \mid s, a\right) = \operatorname{Pr}\left\{S_{t}=s^{\prime}, R_{t}=r \mid S_{t-1}=s, A_{t-1}=a\right\} \]
当环境dynamics未知时,如何再去求 $ J()$ 呢。还有就是如果涉及到状态的分布也是取决于环境dynamics的,计算 $ J()$ 也面临同样的问题。
幸好,policy gradient定理完美的解答了上述问题。我们先来看看它的表述内容。
\[ \nabla J(\boldsymbol{\theta}) \propto \sum_{s} \mu(s) \sum_{a} q_{\pi}(s, a) \nabla \pi(a \mid s, \boldsymbol{\theta}) \quad \quad \text{(2.1)} \]
\[ \nabla J(\boldsymbol{\theta}) =\mathbb{E}_{\pi}\left[\sum_{a} q_{\pi}\left(S_{t}, a\right) \nabla \pi\left(a \mid S_{t}, \boldsymbol{\theta}\right)\right] \quad \quad \text{(2.2)} \]
Policy Gradient 定理的伟大之处在于等式右边并没有 \(d^{\pi}(s)\),或者环境transition model \(p\left(s^{\prime}, r \mid s, a\right)\)!同时,等式右边变换成了最利于统计采样的期望形式,因为期望可以通过样本的平均来估算。
但是,这里必须注意的是action space的期望并不是基于 $(a S_{t}, ) $ 的权重的,因此,继续改变形式,引入 action space的 on policy 权重 $(a S_{t}, ) $ ,得到 2.3式。
\[ \nabla J(\boldsymbol{\theta})=\mathbb{E}_{\pi}\left[\sum_{a} \pi\left(a \mid S_{t}, \boldsymbol{\theta}\right) q_{\pi}\left(S_{t}, a\right) \frac{\nabla \pi\left(a \mid S_{t}, \boldsymbol{\theta}\right)}{\pi\left(a \mid S_{t}, \boldsymbol{\theta}\right)}\right] \quad \quad \text{(2.3)} \]
\[ \nabla J(\boldsymbol{\theta})==\mathbb{E}_{\pi}\left[q_{\pi}\left(S_{t}, A_{t}\right) \frac{\nabla \pi\left(A_{t} \mid S_{t}, \boldsymbol{\theta}\right)}{\pi\left(A_{t} \mid S_{t}, \boldsymbol{\theta}\right)}\right] \quad \quad \text{(2.4)} \]
将 \(q_{\pi}\)替换成 \(G_t\),由于
\[ \mathbb{E}_{\pi}[G_{t} \mid S_{t}, A_{t}]= q_{\pi}\left(S_{t}, A_{t}\right) \]
得到2.5式
\[ \nabla J(\boldsymbol{\theta})==\mathbb{E}_{\pi}\left[G_{t} \frac{\nabla \pi\left(A_{t} \mid S_{t}, \boldsymbol{\theta}\right)}{\pi\left(A_{t} \mid S_{t}, \boldsymbol{\theta}\right)}\right] \quad \quad \text{(2.5)} \]
\[ \nabla J(\boldsymbol{\theta}) \approx G_{t} \frac{\nabla \pi\left(A_{t} \mid S_{t}, \boldsymbol{\theta}\right)}{\pi\left(A_{t} \mid S_{t}, \boldsymbol{\theta}\right)} \quad \quad \text{(2.6)} \]
\[ \boldsymbol{\theta}_{t+1} \doteq \boldsymbol{\theta}_{t}+\alpha G_{t} \frac{\nabla \pi\left(A_{t} \mid S_{t}, \boldsymbol{\theta}_{t}\right)}{\pi\left(A_{t} \mid S_{t}, \boldsymbol{\theta}_{t}\right)} \quad \quad \text{(2.7)} \]

\[ J(\boldsymbol{\theta}) \doteq E_{\tau \sim p_{\theta}(\tau)}\left[\sum_{t} r\left(\mathbf{s}_{t}, \mathbf{a}_{t}\right)\right] \quad \quad \text{(1.3)} \]
\[ \nabla_{\theta} J\left(\pi_{\theta}\right)=\underset{\tau \sim \pi_{\theta}}{\mathrm{E}}\left[\sum_{t=0}^{T} \nabla_{\theta} \log \pi_{\theta}\left(a_{t} \mid s_{t}\right) R(\tau)\right] \quad \quad \text{(3.1)} \]
\[ \hat{R}_{t} \doteq \sum_{t^{\prime}=t}^{T} R\left(s_{t^{\prime}}, a_{t^{\prime}}, s_{t^{\prime}+1}\right) \]
\[ \nabla_{\theta} J\left(\pi_{\theta}\right)=\underset{\tau \sim \pi_{\theta}}{\mathrm{E}}\left[\sum_{t=0}^{T} \nabla_{\theta} \log \pi_{\theta}\left(a_{t} \mid s_{t}\right) \hat{R}_{t} \right] \quad \quad \text{(3.2)} \]
\[ \nabla_{\theta} \log \pi_{\theta}(a)=\frac{\nabla_{\theta} \pi_{\theta}}{\pi_{\theta}} \quad \quad \text{(3.3)} \]
Policy Gradient中的 \(\nabla_{\theta} \log \pi\) 广泛存在在机器学习范畴中,被称为 score function gradient estimator。RL 在supervised learning settings 中有 imitation learning,即通过专家的较优stochastic policy \(\pi_{\theta}(a|s)\) 收集数据集
\[ \{(s_1, a^{*}_1), (s_2, a^{*}_2), ...\} \]
\[ \theta^{*}=\operatorname{argmax}_{\theta} \sum_{n} \log \pi_{\theta}\left(a_{n}^{*} \mid s_{n}\right) \quad \quad \text{(4.1)} \]
\[ \theta_{n+1} \leftarrow \theta_{n}+\alpha_{n} \nabla_{\theta} \log \pi_{\theta}\left(a_{n}^{*} \mid s_{n}\right) \quad \quad \text{(4.2)} \]
对照Policy Graident RL,on-policy \(\pi_{\theta}(a|s)\) 产生数据集
\[ \{(s_1, a_1, r_1), (s_2, a_2, r_2), ...\} \]
目标是最大化on-policy \(\pi_{\theta}\) 分布下的expected return
\[ \theta^{*}=\operatorname{argmax}_{\theta} \sum_{n} R(\tau_{n}) \]
\[ \theta_{n+1} \leftarrow \theta_{n}+\alpha_{n} G_{n} \nabla_{\theta} \log \pi_{\theta}\left(a_{n} \mid s_{n}\right) \quad \quad \text{(4.3)} \]
对比 4.3 和 4.2,发现此时4.3中只多了一个权重系数 \(G_n\)。
关于 $G_{n} {} {}(a_{n} s_{n}) $ 或者 \(G_{t} \frac{\nabla \pi\left(A_{t} \mid S_{t}, \boldsymbol{\theta}_{t}\right)}{\pi\left(A_{t} \mid S_{t}, \boldsymbol{\theta}_{t}\right)}\) 有一些深入的理解。
首先policy gradient RL 不像supervised imitation learning直接有label 作为signal,PG RL必须通过采样不同的action获得reward或者return作为signal,即1.4式中的\[ E_{(\mathbf{s}, \mathbf{a}) \sim p_{\theta}(\mathbf{s}, \mathbf{a})}[r(\mathbf{s}, \mathbf{a})] \quad \quad \text{(5.1)} \]
\[ E_{x \sim p(x \mid \theta)}[f(x)] \quad \quad \text{(5.2)} \]
\[ \begin{aligned} \nabla_{\theta} E_{x}[f(x)] &=\nabla_{\theta} \sum_{x} p(x) f(x) \\ &=\sum_{x} \nabla_{\theta} p(x) f(x) \\ &=\sum_{x} p(x) \frac{\nabla_{\theta} p(x)}{p(x)} f(x) \\ &=\sum_{x} p(x) \nabla_{\theta} \log p(x) f(x) \\ &=E_{x}\left[f(x) \nabla_{\theta} \log p(x)\right] \end{aligned} \quad \quad \text{(5.3)} \]
Policy Gradient 工作的机制大致如下
首先,根据现有的 on-policy \(\pi_{\theta}\) 采样出一些动作 action 产生trajectories,这些trajectories最终得到反馈 \(R(\tau)\)
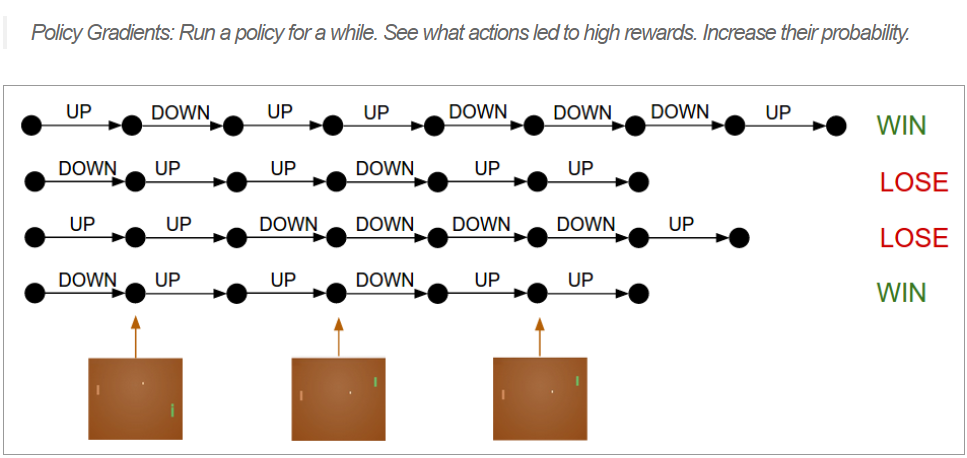
\[ R(s,a) \nabla \pi_{\theta_{t}}(a \mid s) \approx \nabla \pi_{\theta_{t}}(a^{*} \mid s) \]
最后,由于采样到的action分布服从于\(a \sim \pi_{\theta}(a)\) ,除掉 \(\pi_{\theta}\) :
\(G_{t} \frac{\nabla \pi\left(A_{t} \mid S_{t}, \boldsymbol{\theta}_{t}\right)}{\pi\left(A_{t} \mid S_{t}, \boldsymbol{\theta}_{t}\right)}\)
此时,采样的均值可以去无偏估计2.2式中的Expectation。
\[ \sum_N G_{t} \frac{\nabla \pi\left(A_{t} \mid S_{t}, \boldsymbol{\theta}_{t}\right)}{\pi\left(A_{t} \mid S_{t}, \boldsymbol{\theta}_{t}\right)} \]
\[ =\mathbb{E}_{\pi}\left[\sum_{a} q_{\pi}\left(S_{t}, a\right) \nabla \pi\left(a \mid S_{t}, \boldsymbol{\theta}\right)\right] \]
上一期 MyEncyclopedia公众号文章 从Q-Learning 演化到 DQN,我们从原理上讲解了DQN算法,这一期,让我们通过代码来实现任天堂游戏机中经典的超级玛丽的自动通关吧。本文所有代码在 https://github.com/MyEncyclopedia/reinforcement-learning-2nd/tree/master/super_mario。
上期详细讲解了DQN中的两个重要的技术:Target Network 和 Experience Replay,正是有了它们才使得 Deep Q Network在实战中容易收敛,以下是Deepmind 发表在Nature 的 Human-level control through deep reinforcement learning 的完整算法流程。

安装基于OpenAI gym的超级玛丽环境执行下面的 pip 命令即可。
1 | pip install gym-super-mario-bros |
我们先来看一下游戏环境的输入和输出。下面代码采用随机的action来和游戏交互。有了 组合游戏系列3: 井字棋、五子棋的OpenAI Gym GUI环境 对于OpenAI Gym 接口的介绍,现在对于其基本的交互步骤已经不陌生了。
1 | import gym_super_mario_bros |
游戏render效果如下
。。。
注意我们在游戏环境初始化的时候用了参数 RIGHT_ONLY,它定义成五种动作的list,表示仅使用右键的一些组合,适用于快速训练来完成Mario第一关。
1 | RIGHT_ONLY = [ |
观察一些 info 输出内容,coins表示金币获得数量,flag_get 表示是否取得最后的旗子,time 剩余时间,以及 Mario 大小状态和所在的 x,y位置。
1 | { |
Deep Reinforcement Learning 一般是 end-to-end learning,意味着游戏的 screen image 作为observation直接视为真实状态,喂给神经网络训练。于此相反的另一种做法是,通过游戏环境拿到内部状态,例如所有相关物品的位置和属性作为模型输入。这两种方式的区别有两点。第一点,用观察到的屏幕像素代替真正的状态 s,在partially observable 的环境时可能因为 non-stationarity 导致无法很好的工作,而拿内部状态利用了额外的作弊信息,在partially observable环境中也可以工作。第二点,第一种方式屏幕像素维度比较高,输入数据量大,需要神经网络的大量训练拟合,第二种方式,内部真实状态往往维度低得多,训练起来很快,但缺点是因为除了内部状态往往还需要游戏相关规则作为输入,因此generalization能力不如前者强。
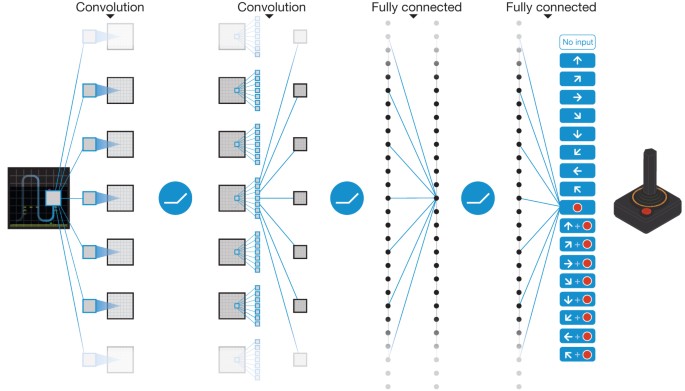
这里,我们当然采样屏幕像素的 end-to-end 方式了,自然首要任务是将游戏帧图像有效处理。超级玛丽游戏环境的屏幕输出是 (240, 256, 3) shape的 numpy array,通过下面一系列的转换,尽可能的在不影响训练效果的情况下减小采样到的数据量。
MaxAndSkipFrameWrapper:每4个frame连在一起,采取同样的动作,降低frame数量。
FrameDownsampleWrapper:将原始的 (240, 256, 3) down sample 到 (84, 84, 1)
ImageToPyTorchWrapper:转换成适合 pytorch 的 (1, 84, 84) shape
FrameBufferWrapper:保存最后4次屏幕采样
NormalizeFloats:Normalize 成 [0., 1.0] 的浮点值
1 | def wrap_environment(env_name: str, action_space: list) -> Wrapper: |
模型比较简单,三个卷积层后做 softmax输出,输出维度数为离散动作数。act() 采用了epsilon-greedy 模式,即在epsilon小概率时采取随机动作来 explore,大于epsilon时采取估计的最可能动作来 exploit。
1 | class DQNModel(nn.Module): |
实现采用了 Pytorch CartPole DQN 的官方代码,本质是一个最大为 capacity 的 list 保存采样的 (s, a, r, s', is_done) 五元组。
1 | Transition = namedtuple('Transition', ('state', 'action', 'reward', 'next_state', 'done')) |
我们将 DQN 的逻辑封装在 DQNAgent 类中。DQNAgent 成员变量包括两个 DQNModel,一个ReplayMemory。
train() 方法中会每隔一定时间将 Target Network 的参数同步成现行Network的参数。在td_loss_backprop()方法中采样 ReplayMemory 中的五元组,通过minimize TD error方式来改进现行 Network 参数 \(\theta\)。Loss函数为:
\[ L\left(\theta_{i}\right)=\mathbb{E}_{\left(s, a, r, s^{\prime}\right) \sim \mathrm{U}(D)}\left[\left(r+\gamma \max _{a^{\prime}} Q_{target}\left(s^{\prime}, a^{\prime} ; \theta_{i}^{-}\right)-Q\left(s, a ; \theta_{i}\right)\right)^{2}\right] \]
1 | class DQNAgent(): |
最后是外层调用代码,基本和以前文章一样。
1 | def train(env, args, agent): |
Update your browser to view this website correctly. Update my browser now