for v inrange(N): next_q.put(PQItem(initial[v], str(v)))
for l inrange(1, L): current_q = next_q next_q = PriorityQueue() k = K whilenot current_q.empty() and k > 0: item = current_q.get() prob, route, prev_v = item.prob, item.route, item.last_v k -= 1 for v inrange(N): nextItem = PQItem(prob * transition[prev_v][v], route + str(v)) next_q.put(nextItem)
# AC # Runtime: 32 ms, faster than 54.28% of Python3 online submissions for Pow(x, n). # Memory Usage: 14.2 MB, less than 5.04% of Python3 online submissions for Pow(x, n).
classSolution: defmyPow(self, x: float, n: int) -> float: ret = 1.0 i = abs(n) while i != 0: if i & 1: ret *= x x *= x i = i >> 1 return1.0 / ret if n < 0else ret
对应的 Java 的代码。
{linenos
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
// AC // Runtime: 1 ms, faster than 42.98% of Java online submissions for Pow(x, n). // Memory Usage: 38.7 MB, less than 48.31% of Java online submissions for Pow(x, n).
classSolution{ publicdoublemyPow(double x, int n){ double ret = 1.0; long i = Math.abs((long) n); while (i != 0) { if ((i & 1) > 0) { ret *= x; } x *= x; i = i >> 1; }
publicint[][] matrixProd(int[][] A, int[][] B) { int R = A.length; int C = B[0].length; int P = A[0].length; int[][] ret = newint[R][C]; for (int r = 0; r < R; r++) { for (int c = 0; c < C; c++) { for (int p = 0; p < P; p++) { ret[r][c] += A[r][p] * B[p][c]; } } } return ret; }
The Fibonacci numbers, commonly denoted F(n) form a
sequence, called the Fibonacci sequence, such that each
number is the sum of the two preceding ones, starting from 0 and 1. That
is,
1 2
F(0) = 0, F(1) = 1 F(N) = F(N - 1) + F(N - 2), for N > 1.
/** * AC * Runtime: 0 ms, faster than 100.00% of Java online submissions for Fibonacci Number. * Memory Usage: 37.9 MB, less than 18.62% of Java online submissions for Fibonacci Number. * * Method: Matrix Fast Power Exponentiation * Time Complexity: O(log(N)) **/ classSolution{ publicintfib(int N){ if (N <= 1) { return N; } int[][] M = {{1, 1}, {1, 0}}; // powers = M^(N-1) N--; int[][] powerDouble = M; int[][] powers = {{1, 0}, {0, 1}}; while (N > 0) { if (N % 2 == 1) { powers = matrixProd(powers, powerDouble); } powerDouble = matrixProd(powerDouble, powerDouble); N = N / 2; }
return powers[0][0]; }
publicint[][] matrixProd(int[][] A, int[][] B) { int R = A.length; int C = B[0].length; int P = A[0].length; int[][] ret = newint[R][C]; for (int r = 0; r < R; r++) { for (int c = 0; c < C; c++) { for (int p = 0; p < P; p++) { ret[r][c] += A[r][p] * B[p][c]; } } } return ret; }
# AC # Runtime: 256 ms, faster than 26.21% of Python3 online submissions for Fibonacci Number. # Memory Usage: 29.4 MB, less than 5.25% of Python3 online submissions for Fibonacci Number.
classSolution:
deffib(self, N: int) -> int: if N <= 1: return N
import numpy as np F = np.array([[1, 1], [1, 0]])
N -= 1 powerDouble = F powers = np.array([[1, 0], [0, 1]]) while N > 0: if N % 2 == 1: powers = np.matmul(powers, powerDouble) powerDouble = np.matmul(powerDouble, powerDouble) N = N // 2
return powers[0][0]
或者也可以直接调用numpy.matrix_power() 代替手动的快速矩阵幂运算。
{linenos
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
# AC # Runtime: 116 ms, faster than 26.25% of Python3 online submissions for Fibonacci Number. # Memory Usage: 29.2 MB, less than 5.25% of Python3 online submissions for Fibonacci Number.
classSolution:
deffib(self, N: int) -> int: if N <= 1: return N
from numpy.linalg import matrix_power import numpy as np F = np.array([[1, 1], [1, 0]]) F = matrix_power(F, N - 1)
return F[0][0]
Leetcode
1411. Number of Ways to Paint N × 3 Grid (Hard)
You have a grid of size n x 3 and you want
to paint each cell of the grid with exactly one of the three colours:
Red, Yellow or Green
while making sure that no two adjacent cells have the same colour (i.e
no two cells that share vertical or horizontal sides have the same
colour).
You are given n the number of rows of the grid.
Return the number of ways you can paint this
grid. As the answer may grow large, the answer must
be computed modulo 10^9 + 7.
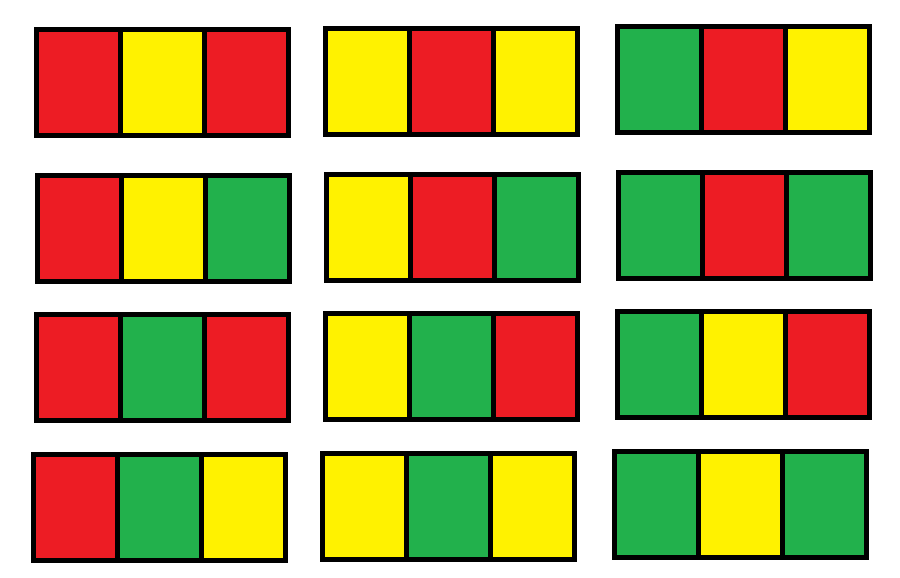
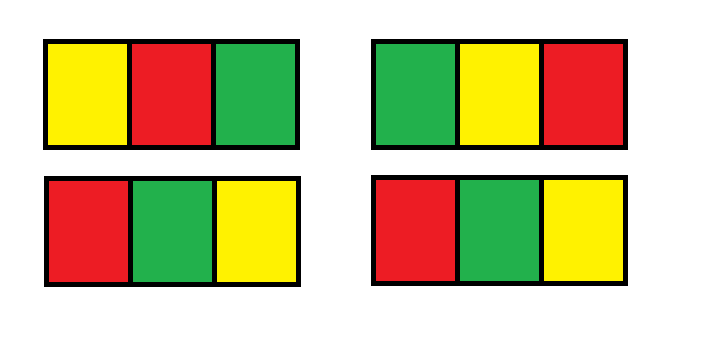
Example 1:
1 2 3
Input: n = 1 Output: 12 Explanation: There are 12 possible way to paint the grid as shown:
# AC # Runtime: 36 ms, faster than 98.88% of Python3 online submissions for Number of Ways to Paint N × 3 Grid. # Memory Usage: 13.9 MB, less than 58.66% of Python3 online submissions for Number of Ways to Paint N × 3 Grid.
classSolution: defnumOfWays(self, n: int) -> int: MOD = 10 ** 9 + 7 dp2, dp3 = 6, 6 n -= 1 while n > 0: dp2, dp3 = (dp2 * 3 + dp3 * 2) % MOD, (dp2 * 2 + dp3 * 2) % MOD n -= 1 return (dp2 + dp3) % MOD
/** AC Runtime: 0 ms, faster than 100.00% of Java online submissions for Number of Ways to Paint N × 3 Grid. Memory Usage: 35.7 MB, less than 97.21% of Java online submissions for Number of Ways to Paint N × 3 Grid. **/
classSolution{ publicintnumOfWays(int n){ long MOD = (long) (1e9 + 7); long[][] ret = {{6, 6}}; long[][] m = {{3, 2}, {2, 2}}; n -= 1; while(n > 0) { if ((n & 1) > 0) { ret = matrixProd(ret, m, MOD); } m = matrixProd(m, m, MOD); n >>= 1; } return (int) ((ret[0][0] + ret[0][1]) % MOD);
}
publiclong[][] matrixProd(long[][] A, long[][] B, long MOD) { int R = A.length; int C = B[0].length; int P = A[0].length; long[][] ret = newlong[R][C]; for (int r = 0; r < R; r++) { for (int c = 0; c < C; c++) { for (int p = 0; p < P; p++) { ret[r][c] += A[r][p] * B[p][c]; ret[r][c] = ret[r][c] % MOD; } } } return ret; }
}
Python 3实现为
{linenos
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
# AC # Runtime: 88 ms, faster than 39.07% of Python3 online submissions for Number of Ways to Paint N × 3 Grid. # Memory Usage: 30.2 MB, less than 11.59% of Python3 online submissions for Number of Ways to Paint N × 3 Grid.
classSolution: defnumOfWays(self, n: int) -> int: import numpy as np
MOD = int(1e9 + 7) ret = np.array([[6, 6]]) m = np.array([[3, 2], [2, 2]])
n -= 1 while n > 0: if n % 2 == 1: ret = np.matmul(ret, m) % MOD m = np.matmul(m, m) % MOD n = n // 2 returnint((ret[0][0] + ret[0][1]) % MOD)
但是此方法有一个前提要满足,由于数据是依据策略 \(\pi_{i}\)
生成的,理论上需要保证在无限次的模拟过程中,每个状态都必须被无限次访问到,才能保证最终每个状态的Q估值收敛到真实的
\(q_{*}\)。满足这个前提的一个简单实现是强制随机环境初始状态,保证每个状态都能有一定概率被生成。这个思路就是
Monte Carlo Control with Exploring Starts算法,伪代码如下:
\[
\begin{align*}
&\textbf{Monte Carlo ES (Exploring Starts), for estimating } \pi
\approx \pi_{*} \\
& \text{Initialize:} \\
& \quad \pi(s) \in \mathcal A(s) \text{ arbitrarily for all }s \in
\mathcal{S} \\
& \quad Q(s, a) \in \mathbb R \text{, arbitrarily, for all }s \in
\mathcal{S}, a \in \mathcal A(s) \\
& \quad Returns(s, a) \leftarrow \text{ an empty list, for all }s
\in \mathcal{S}, a \in \mathcal A(s)\\
& \\
& \text{Loop forever (for episode):}\\
& \quad \text{Choose } S_0\in \mathcal{S}, A_0 \in \mathcal A(S_0)
\text{ randomly such that all pairs have probability > 0} \\
& \quad \text{Generate an episode from } S_0, A_0 \text{, following
} \pi : S_0, A_0, R_1, S_1, A_1, R_2, ..., S_{T-1}, A_{T-1}, R_T\\
& \quad G \leftarrow 0\\
& \quad \text{Loop for each step of episode, } t = T-1, T-2, ...,
0:\\
& \quad \quad \quad G \leftarrow \gamma G + R_{t+1}\\
& \quad \quad \quad \text{Unless the pair } S_t, A_t \text{ appears
in } S_0, A_0, S_1, A_1, ..., S_{t-1}, A_{t-1}\\
& \quad \quad \quad \quad \text{Append } G \text { to }Returns(S_t,
A_t) \\
& \quad \quad \quad \quad Q(S_t, A_t) \leftarrow
\operatorname{average}(Returns(S_t, A_t))\\
& \quad \quad \quad \quad \pi(S_t) \leftarrow
\operatorname{argmax}_a Q(S_t, a)\\
\end{align*}
\]
下面我们实现21点游戏的Monte Carlo ES
算法。21点游戏只有200个有效的状态,可以满足算法要求的生成episode前先随机选择某一状态的前提条件。
G = 0 for t inrange(len(episode_history) - 1, -1, -1): s, a, r = episode_history[t] G = discount_factor * G + r ifnotany(s_a_r[0] == s and s_a_r[1] == a for s_a_r in episode_history[0: t]): returns_sum[s, a] += G returns_count[s, a] += 1.0 Q[s][a] = returns_sum[s, a] / returns_count[s, a] best_a = np.argmax(Q[s]) policy[s][best_a] = 1.0 policy[s][1-best_a] = 0.0
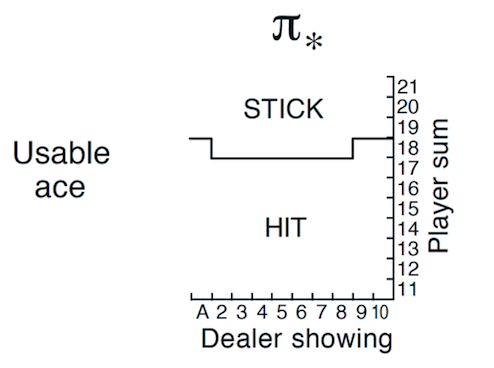
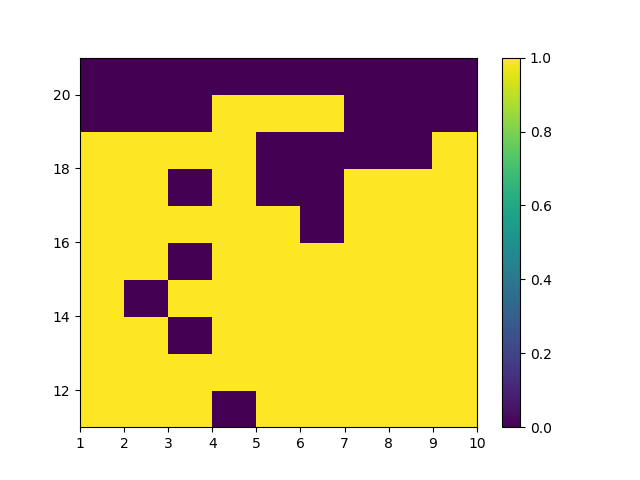
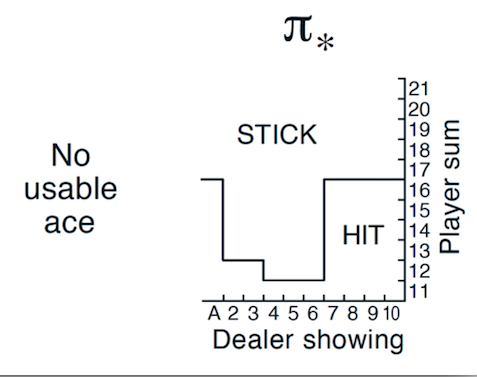
下图是有Usable Ace情况下的理论最优策略。
理论最佳策略(有Ace)
Monte
Carlo方法策略提示的收敛是比较慢的,下图是运行10,000,000次episode后有Usable
Ace时的策略 \(\pi_{*}^{\prime}\)。对比理论最优策略,MC
ES在不少的状态下还未收敛到理论最优解。
MC ES 10M的最佳策略(有Ace)
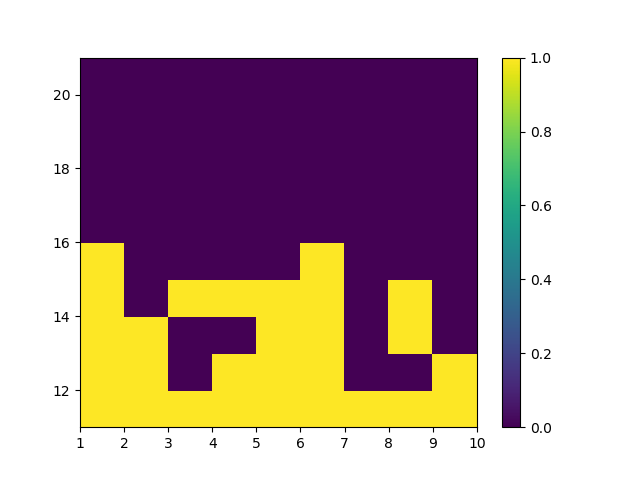
同样的,下两张图是无Usable Ace情况下的理论最优策略和试验结果的对比。
理论最佳策略(无Ace)
MC ES 10M的最佳策略(无Ace)
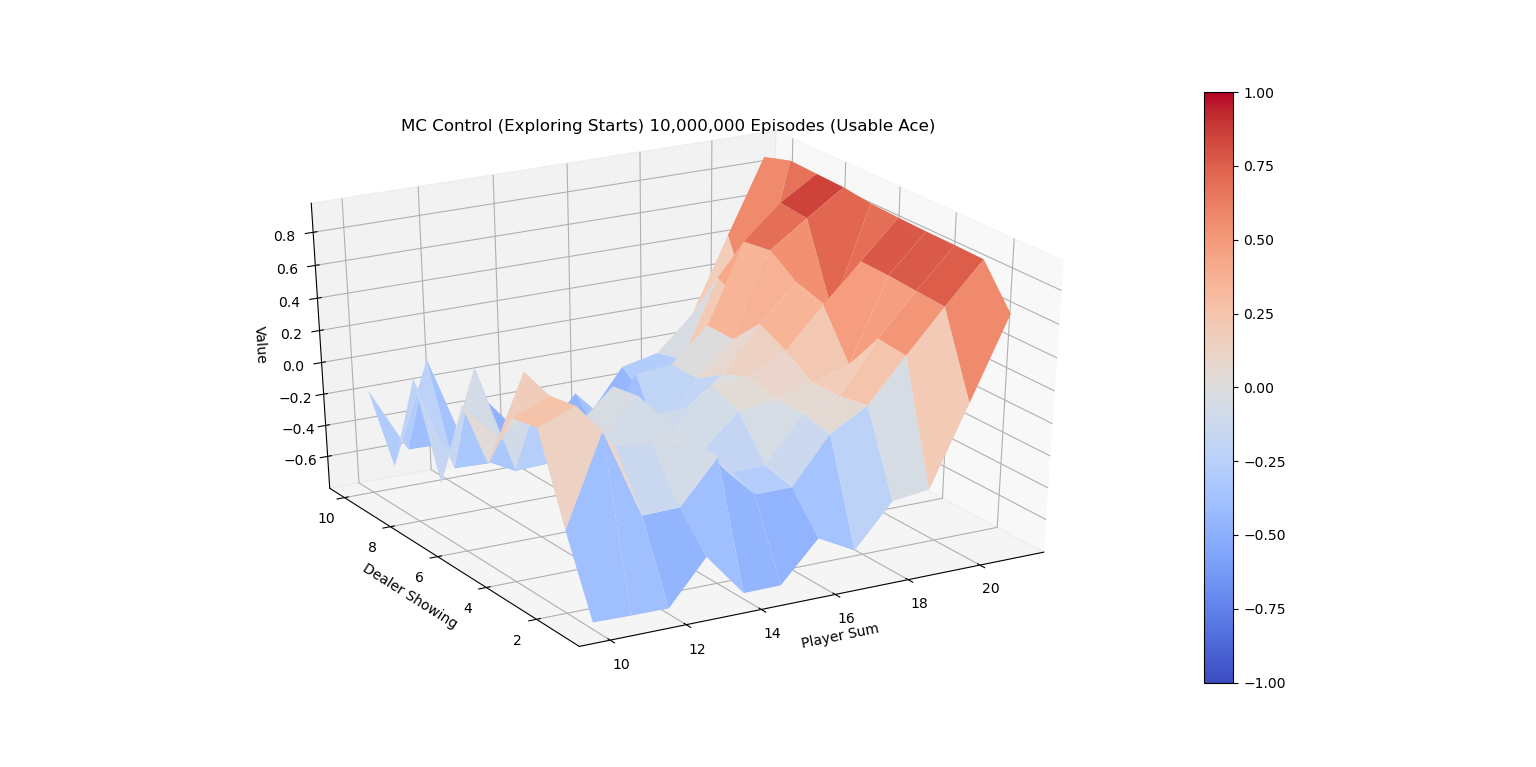
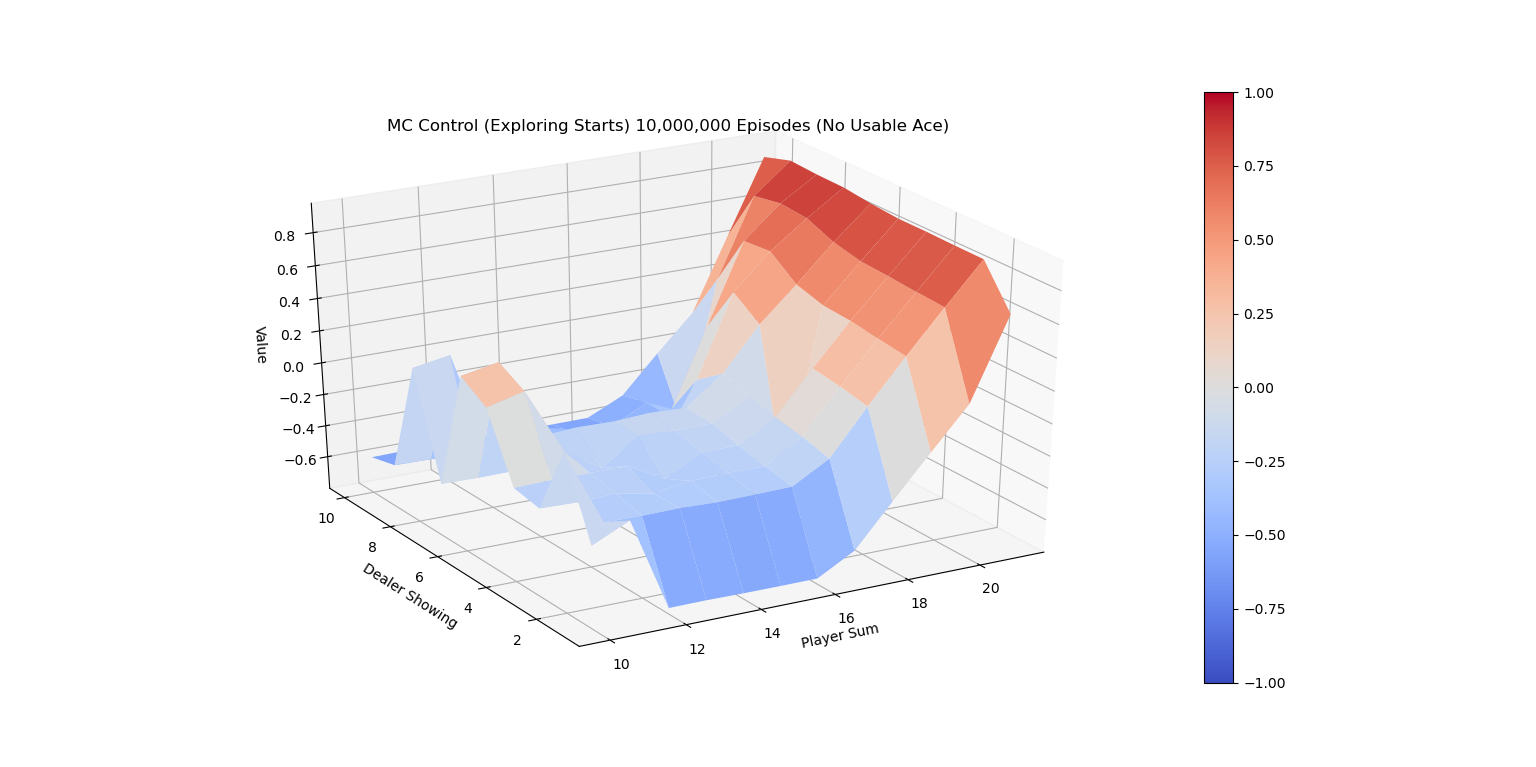
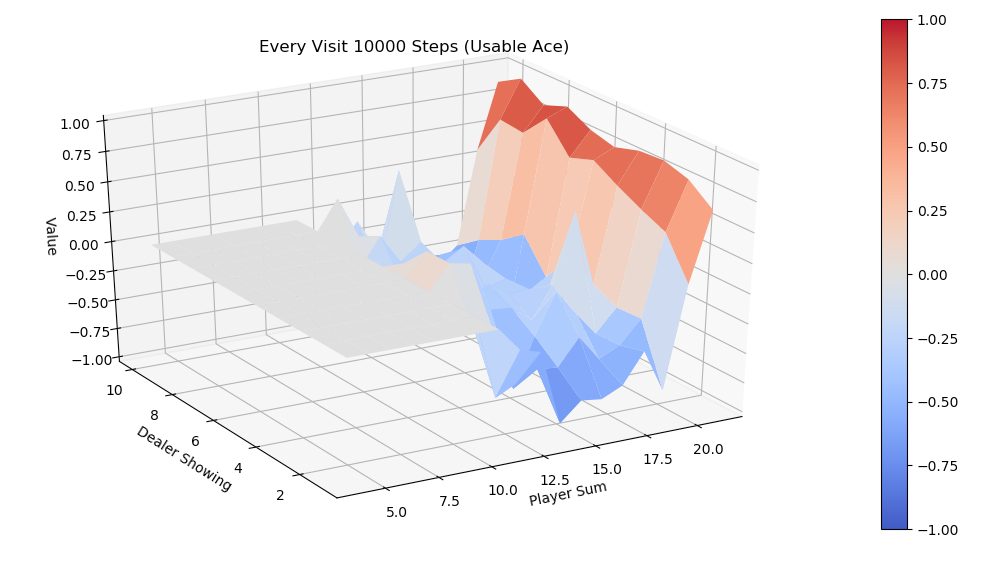
下面的两张图画出了运行代码10,000,000次episode后 \(\pi{*}\)的V值图。
MC ES 10M的最佳V值(有Ace)
MC ES 10M的最佳V值(无Ace)
Exploring Starts
蒙特卡洛控制改进
为了避免Monte Carlo ES
Control在初始时必须访问到任意状态的限制,教材中介绍了一种改进算法,On-policy
first-visit MC control for \(\epsilon
\text{-soft policies}\) ,它同样基于Monte Carlo 预估Q值,但用
\(\epsilon \text{-soft}\)
策略来代替最有可能的action策略作为下一次迭代策略,\(\epsilon \text{-soft}\)
本质上来说就是对于任意动作都保留 \(\epsilon\)
小概率的访问可能,权衡了exploration和exploitation,由于每个动作都可能被无限次访问到,Explorting
Starts中的强制随机初始状态就可以去除了。Monte Carlo ES Control 和
On-policy first-visit MC control for \(\epsilon \text{-soft policies}\)
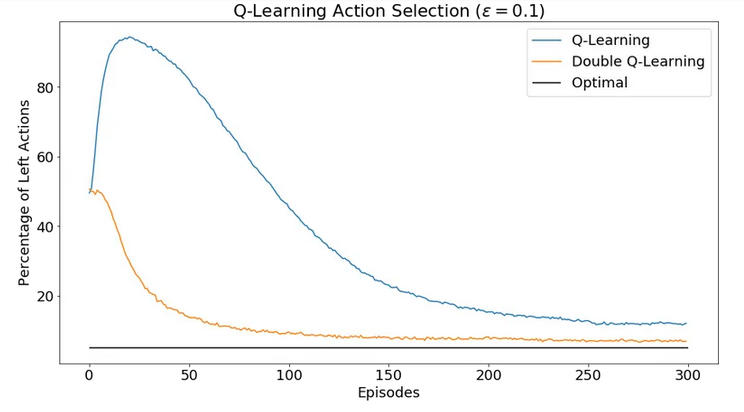
都属于on-policy算法,其区别于off-policy的本质在于预估 \(q_{\pi}(s,a)\)时是否从同策略\(\pi\)生成的数据来计算。一个比较subtle的例子是著名的Q-Learning,因为根据这个定义,Q-Learning属于off-policy。
\[
\begin{align*}
&\textbf{On-policy first-visit MC control (for }\epsilon
\textbf{-soft policies), estimating } \pi \approx \pi_{*} \\
& \text{Algorithm parameter: small } \epsilon > 0 \\
& \text{Initialize:} \\
& \quad \pi \leftarrow \text{ an arbitrary } \epsilon \text{-soft
policy} \\
& \quad Q(s, a) \in \mathbb R \text{, arbitrarily, for all }s \in
\mathcal{S}, a \in \mathcal A(s) \\
& \quad Returns(s, a) \leftarrow \text{ an empty list, for all }s
\in \mathcal{S}, a \in \mathcal A(s)\\
& \\
& \text{Repeat forever (for episode):}\\
& \quad \text{Generate an episode following } \pi : S_0, A_0, R_1,
S_1, A_1, R_2, ..., S_{T-1}, A_{T-1}, R_T\\
& \quad G \leftarrow 0\\
& \quad \text{Loop for each step of episode, } t = T-1, T-2, ...,
0:\\
& \quad \quad \quad G \leftarrow \gamma G + R_{t+1}\\
& \quad \quad \quad \text{Unless the pair } S_t, A_t \text{ appears
in } S_0, A_0, S_1, A_1, ..., S_{t-1}, A_{t-1}\\
& \quad \quad \quad \quad \text{Append } G \text { to }Returns(S_t,
A_t) \\
& \quad \quad \quad \quad Q(S_t, A_t) \leftarrow
\operatorname{average}(Returns(S_t, A_t))\\
& \quad \quad \quad \quad A^{*} \leftarrow \operatorname{argmax}_a
Q(S_t, a)\\
& \quad \quad \quad \quad \text{For all } a \in \mathcal A(S_t):\\
& \quad \quad \quad \quad \quad \pi(a|S_t) \leftarrow
\begin{cases}
1 - \epsilon + \epsilon / |\mathcal A(S_t)| & \text{ if } a =
A^{*}\\
\epsilon / |\mathcal A(S_t)| & \text{ if } a \neq A^{*}\\
\end{cases} \\
\end{align*}
\]
for episode_i inrange(1, num_episodes + 1): episode_history = gen_stochastic_episode(policy, env)
G = 0 for t inrange(len(episode_history) - 1, -1, -1): s, a, r = episode_history[t] G = discount_factor * G + r ifnotany(s_a_r[0] == s and s_a_r[1] == a for s_a_r in episode_history[0: t]): returns_sum[s, a] += G returns_count[s, a] += 1.0 Q[s][a] = returns_sum[s, a] / returns_count[s, a] update_epsilon_greedy_policy(policy, Q, s)
已发的牌的无状态性:和一副牌的21点游戏不同的是,游戏环境简化为牌是可以无穷尽被补充的,一副牌的某一张被派发后,同样的牌会被补充进来,或者可以认为每次发放的牌都是从一副新牌中抽出的。统计学中的术语称为重复采样(sample
with replacement)。这种规则下极端情况下,玩家可以拥有
5个A或者5个2。另外,这会导致玩家无法通过开局看到的3张牌的信息推断后续发牌的概率,如此就大规模减小了游戏状态数。
defstep(self, action): assert self.action_space.contains(action) if action: # hit: add a card to players hand and return self.player.append(draw_card(self.np_random)) if is_bust(self.player): done = True reward = -1. else: done = False reward = 0. else: # stick: play out the dealers hand, and score done = True while sum_hand(self.dealer) < 17: self.dealer.append(draw_card(self.np_random)) reward = cmp(score(self.player), score(self.dealer)) if self.natural and is_natural(self.player) and reward == 1.: reward = 1.5 return self._get_obs(), reward, done, {}
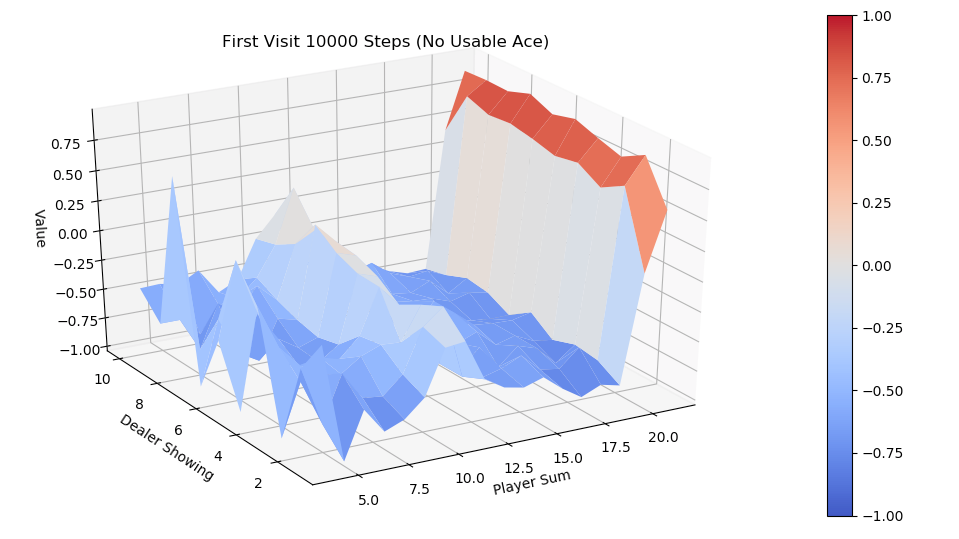
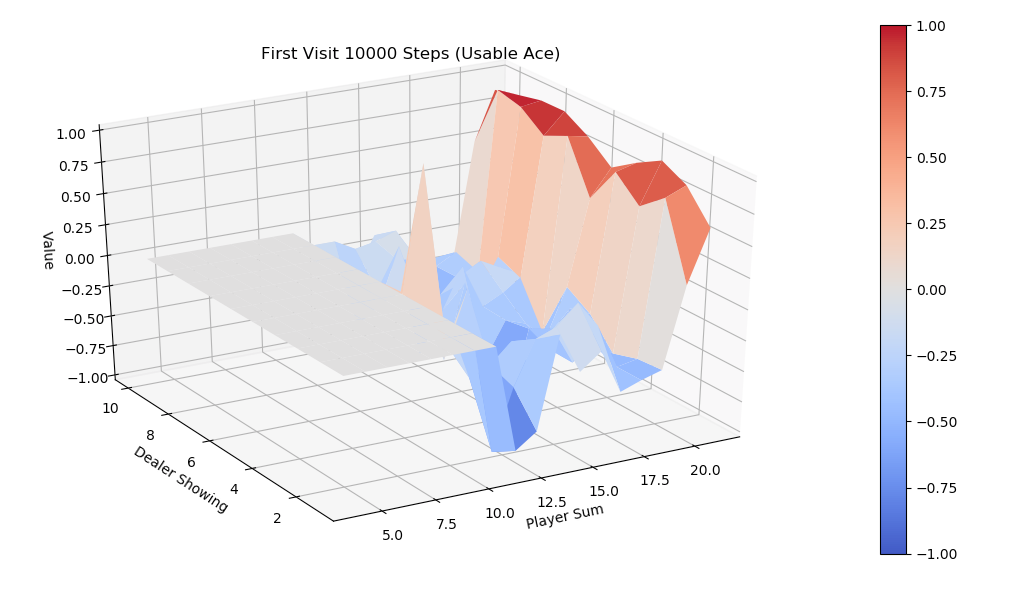
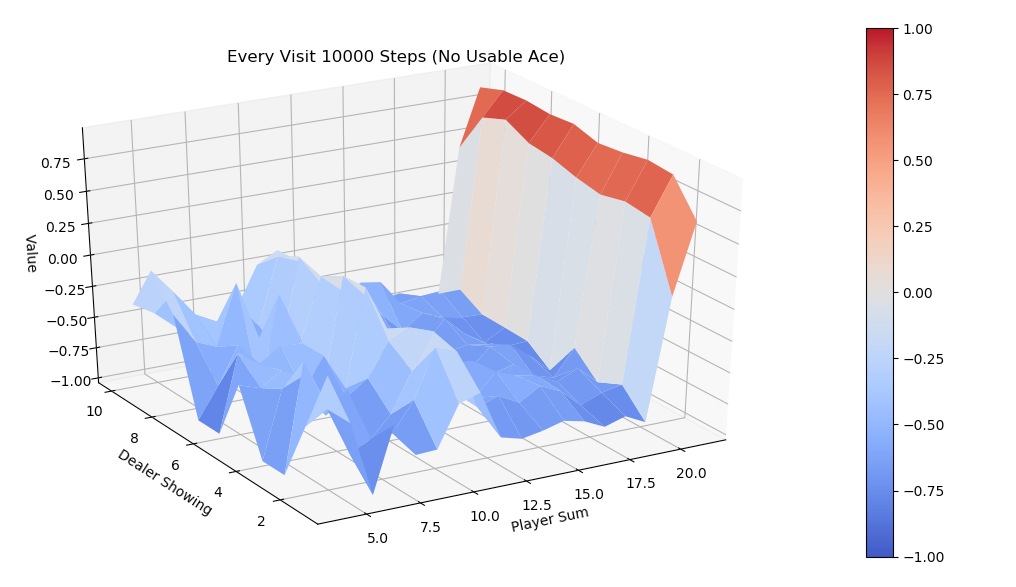
Monte Carlo Prediction解决如下问题:当给定Agent 策略\(\pi\)时,反复试验来预估策略的 \(V_{\pi}\)
值。具体来说,产生一系列的episode数据之后,对于出现了的所有状态分别计算其Return,再通过
average 某一状态 s 的Return来估计 \(V_{\pi}(s)\),理论上,依据大数定理(Law of
large numbers),在可以无限模拟的情况下,Monte Carlo prediction
一定会收敛到真实的 \(V_{\pi}\)。算法实现上有两个略微不同的版本,一个版本称为
First-visit,另一个版本称为 Every-visit,区别在于如何计算出现的状态 s 的
Return值。
对于 First-visit 来说,当状态 s 第一次出现时计算一次
Returns,若继续出现状态 s 不再重复计算。对于Every-visit来说,每次出现 s
计算一次 Returns(s)。举个例子,某episode 数据如下: \[
S_1, R_1, S_2, R_2, S_1, R_3, S_3, R_4
\] First-visit 对于状态S1的Returns计算为
deffixed_policy(observation): """ sticks if the player score is >= 20 and hits otherwise. """ score, dealer_score, usable_ace = observation return0if score >= 20else1
for episode_i inrange(1, num_episodes + 1): episode_history = gen_episode_data(policy, env)
G = 0 for t inrange(len(episode_history) - 1, -1, -1): s, a, r = episode_history[t] G = discount_factor * G + r ifnotany(s_a_r[0] == s for s_a_r in episode_history[0: t]): returns_sum[s] += G returns_count[s] += 1.0
V = defaultdict(float) V.update({s: returns_sum[s] / returns_count[s] for s in returns_sum.keys()}) return V
for episode_i inrange(1, num_episodes + 1): episode_history = gen_episode_data(policy, env)
G = 0 for t inrange(len(episode_history) - 1, -1, -1): s, a, r = episode_history[t] G = discount_factor * G + r returns_sum[s] += G returns_count[s] += 1.0
V = defaultdict(float) V.update({s: returns_sum[s] / returns_count[s] for s in returns_sum.keys()}) return V
for (int bitset_num = N; bitset_num >=0; bitset_num++) { while(hasNextCombination(bitset_num)) { int state = nextCombination(bitset_num); // compute dp[state][v], v-th bit is set in state for (int v = 0; v < n; v++) { for (int u = 0; u < n; u++) { // for each u not reached by this state if (!include(state, u)) { dp[state][v] = min(dp[state][v], dp[new_state_include_u][u] + dist[v][u]); } } } } }
ret: float = FLOAT_INF u_min: int = -1 for u inrange(self.g.v_num): if (state & (1 << u)) == 0: s: float = self._recurse(u, state | 1 << u) if s + edges[v][u] < ret: ret = s + edges[v][u] u_min = u dp[state][v] = ret self.parent[state][v] = u_min
当最终最短行程确定后,根据parent的信息可以按图索骥找到完整的行程顶点信息。
{linenos
1 2 3 4 5 6 7 8 9
def_form_tour(self): self.tour = [0] bit = 0 v = 0 for _ inrange(self.g.v_num - 1): v = self.parent[bit][v] self.tour.append(v) bit = bit | (1 << v) self.tour.append(0)
V = np.zeros(env.nS) changed_state_set = set(s for s inrange(env.nS))
iter = 0 whilelen(changed_state_set) > 0: changed_state_set_ = set() for s in changed_state_set: action_values = action_value(env, s, V, gamma=gamma) best_action_value = np.max(action_values) v_diff = np.abs(best_action_value - V[s]) if v_diff > theta: changed_state_set_.update(mapping[s]) V[s] = best_action_value changed_state_set = changed_state_set_ iter += 1
policy = np.zeros([env.nS, env.nA]) for s inrange(env.nS): action_values = action_value(env, s, V, gamma=gamma) best_action = np.argmax(action_values) policy[s, best_action] = 1.0
return policy, V
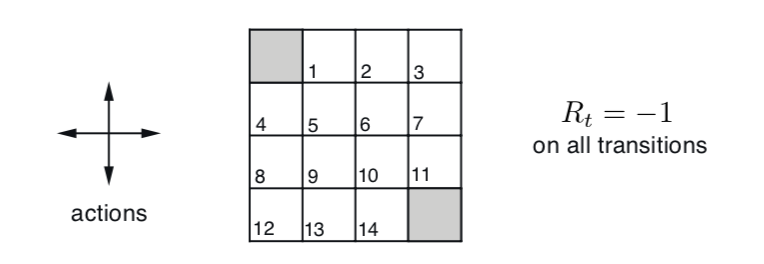
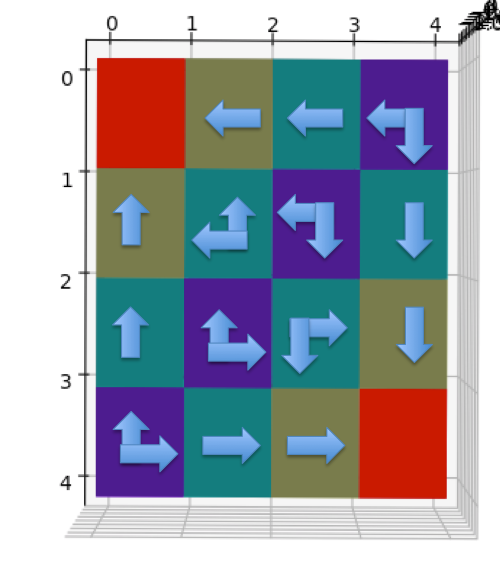
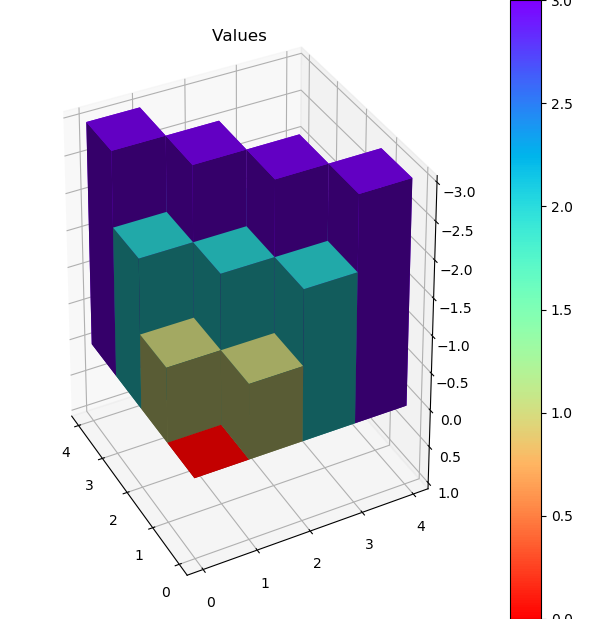
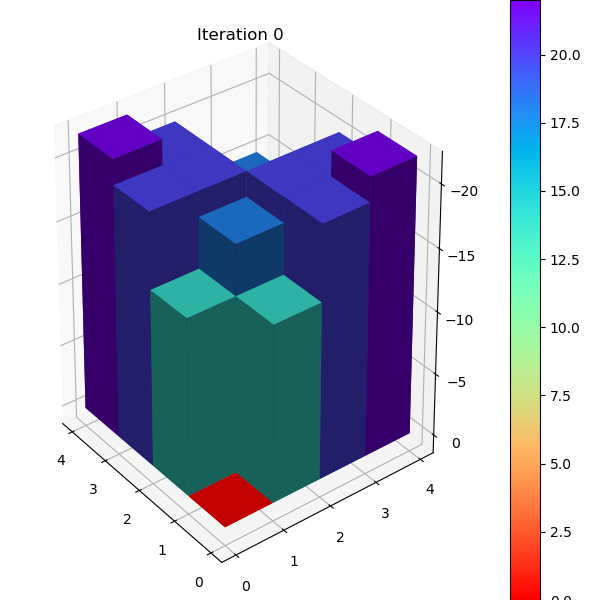
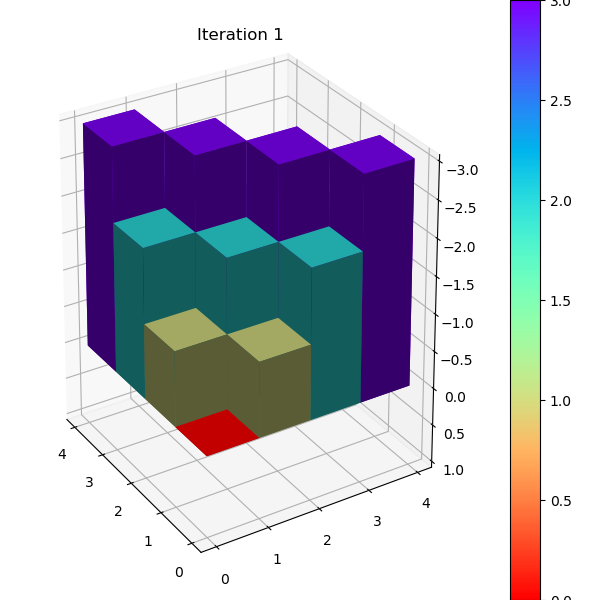
比较值迭代和异步值迭代方法后发现,值迭代用了4次循环,每次涉及所有状态,总计算状态数为
4 x 16 = 64。异步值迭代也用了4次循环,但是总计更新了54个状态。由于Grid
World
的状态数很少,异步值迭代优势并不明显,但是对于状态数众多并且迭代最终集中在少部分状态的环境下,节省的计算量还是很可观的。