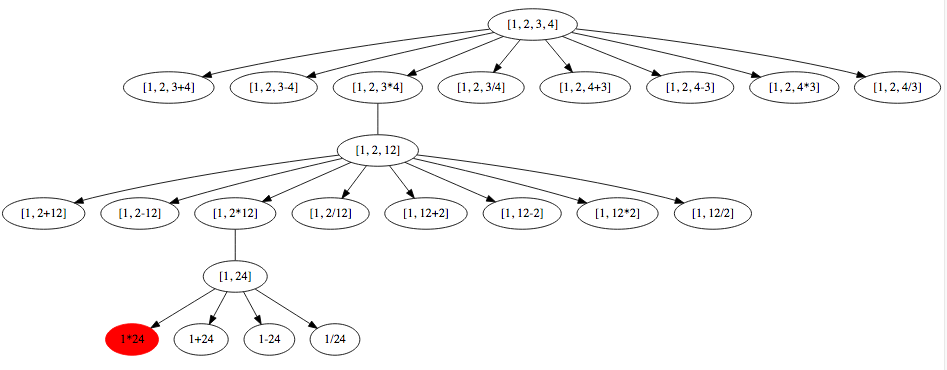
Leetcode 679 24 Game
(Hard) > You have 4 cards each containing a number from 1 to 9.
You need to judge whether they could operated through *, /, +, -, (, )
to get the value of 24.
# AC # Runtime: 36 ms, faster than 91.78% of Python3 online submissions for Permutations. # Memory Usage: 13.9 MB, less than 66.52% of Python3 online submissions for Permutations.
from itertools import permutations from typing importList
classSolution: defpermute(self, nums: List[int]) -> List[List[int]]: return [p for p in permutations(nums)]
# AC # Runtime: 84 ms, faster than 95.43% of Python3 online submissions for Combinations. # Memory Usage: 15.2 MB, less than 68.98% of Python3 online submissions for Combinations. from itertools import combinations from typing importList
classSolution: defcombine(self, n: int, k: int) -> List[List[int]]: return [c for c in combinations(list(range(1, n + 1)), k)]
itertools.product
当有多维度的对象需要迭代笛卡尔积时,可以用 product(iter1, iter2,
...)来生成generator,等价于多重 for 循环。
1 2
[lst for lst in product([1, 2, 3], ['a', 'b'])] [(i, s) for i in [1, 2, 3] for s in ['a', 'b']]
Given a string containing digits from 2-9 inclusive, return all
possible letter combinations that the number could represent. A mapping
of digit to letters (just like on the telephone buttons) is given below.
Note that 1 does not map to any letters.
# AC # Runtime: 24 ms, faster than 94.50% of Python3 online submissions for Letter Combinations of a Phone Number. # Memory Usage: 13.7 MB, less than 83.64% of Python3 online submissions for Letter Combinations of a Phone Number.
from itertools import product from typing importList
classSolution: defletterCombinations(self, digits: str) -> List[str]: if digits == "": return [] mapping = {'2':'abc', '3':'def', '4':'ghi', '5':'jkl', '6':'mno', '7':'pqrs', '8':'tuv', '9':'wxyz'} iter_dims = [mapping[i] for i in digits]
result = [] for lst in product(*iter_dims): result.append(''.join(lst))
The Fibonacci numbers, commonly denoted F(n) form a sequence, called
the Fibonacci sequence, such that each number is the sum of the two
preceding ones, starting from 0 and 1. That is, F(0) = 0, F(1) = 1 F(N)
= F(N - 1) + F(N - 2), for N > 1. Given N, calculate F(N).
# AC # Runtime: 28 ms, faster than 85.56% of Python3 online submissions for Fibonacci Number. # Memory Usage: 13.8 MB, less than 58.41% of Python3 online submissions for Fibonacci Number.
classSolution: deffib(self, N: int) -> int: if N <= 1: return N i = 2 for fib in self.fib_next(): if i == N: return fib i += 1 deffib_next(self): f_last2, f_last = 0, 1 whileTrue: f = f_last2 + f_last f_last2, f_last = f_last, f yield f
yield from 示例
上述yield用法之后,再来演示 yield from 的用法。Yield from 始于Python
3.3,用于嵌套generator时的控制转移,一种典型的用法是有多个generator嵌套时,外层的outer_generator
用 yield from 这种方式等价代替如下代码。
1 2 3
defouter_generator(): for i in inner_generator(): yield i
# AC # Runtime: 48 ms, faster than 90.31% of Python3 online submissions for Kth Smallest Element in a BST. # Memory Usage: 17.9 MB, less than 14.91% of Python3 online submissions for Kth Smallest Element in a BST.
classSolution: defkthSmallest(self, root: TreeNode, k: int) -> int: defordered_iter(node): if node: for sub_node in ordered_iter(node.left): yield sub_node yield node for sub_node in ordered_iter(node.right): yield sub_node
for node in ordered_iter(root): k -= 1 if k == 0: return node.val
等价于如下 yield from 版本:
{linenos
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
# AC # Runtime: 56 ms, faster than 63.74% of Python3 online submissions for Kth Smallest Element in a BST. # Memory Usage: 17.7 MB, less than 73.33% of Python3 online submissions for Kth Smallest Element in a BST.
# AC # Runtime: 112 ms, faster than 57.59% of Python3 online submissions for 24 Game. # Memory Usage: 13.7 MB, less than 85.60% of Python3 online submissions for 24 Game.
import math from itertools import permutations, product from typing importList
defjudgePoint24(self, nums: List[int]) -> bool: mul = lambda x, y: x * y plus = lambda x, y: x + y div = lambda x, y: x / y if y != 0else math.inf minus = lambda x, y: x - y
op_lst = [plus, minus, mul, div]
for ops in product(op_lst, repeat=3): for val in permutations(nums): for v in self.iter_trees(ops[0], ops[1], ops[2], val[0], val[1], val[2], val[3]): ifabs(v - 24) < 0.0001: returnTrue returnFalse
# AC # Runtime: 116 ms, faster than 56.23% of Python3 online submissions for 24 Game. # Memory Usage: 13.9 MB, less than 44.89% of Python3 online submissions for 24 Game.
import math from itertools import combinations, product, permutations from typing importList
classSolution:
defjudgePoint24(self, nums: List[int]) -> bool: mul = lambda x, y: x * y plus = lambda x, y: x + y div = lambda x, y: x / y if y != 0else math.inf minus = lambda x, y: x - y
op_lst = [plus, minus, mul, div]
defrecurse(lst: List[int]): iflen(lst) == 2: for op, values in product(op_lst, permutations(lst)): yield op(values[0], values[1]) else: # choose 2 indices from lst of length n for choosen_idx_lst in combinations(list(range(len(lst))), 2): # remaining indices not choosen (of length n-2) idx_remaining_set = set(list(range(len(lst)))) - set(choosen_idx_lst)
# remaining values not choosen (of length n-2) value_remaining_lst = list(map(lambda x: lst[x], idx_remaining_set)) for op, idx_lst in product(op_lst, permutations(choosen_idx_lst)): # 2 choosen values are lst[idx_lst[0]], lst[idx_lst[1] value_remaining_lst.append(op(lst[idx_lst[0]], lst[idx_lst[1]])) yieldfrom recurse(value_remaining_lst) value_remaining_lst = value_remaining_lst[:-1]
for v in recurse(nums): ifabs(v - 24) < 0.0001: returnTrue
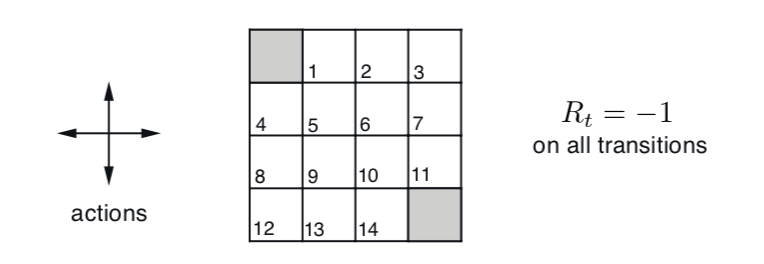
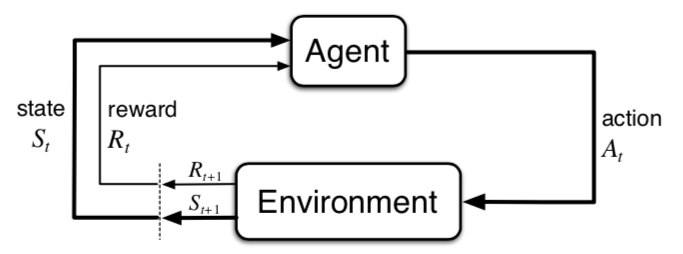
经典教材Reinforcement Learning: An Introduction
第二版由强化领域权威Richard S. Sutton 和 Andrew G. Barto
完成编写,内容深入浅出,非常适合初学者。在本篇中,引入Grid
World示例,结合强化学习核心概念,并用python代码实现OpenAI
Gym的模拟环境,进一步实现策略评价算法。
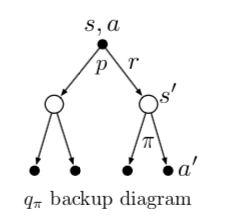
即是四元组作为输入的概率函数 \(p: S \times
R \times S \times A \rightarrow [0, 1]\)。
满足 \[
\sum_{s^{\prime} \in \mathcal{S}} \sum_{r \in \mathcal{R}}
p\left(s^{\prime}, r \mid s, a\right)=1, \text { for all } s \in
\mathcal{S}, a \in \mathcal{A}(s)
\]
\[
q_{\pi}(s, a) \doteq \mathbb{E}_{\pi}\left[G_{t} \mid S_{t}=s,
A_{t}=a\right]
\]
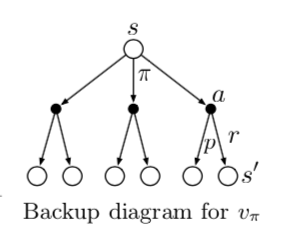
下面是 $q_{}(s, a) $ 的递推 backup diagram。
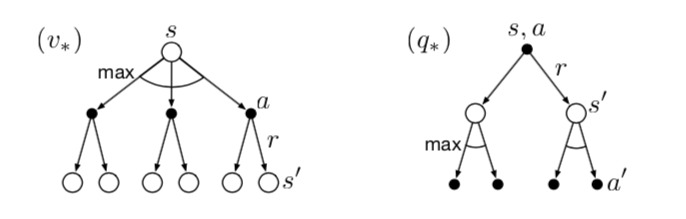
Bellman 最佳原则
对于所有状态集合\(\mathcal{S}\),策略\({\pi}\)的评价指标 \(v_{\pi}(s)\)
是一个向量,本质上是无法相互比较的。但由于存在Bellman
最佳原则(Bellman's principle of
optimality):在有限状态情况下,一定存在一个或者多个最好的策略 \({\pi}_{*}\),它在所有状态下的v值都是最好的,即
\(v_{\pi_{*}}(s) \ge v_{\pi^{\prime}}(s) \text
{ for all } s \in \mathcal{S}\)。
因此,最佳v值定义为最佳策略 \({\pi}_{*}\) 对应的 v 值
\[
v_{*}(s) \doteq \max_{\pi} v_{\pi}(s)
\]
同理,也存在最佳q值,记为 \[
\begin{aligned}
q_{*}(s, a) &\doteq \max_{\pi} q_{\pi}(s,a)
\end{aligned}
\]
旅行商问题(TSP)是计算机算法中经典的NP
hard 问题。 在本系列文章中,我们将首先使用动态规划 AC
aizu中的TSP问题,然后再利用深度学习求大规模下的近似解。深度学习应用解决问题时先以PyTorch实现监督学习算法
Pointer Network,进而结合强化学习来无监督学习,提高数据使用效率。
本系列完整列表如下:
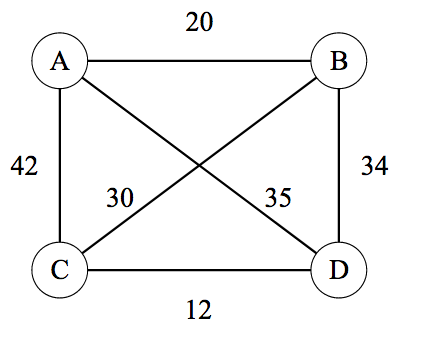
TSP可以用图模型来表达,无论有向图或无向图,无论全连通图或者部分连通的图都可以作为TSP问题。
Wikipedia
TSP
中举了一个无向全连通的TSP例子。如下图所示,四个顶点A,B,C,D构成无向全连通图。TSP问题要求在所有遍历所有点后返回初始点的回路中找到最短的回路。例如,\(A \rightarrow B \rightarrow C \rightarrow D
\rightarrow A\) 和 \(A \rightarrow C
\rightarrow B \rightarrow D \rightarrow A\)
都是有效的回路,但是TSP需要返回这些回路中的最短回路(注意,最短回路可能会有多条)。
publicGraph(int V_NUM){ this.V_NUM = V_NUM; this.edges = newint[V_NUM][V_NUM]; for (int i = 0; i < V_NUM; i++) { Arrays.fill(this.edges[i], Integer.MAX_VALUE); } } publicvoidsetDist(int src, int dest, int dist){ this.edges[src][dest] = dist; } } publicstaticclassTSP{ publicfinal Graph g; long[][] dp; publicTSP(Graph g){ this.g = g; } publiclongsolve(){ int N = g.V_NUM; dp = newlong[1 << N][N]; for (int i = 0; i < dp.length; i++) { Arrays.fill(dp[i], -1); } long ret = recurse(0, 0); return ret == Integer.MAX_VALUE ? -1 : ret; } privatelongrecurse(int state, int v){ int ALL = (1 << g.V_NUM) - 1; if (dp[state][v] >= 0) { return dp[state][v]; } if (state == ALL && v == 0) { dp[state][v] = 0; return0; } long res = Integer.MAX_VALUE; for (int u = 0; u < g.V_NUM; u++) { if ((state & (1 << u)) == 0) { long s = recurse(state | 1 << u, u); res = Math.min(res, s + g.edges[v][u]); } } dp[state][v] = res; return res; } } publicstaticvoidmain(String[] args){ Scanner in = new Scanner(System.in); int V = in.nextInt(); int E = in.nextInt(); Graph g = new Graph(V); while (E > 0) { int src = in.nextInt(); int dest = in.nextInt(); int dist = in.nextInt(); g.setDist(src, dest, dist); E--; } System.out.println(new TSP(g).solve()); } }
def__init__(self, v_num: int): self.v_num = v_num self.edges = [[INT_INF for c inrange(v_num)] for r inrange(v_num)] defsetDist(self, src: int, dest: int, dist: int): self.edges[src][dest] = dist
classTSPSolver: g: Graph dp: List[List[int]]
def__init__(self, g: Graph): self.g = g self.dp = [[Nonefor c inrange(g.v_num)] for r inrange(1 << g.v_num)] defsolve(self) -> int: return self._recurse(0, 0) def_recurse(self, v: int, state: int) -> int: """ :param v: :param state: :return: -1 means INF """ dp = self.dp edges = self.g.edges if dp[state][v] isnotNone: return dp[state][v] if (state == (1 << self.g.v_num) - 1) and (v == 0): dp[state][v] = 0 return dp[state][v] ret: int = INT_INF for u inrange(self.g.v_num): if (state & (1 << u)) == 0: s: int = self._recurse(u, state | 1 << u) if s != INT_INF and edges[v][u] != INT_INF: if ret == INT_INF: ret = s + edges[v][u] else: ret = min(ret, s + edges[v][u]) dp[state][v] = ret return ret
defsimulate_bruteforce(n: int) -> bool: """ Simulates one round. Unbounded time complexity. :param n: total number of seats :return: True if last one has last seat, otherwise False """
seats = [Falsefor _ inrange(n)]
for i inrange(n-1): if i == 0: # first one, always random seats[random.randint(0, n - 1)] = True else: ifnot seats[i]: # i-th has his seat seats[i] = True else: whileTrue: rnd = random.randint(0, n - 1) # random until no conflicts ifnot seats[rnd]: seats[rnd] = True break returnnot seats[n-1]
defsimulate_online(n: int) -> bool: """ Simulates one round of complexity O(N). :param n: total number of seats :return: True if last one has last seat, otherwise False """
# for each person, the seats array idx available are [i, n-1] for i inrange(n-1): if i == 0: # first one, always random rnd = random.randint(0, n - 1) swap(rnd, 0) else: if seats[i] == i: # i-th still has his seat pass else: rnd = random.randint(i, n - 1) # selects idx from [i, n-1] swap(rnd, i) return seats[n-1] == n - 1
递推思维
这一节我们用数学递推思维来解释0.5的解。令f(n) 为第 n
位乘客坐在自己的座位上的概率,考察第一个人的情况(first step
analysis),有三种可能
这种思想可以写出如下代码,seats为 n 大小的bool
数组,当第i个人(0<i<n)发现自己座位被占的话,此时必然seats[0]没有被占,同时seats[i+1:]都是空的。假设seats[0]被占的话,要么是第一个人占的,要么是第p个人(p<i)坐了,两种情况下乱序都已经恢复了,此时第i个座位一定是空的。
defsimulate(n: int) -> bool: """ Simulates one round of complexity O(N). :param n: total number of seats :return: True if last one has last seat, otherwise False """
seats = [Falsefor _ inrange(n)]
for i inrange(n-1): if i == 0: # first one, always random rnd = random.randint(0, n - 1) seats[rnd] = True else: ifnot seats[i]: # i-th still has his seat seats[i] = True else: # 0 must not be available, now we have 0 and [i+1, n-1], rnd = random.randint(i, n - 1) if rnd == i: seats[0] = True else: seats[rnd] = True returnnot seats[n-1]
defreset(self) -> ConnectNGame: """Resets the state of the environment and returns an initial observation. Returns: observation (object): the initial observation. """ raise NotImplementedError
defstep(self, action: Tuple[int, int]) -> Tuple[ConnectNGame, int, bool, None]: """Run one timestep of the environment's dynamics. When end of episode is reached, you are responsible for calling `reset()` to reset this environment's state. Accepts an action and returns a tuple (observation, reward, done, info). Args: action (object): an action provided by the agent Returns: observation (object): agent's observation of the current environment reward (float) : amount of reward returned after previous action done (bool): whether the episode has ended, in which case further step() calls will return undefined results info (dict): contains auxiliary diagnostic information (helpful for debugging, and sometimes learning) """ raise NotImplementedError
defrender(self, mode='human'): """ Renders the environment. The set of supported modes varies per environment. (And some environments do not support rendering at all.) By convention, if mode is: - human: render to the current display or terminal and return nothing. Usually for human consumption. - rgb_array: Return an numpy.ndarray with shape (x, y, 3), representing RGB values for an x-by-y pixel image, suitable for turning into a video. - ansi: Return a string (str) or StringIO.StringIO containing a terminal-style text representation. The text can include newlines and ANSI escape sequences (e.g. for colors). Note: Make sure that your class's metadata 'render.modes' key includes the list of supported modes. It's recommended to call super() in implementations to use the functionality of this method. Args: mode (str): the mode to render with """ raise NotImplementedError
defaction(self, game: ConnectNGame) -> Tuple[int, Tuple[int, int]]: game = copy.deepcopy(game)
player = game.currentPlayer bestResult = player * -1# assume opponent win as worst result bestMove = None for move in game.getAvailablePositions(): game.move(*move) status = game.getStatus() game.undo()
result = self.dpMap[status]
if player == ConnectNGame.PLAYER_A: bestResult = max(bestResult, result) else: bestResult = min(bestResult, result) # update bestMove if any improvement bestMove = move if bestResult == result else bestMove print(f'move {move} => {result}')
classSolution: deftictactoe(self, moves: List[List[int]]) -> str: board = [[0] * 3for _ inrange(3)] for idx, xy inenumerate(moves): player = 1if idx % 2 == 0else -1 board[xy[0]][xy[1]] = player
turn = 0 row, col = [0, 0, 0], [0, 0, 0] diag1, diag2 = False, False for r inrange(3): for c inrange(3): turn += board[r][c] row[r] += board[r][c] col[c] += board[r][c] if r == c: diag1 += board[r][c] if r + c == 2: diag2 += board[r][c]
oWin = any(row[r] == 3for r inrange(3)) orany(col[c] == 3for c inrange(3)) or diag1 == 3or diag2 == 3 xWin = any(row[r] == -3for r inrange(3)) orany(col[c] == -3for c inrange(3)) or diag1 == -3or diag2 == -3
if (north + south + 1 >= 3) or (east + west + 1 >= 3) or \ (south_east + north_west + 1 >= 3) or (north_east + south_west + 1 >= 3): returnTrue returnFalse
defgetConnectedNum(self, r: int, c: int, dr: int, dc: int) -> int: player = self.board[r][c] result = 0 i = 1 whileTrue: new_r = r + dr * i new_c = c + dc * i if0 <= new_r < 3and0 <= new_c < 3: if self.board[new_r][new_c] == player: result += 1 else: break else: break i += 1 return result
deftictactoe(self, moves: List[List[int]]) -> str: self.board = [[0] * 3for _ inrange(3)] for idx, xy inenumerate(moves): player = 1if idx % 2 == 0else -1 self.board[xy[0]][xy[1]] = player
# only check last move r, c = moves[-1] win = self.checkWin(r, c) if win: return"A"iflen(moves) % 2 == 1else"B"
def__init__(self, n:int): """ Initialize your data structure here. :type n: int """ self.row, self.col, self.diag1, self.diag2, self.n = [0] * n, [0] * n, 0, 0, n
defmove(self, row:int, col:int, player:int) -> int: """ Player {player} makes a move at ({row}, {col}). @param row The row of the board. @param col The column of the board. @param player The player, can be either 1 or 2. @return The current winning condition, can be either: 0: No one wins. 1: Player 1 wins. 2: Player 2 wins. """ if player == 2: player = -1
self.row[row] += player self.col[col] += player if row == col: self.diag1 += player if row + col == self.n - 1: self.diag2 += player
if self.n in [self.row[row], self.col[col], self.diag1, self.diag2]: return1 if -self.n in [self.row[row], self.col[col], self.diag1, self.diag2]: return2 return0
井字棋最佳策略
井字棋的规模可以很自然的扩展成四子棋或五子棋等,区别在于棋盘大小和胜利时的连子数量。这类游戏最一般的形式为
M,n,k-game,中文可能翻译为战略井字游戏,表示棋盘大小为M
x N,当k连子时获胜。
下面的ConnectNGame类实现了战略井字游戏(M=N)中,两个玩家轮流下子、更新棋盘状态和判断每次落子输赢等逻辑封装。其中undo方法用于撤销最后一个落子,方便在后续寻找最佳策略时回溯。
defgetAvailablePositions(self) -> List[Tuple[int, int]]: return [(i,j) for i inrange(self.board_size) for j inrange(self.board_size) if self.board[i][j] == ConnectNGame.AVAILABLE]
defgetStatus(self) -> Tuple[Tuple[int, ...]]: returntuple([tuple(self.board[i]) for i inrange(self.board_size)])
defminimax(self) -> Tuple[int, Tuple[int, int]]: game = self.game bestMove = None assertnot game.gameOver if game.currentPlayer == ConnectNGame.PLAYER_A: ret = -math.inf for pos in game.getAvailablePositions(): move = pos result = game.move(*pos) if result isNone: assertnot game.gameOver result, oppMove = self.minimax() game.undo() ret = max(ret, result) bestMove = move if ret == result else bestMove if ret == 1: return1, move return ret, bestMove else: ret = math.inf for pos in game.getAvailablePositions(): move = pos result = game.move(*pos) if result isNone: assertnot game.gameOver result, oppMove = self.minimax() game.undo() ret = min(ret, result) bestMove = move if ret == result else bestMove if ret == -1: return -1, move return ret, bestMove
if gameStatus in self.dpMap: return self.dpMap[gameStatus]
game = self.game bestMove = None assertnot game.gameOver if game.currentPlayer == ConnectNGame.PLAYER_A: ret = -math.inf for pos in game.getAvailablePositions(): move = pos result = game.move(*pos) if result isNone: assertnot game.gameOver result, oppMove = self.minimax(game.getStatus()) self.dpMap[game.getStatus()] = result, oppMove else: self.dpMap[game.getStatus()] = result, move game.undo() ret = max(ret, result) bestMove = move if ret == result else bestMove self.dpMap[gameStatus] = ret, bestMove return ret, bestMove else: ret = math.inf for pos in game.getAvailablePositions(): move = pos result = game.move(*pos)
if result isNone: assertnot game.gameOver result, oppMove = self.minimax(game.getStatus()) self.dpMap[game.getStatus()] = result, oppMove else: self.dpMap[game.getStatus()] = result, move game.undo() ret = min(ret, result) bestMove = move if ret == result else bestMove self.dpMap[gameStatus] = ret, bestMove return ret, bestMove
if __name__ == '__main__': tic_tac_toe = ConnectNGame(N=3, board_size=3) strategy = CountingMinimaxStrategy() strategy.action(tic_tac_toe) print(f'Game States Number {len(strategy.dpMap)}')
defalpha_beta(self, gameStatus: Tuple[Tuple[int, ...]], alpha:int=None, beta:int=None) -> Tuple[int, Tuple[int, int]]: game = self.game bestMove = None assertnot game.gameOver if game.currentPlayer == ConnectNGame.PLAYER_A: ret = -math.inf for pos in game.getAvailablePositions(): move = pos result = game.move(*pos) if result isNone: assertnot game.gameOver result, oppMove = self.alpha_beta(game.getStatus(), alpha, beta) game.undo() alpha = max(alpha, result) ret = max(ret, result) bestMove = move if ret == result else bestMove if alpha >= beta or ret == 1: return ret, move return ret, bestMove else: ret = math.inf for pos in game.getAvailablePositions(): move = pos result = game.move(*pos) if result isNone: assertnot game.gameOver result, oppMove = self.alpha_beta(game.getStatus(), alpha, beta) game.undo() beta = min(beta, result) ret = min(ret, result) bestMove = move if ret == result else bestMove if alpha >= beta or ret == -1: return ret, move return ret, bestMove
@lru_cache(maxsize=None) defalpha_beta_dp(self, gameStatus: Tuple[Tuple[int, ...]]) -> Tuple[int, Tuple[int, int]]: alpha, beta = self.alphaBetaStack[-1] game = self.game bestMove = None assertnot game.gameOver if game.currentPlayer == ConnectNGame.PLAYER_A: ret = -math.inf for pos in game.getAvailablePositions(): move = pos result = game.move(*pos) if result isNone: assertnot game.gameOver self.alphaBetaStack.append((alpha, beta)) result, oppMove = self.alpha_beta_dp(game.getStatus()) self.alphaBetaStack.pop() game.undo() alpha = max(alpha, result) ret = max(ret, result) bestMove = move if ret == result else bestMove if alpha >= beta or ret == 1: return ret, move return ret, bestMove else: ret = math.inf for pos in game.getAvailablePositions(): move = pos result = game.move(*pos) if result isNone: assertnot game.gameOver self.alphaBetaStack.append((alpha, beta)) result, oppMove = self.alpha_beta_dp(game.getStatus()) self.alphaBetaStack.pop() game.undo() beta = min(beta, result) ret = min(ret, result) bestMove = move if ret == result else bestMove if alpha >= beta or ret == -1: return ret, move return ret, bestMove
# TLE # Time Complexity: O(exponential) classSolution_BruteForce:
defcanWinNim(self, n: int) -> bool: if n <= 3: returnTrue for i inrange(1, 4): ifnot self.canWinNim(n - i): returnTrue returnFalse
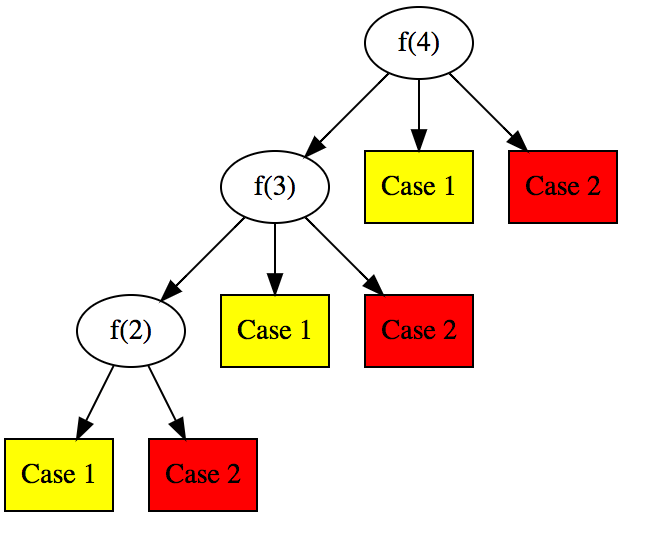
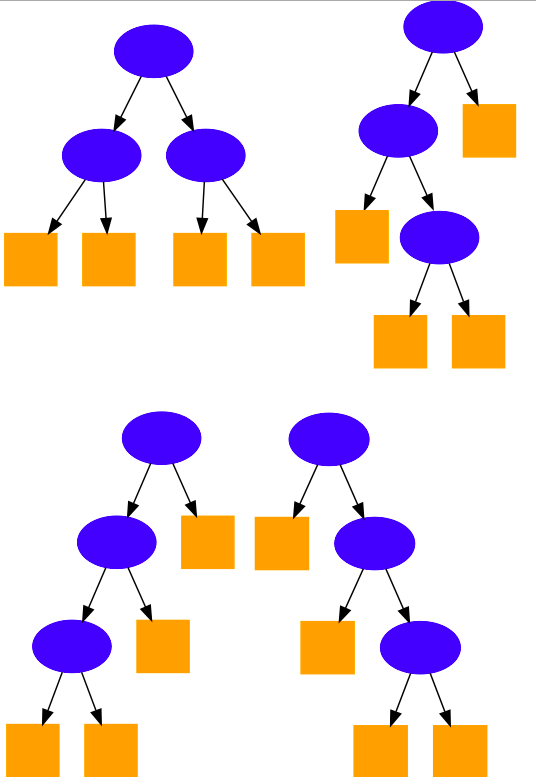
以上的递归公式和代码很像fibonacci数的递归定义和暴力解法,因此对应的时间复杂度也是指数级的,提交代码以后会TLE。下图画出了当n=7时的递归调用,注意
5 被扩展向下重复执行了两次,4重复了4次。
292 Nim Game 暴力解法调用图 n=7
我们采用和fibonacci一样的方式来优化算法:缓存较小n的结果以此来计算较大n的结果。
Python 中,我们可以只加一行lru_cache
decorator,来取得这种动态规划效果,下面的代码将复杂度降到了 \(O(N)\)。
{linenos
1 2 3 4 5 6 7 8 9 10 11 12
# RecursionError: maximum recursion depth exceeded in comparison n=1348820612 # Time Complexity: O(N) classSolution_DP: from functools import lru_cache @lru_cache(maxsize=None) defcanWinNim(self, n: int) -> bool: if n <= 3: returnTrue for i inrange(1, 4): ifnot self.canWinNim(n - i): returnTrue returnFalse
再来画出调用图:这次5和4就不再被展开重复计算,图中绿色的节点表示缓存命中。
292 Nim Game 动归解法调用图 n=7
# TLE for 1348820612 # Time Complexity: O(N) classSolution: defcanWinNim(self, n: int) -> bool: if n <= 3: returnTrue last3, last2, last1 = True, True, True for i inrange(4, n+1): this = not (last3 and last2 and last1) last3, last2, last1 = last2, last1, this return last1
defminimax(node: Node, depth: int, maximizingPlayer: bool) -> int: if depth == 0or is_terminal(node): return evaluate_terminal(node) if maximizingPlayer: value:int = −∞ for child in node: value = max(value, minimax(child, depth − 1, False)) return value else: # minimizing player value := +∞ for child in node: value = min(value, minimax(child, depth − 1, True)) return value
# AC classSolution: from functools import lru_cache @lru_cache(maxsize=None) # currentTotal < desiredTotal defminimax(self, status: int, currentTotal: int, isMaxPlayer: bool) -> int: import math if status == self.allUsed: return0# draw: no winner
if isMaxPlayer: value = -math.inf for i inrange(1, self.maxChoosableInteger + 1): ifnot (status >> i & 1): new_status = 1 << i | status if currentTotal + i >= self.desiredTotal: return1# shortcut value = max(value, self.minimax(new_status, currentTotal + i, not isMaxPlayer)) if value == 1: return1 return value else: value = math.inf for i inrange(1, self.maxChoosableInteger + 1): ifnot (status >> i & 1): new_status = 1 << i | status if currentTotal + i >= self.desiredTotal: return -1# shortcut value = min(value, self.minimax(new_status, currentTotal + i, not isMaxPlayer)) if value == -1: return -1 return value
# AC classSolution: from functools import lru_cache @lru_cache(maxsize=None) # currentTotal < desiredTotal defalpha_beta(self, status: int, currentTotal: int, isMaxPlayer: bool, alpha: int, beta: int) -> int: import math if status == self.allUsed: return0# draw: no winner
if isMaxPlayer: value = -math.inf for i inrange(1, self.maxChoosableInteger + 1): ifnot (status >> i & 1): new_status = 1 << i | status if currentTotal + i >= self.desiredTotal: return1# shortcut value = max(value, self.alpha_beta(new_status, currentTotal + i, not isMaxPlayer, alpha, beta)) alpha = max(alpha, value) if alpha >= beta: return value return value else: value = math.inf for i inrange(1, self.maxChoosableInteger + 1): ifnot (status >> i & 1): new_status = 1 << i | status if currentTotal + i >= self.desiredTotal: return -1# shortcut value = min(value, self.alpha_beta(new_status, currentTotal + i, not isMaxPlayer, alpha, beta)) beta = min(beta, value) if alpha >= beta: return value return value
// AC classSolution{ publicbooleanPredictTheWinner(int[] nums){ int n = nums.length; int[][] dp = newint[n][n]; for (int i = 0; i < n; i++) { dp[i][i] = nums[i]; }
for (int l = n - 1; l >= 0; l--) { for (int r = l + 1; r < n; r++) { dp[l][r] = Math.max( nums[l] - dp[l + 1][r], nums[r] - dp[l][r - 1]); } } return dp[0][n - 1] >= 0; } }
C++ AC Code
{linenos
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
// AC classSolution { public: boolPredictTheWinner(vector<int>& nums){ int n = nums.size(); vector<vector<int>> dp(n, vector<int>(n, 0)); for (int i = 0; i < n; i++) { dp[i][i] = nums[i]; } for (int l = n - 1; l >= 0; l--) { for (int r = l + 1; r < n; r++) { dp[l][r] = max(nums[l] - dp[l + 1][r], nums[r] - dp[l][r - 1]); } } return dp[0][n - 1] >= 0; } };
for (let i = 0; i < n; i++) { dp[i][i] = nums[i]; } for (let l = n - 1; l >=0; l--) { for (let r = i + 1; r < n; r++) { dp[l][r] = Math.max(nums[l] - dp[l + 1][r],nums[r] - dp[l][r - 1]); } } return dp[0][n-1] >=0; };







.png)
.png)