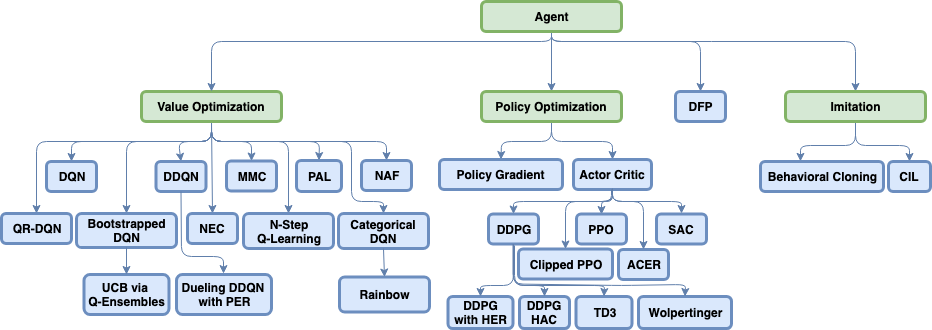
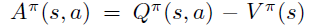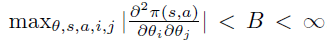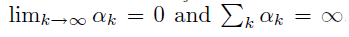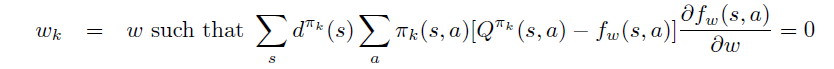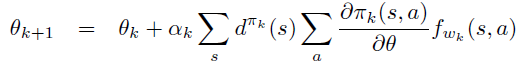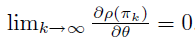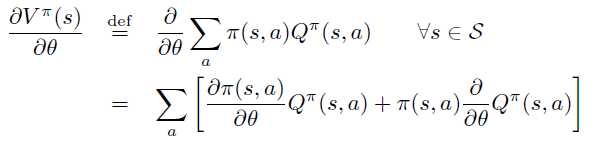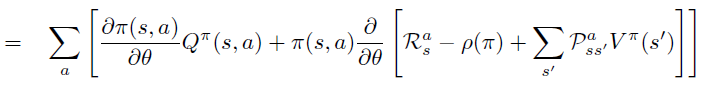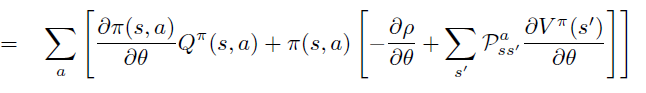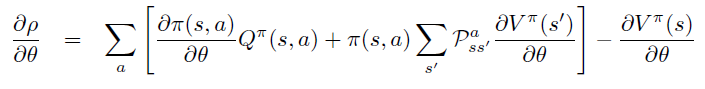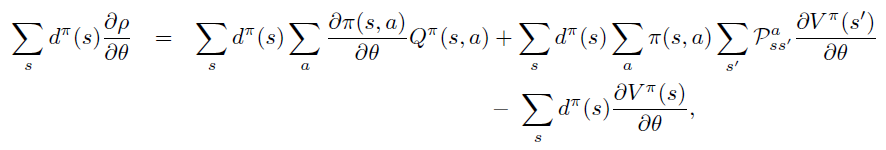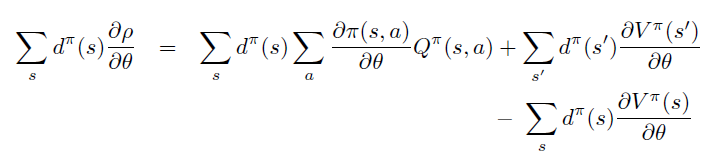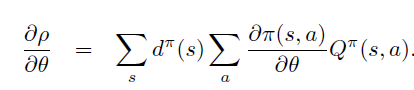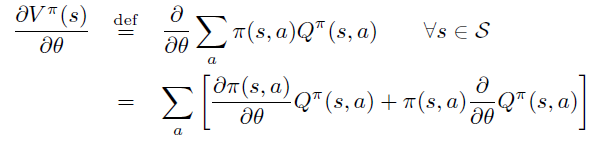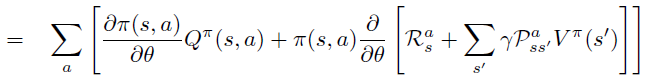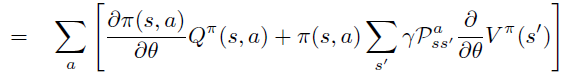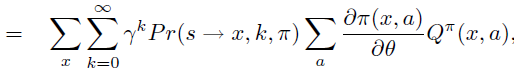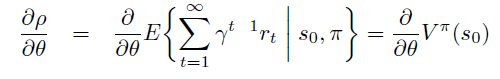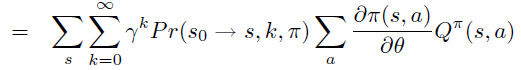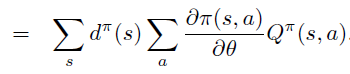classActions(Enum): """ Different settings for the action space of the environment """ ALL = 0#: MultiBinary action space with no filtered actions FILTERED = 1#: MultiBinary action space with invalid or not allowed actions filtered out DISCRETE = 2#: Discrete action space for filtered actions MULTI_DISCRETE = 3#: MultiDiscete action space for filtered actions
from gym.spaces import * space = Dict({'position':Discrete(2), 'velocity':Discrete(3)}) print(space.sample())
输出是
1
OrderedDict([('position', 1), ('velocity', 1)])
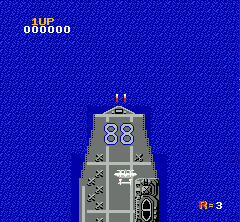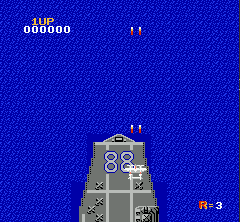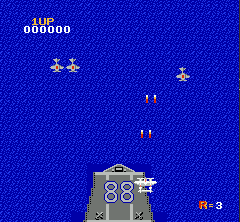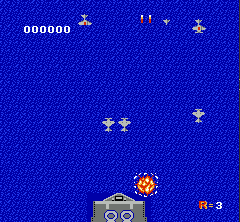
NES 1942 动作空间配置
了解了 gym/retro 的动作空间,我们来看看1942的默认动作空间
1 2
env = retro.make(game='1942-Nes') print("The size of action is: ", env.action_space.shape)
1
The size of action is: (9,)
表示有9个 Discrete 动作,包括 start, select这些控制键。
从训练1942角度来说,我们希望指定最少的有效动作取得最好的成绩。根据经验,我们知道这个游戏最重要的键是4个方向加上
fire
键。限定游戏动作空间,官方的做法是在创建游戏环境时,指定预先生成的动作输入配置文件。但是这个方式相对麻烦,我们采用了直接指定按键的二进制表示来达到同样的目的,此时,需要设置
use_restricted_actions=retro.Actions.FILTERED。
for _ inrange(self.ppo_epoch): for state, action, old_log_probs, return_, advantage in sample_batch(): dist = self.actor_net(state) value = self.critic_net(state)
# Minimize the loss self.actor_optimizer.zero_grad() self.critic_optimizer.zero_grad() loss.backward() self.actor_optimizer.step() self.critic_optimizer.step()
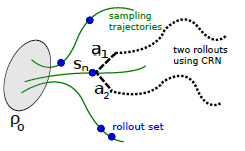
Policy Gradient 定理的伟大之处在于等式右边并没有 \(d^{\pi}(s)\),或者环境transition model
\(p\left(s^{\prime}, r \mid s,
a\right)\)!同时,等式右边变换成了最利于统计采样的期望形式,因为期望可以通过样本的平均来估算。
上期详细讲解了DQN中的两个重要的技术:Target Network 和 Experience
Replay,正是有了它们才使得 Deep Q
Network在实战中容易收敛,以下是Deepmind 发表在Nature 的 Human-level
control through deep reinforcement learning 的完整算法流程。
import gym_super_mario_bros from random import random, randrange from gym_super_mario_bros.actions import RIGHT_ONLY from nes_py.wrappers import JoypadSpace from gym import wrappers
但是此方法有一个前提要满足,由于数据是依据策略 \(\pi_{i}\)
生成的,理论上需要保证在无限次的模拟过程中,每个状态都必须被无限次访问到,才能保证最终每个状态的Q估值收敛到真实的
\(q_{*}\)。满足这个前提的一个简单实现是强制随机环境初始状态,保证每个状态都能有一定概率被生成。这个思路就是
Monte Carlo Control with Exploring Starts算法,伪代码如下:
\[
\begin{align*}
&\textbf{Monte Carlo ES (Exploring Starts), for estimating } \pi
\approx \pi_{*} \\
& \text{Initialize:} \\
& \quad \pi(s) \in \mathcal A(s) \text{ arbitrarily for all }s \in
\mathcal{S} \\
& \quad Q(s, a) \in \mathbb R \text{, arbitrarily, for all }s \in
\mathcal{S}, a \in \mathcal A(s) \\
& \quad Returns(s, a) \leftarrow \text{ an empty list, for all }s
\in \mathcal{S}, a \in \mathcal A(s)\\
& \\
& \text{Loop forever (for episode):}\\
& \quad \text{Choose } S_0\in \mathcal{S}, A_0 \in \mathcal A(S_0)
\text{ randomly such that all pairs have probability > 0} \\
& \quad \text{Generate an episode from } S_0, A_0 \text{, following
} \pi : S_0, A_0, R_1, S_1, A_1, R_2, ..., S_{T-1}, A_{T-1}, R_T\\
& \quad G \leftarrow 0\\
& \quad \text{Loop for each step of episode, } t = T-1, T-2, ...,
0:\\
& \quad \quad \quad G \leftarrow \gamma G + R_{t+1}\\
& \quad \quad \quad \text{Unless the pair } S_t, A_t \text{ appears
in } S_0, A_0, S_1, A_1, ..., S_{t-1}, A_{t-1}\\
& \quad \quad \quad \quad \text{Append } G \text { to }Returns(S_t,
A_t) \\
& \quad \quad \quad \quad Q(S_t, A_t) \leftarrow
\operatorname{average}(Returns(S_t, A_t))\\
& \quad \quad \quad \quad \pi(S_t) \leftarrow
\operatorname{argmax}_a Q(S_t, a)\\
\end{align*}
\]
下面我们实现21点游戏的Monte Carlo ES
算法。21点游戏只有200个有效的状态,可以满足算法要求的生成episode前先随机选择某一状态的前提条件。
G = 0 for t inrange(len(episode_history) - 1, -1, -1): s, a, r = episode_history[t] G = discount_factor * G + r ifnotany(s_a_r[0] == s and s_a_r[1] == a for s_a_r in episode_history[0: t]): returns_sum[s, a] += G returns_count[s, a] += 1.0 Q[s][a] = returns_sum[s, a] / returns_count[s, a] best_a = np.argmax(Q[s]) policy[s][best_a] = 1.0 policy[s][1-best_a] = 0.0
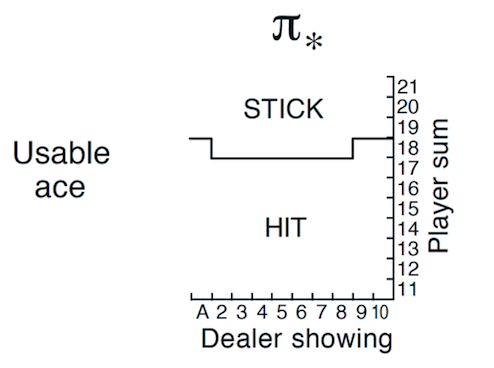
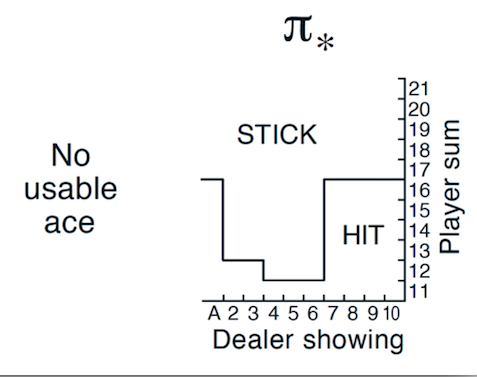
下图是有Usable Ace情况下的理论最优策略。
理论最佳策略(有Ace)
Monte
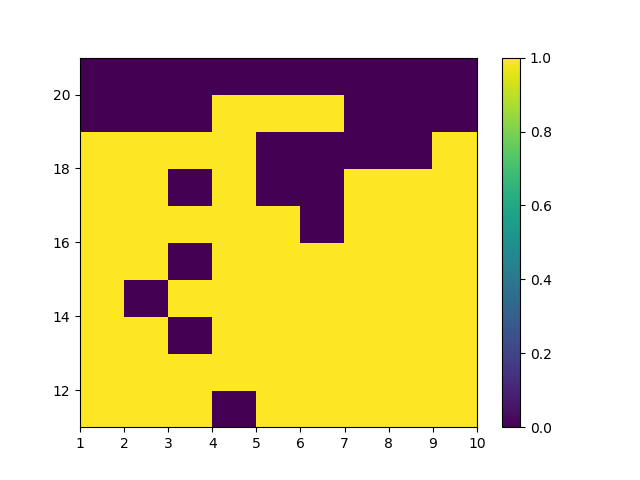
Carlo方法策略提示的收敛是比较慢的,下图是运行10,000,000次episode后有Usable
Ace时的策略 \(\pi_{*}^{\prime}\)。对比理论最优策略,MC
ES在不少的状态下还未收敛到理论最优解。
MC ES 10M的最佳策略(有Ace)
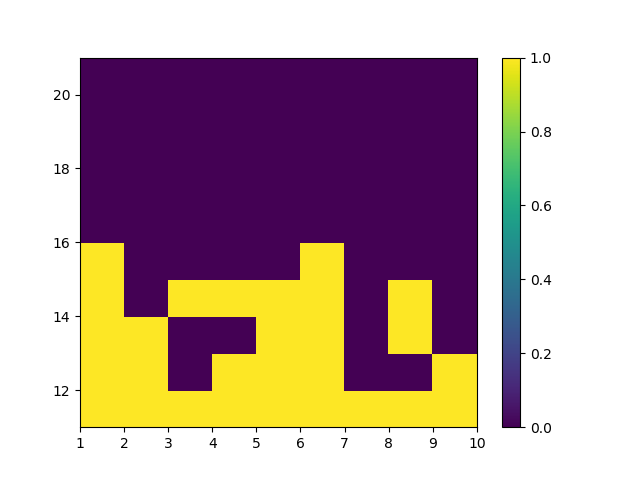
同样的,下两张图是无Usable Ace情况下的理论最优策略和试验结果的对比。
理论最佳策略(无Ace)
MC ES 10M的最佳策略(无Ace)
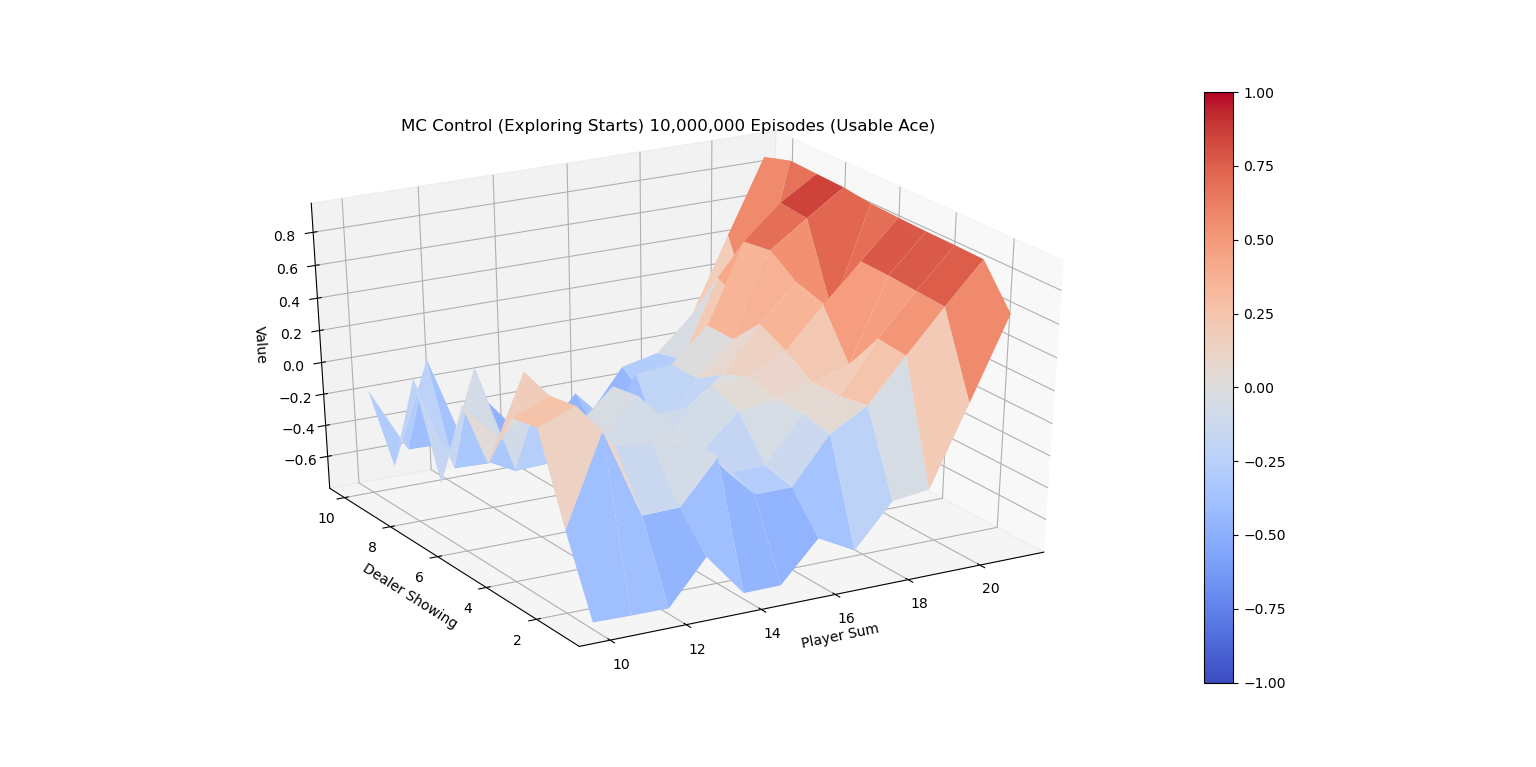
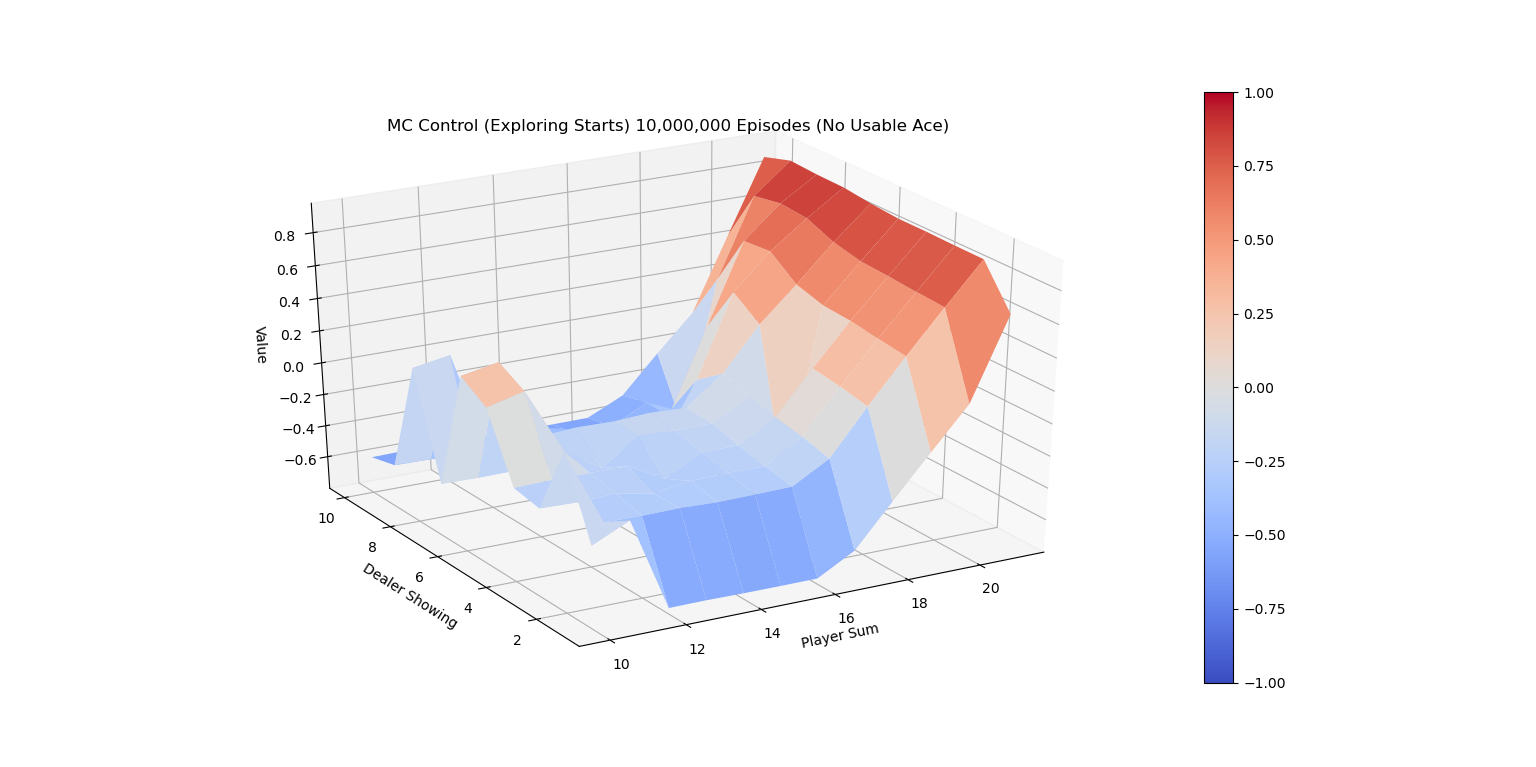
下面的两张图画出了运行代码10,000,000次episode后 \(\pi{*}\)的V值图。
MC ES 10M的最佳V值(有Ace)
MC ES 10M的最佳V值(无Ace)
Exploring Starts
蒙特卡洛控制改进
为了避免Monte Carlo ES
Control在初始时必须访问到任意状态的限制,教材中介绍了一种改进算法,On-policy
first-visit MC control for \(\epsilon
\text{-soft policies}\) ,它同样基于Monte Carlo 预估Q值,但用
\(\epsilon \text{-soft}\)
策略来代替最有可能的action策略作为下一次迭代策略,\(\epsilon \text{-soft}\)
本质上来说就是对于任意动作都保留 \(\epsilon\)
小概率的访问可能,权衡了exploration和exploitation,由于每个动作都可能被无限次访问到,Explorting
Starts中的强制随机初始状态就可以去除了。Monte Carlo ES Control 和
On-policy first-visit MC control for \(\epsilon \text{-soft policies}\)
都属于on-policy算法,其区别于off-policy的本质在于预估 \(q_{\pi}(s,a)\)时是否从同策略\(\pi\)生成的数据来计算。一个比较subtle的例子是著名的Q-Learning,因为根据这个定义,Q-Learning属于off-policy。
\[
\begin{align*}
&\textbf{On-policy first-visit MC control (for }\epsilon
\textbf{-soft policies), estimating } \pi \approx \pi_{*} \\
& \text{Algorithm parameter: small } \epsilon > 0 \\
& \text{Initialize:} \\
& \quad \pi \leftarrow \text{ an arbitrary } \epsilon \text{-soft
policy} \\
& \quad Q(s, a) \in \mathbb R \text{, arbitrarily, for all }s \in
\mathcal{S}, a \in \mathcal A(s) \\
& \quad Returns(s, a) \leftarrow \text{ an empty list, for all }s
\in \mathcal{S}, a \in \mathcal A(s)\\
& \\
& \text{Repeat forever (for episode):}\\
& \quad \text{Generate an episode following } \pi : S_0, A_0, R_1,
S_1, A_1, R_2, ..., S_{T-1}, A_{T-1}, R_T\\
& \quad G \leftarrow 0\\
& \quad \text{Loop for each step of episode, } t = T-1, T-2, ...,
0:\\
& \quad \quad \quad G \leftarrow \gamma G + R_{t+1}\\
& \quad \quad \quad \text{Unless the pair } S_t, A_t \text{ appears
in } S_0, A_0, S_1, A_1, ..., S_{t-1}, A_{t-1}\\
& \quad \quad \quad \quad \text{Append } G \text { to }Returns(S_t,
A_t) \\
& \quad \quad \quad \quad Q(S_t, A_t) \leftarrow
\operatorname{average}(Returns(S_t, A_t))\\
& \quad \quad \quad \quad A^{*} \leftarrow \operatorname{argmax}_a
Q(S_t, a)\\
& \quad \quad \quad \quad \text{For all } a \in \mathcal A(S_t):\\
& \quad \quad \quad \quad \quad \pi(a|S_t) \leftarrow
\begin{cases}
1 - \epsilon + \epsilon / |\mathcal A(S_t)| & \text{ if } a =
A^{*}\\
\epsilon / |\mathcal A(S_t)| & \text{ if } a \neq A^{*}\\
\end{cases} \\
\end{align*}
\]
for episode_i inrange(1, num_episodes + 1): episode_history = gen_stochastic_episode(policy, env)
G = 0 for t inrange(len(episode_history) - 1, -1, -1): s, a, r = episode_history[t] G = discount_factor * G + r ifnotany(s_a_r[0] == s and s_a_r[1] == a for s_a_r in episode_history[0: t]): returns_sum[s, a] += G returns_count[s, a] += 1.0 Q[s][a] = returns_sum[s, a] / returns_count[s, a] update_epsilon_greedy_policy(policy, Q, s)

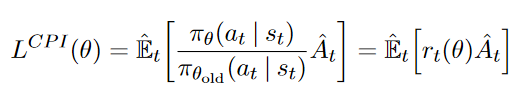
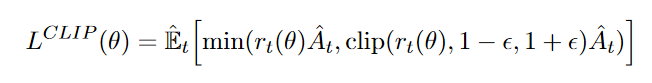
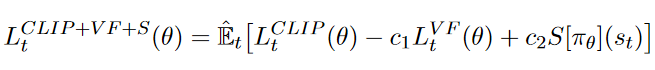

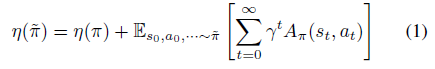
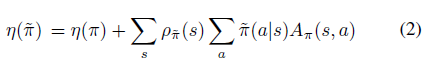
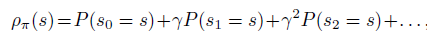
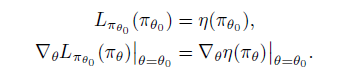
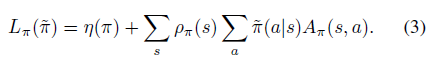
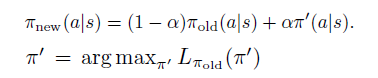
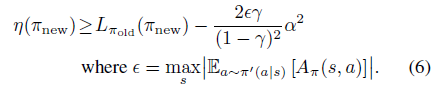

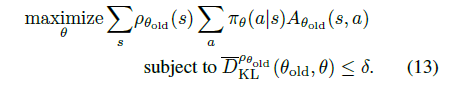
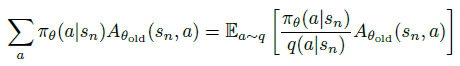
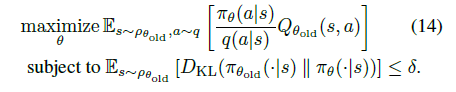
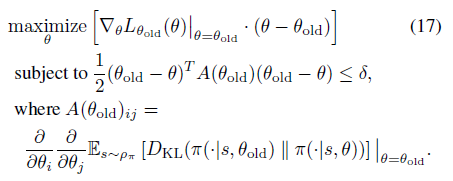
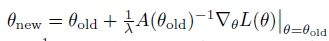
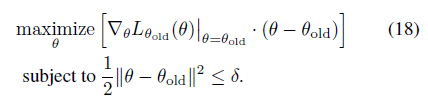

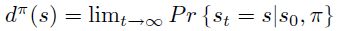
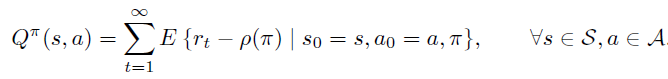
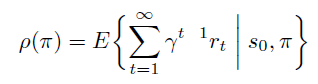
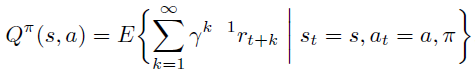
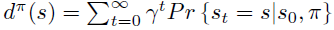
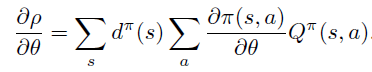
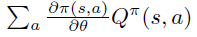
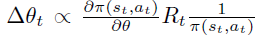
.png)