defnormal_box_muller(): import random from math import sqrt, log, pi, cos, sin u1 = random.random() u2 = random.random() r = sqrt(-2 * log(u1)) theta = 2 * pi * u2 z0 = r * cos(theta) z1 = r * sin(theta) return z0, z1
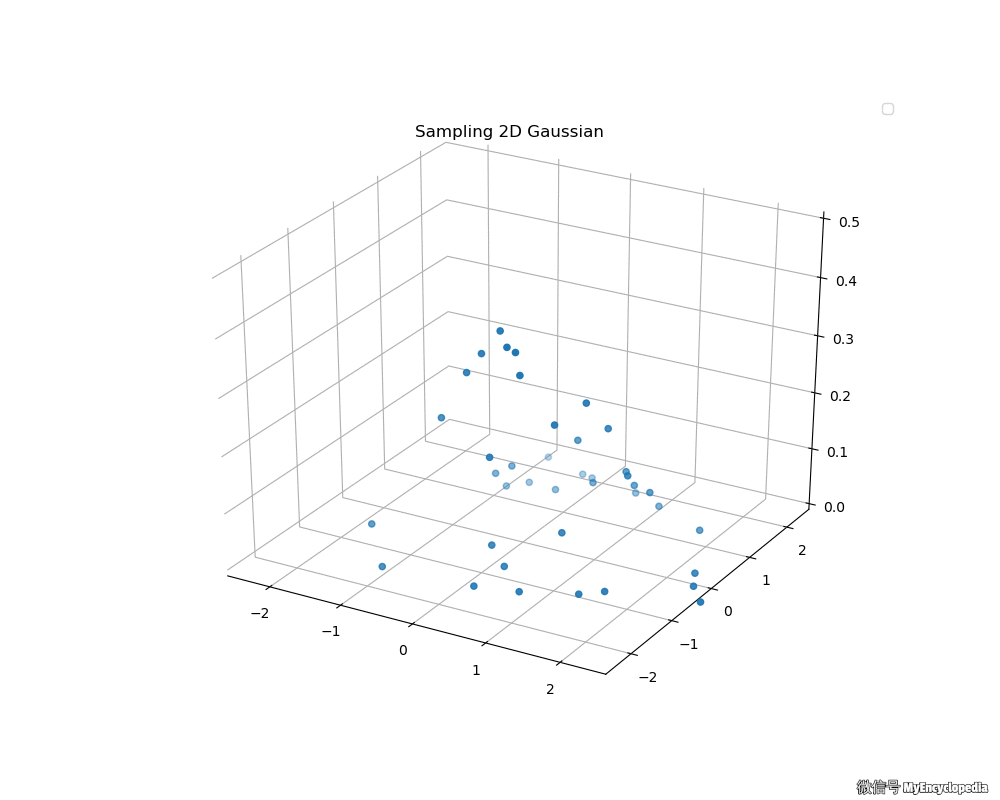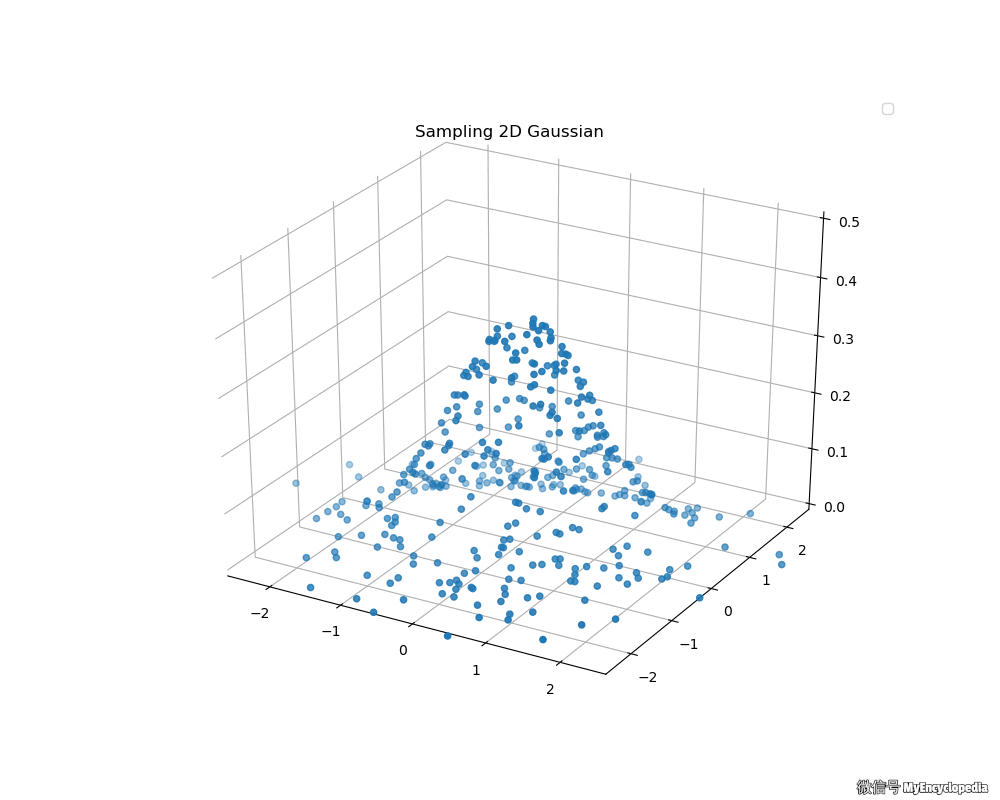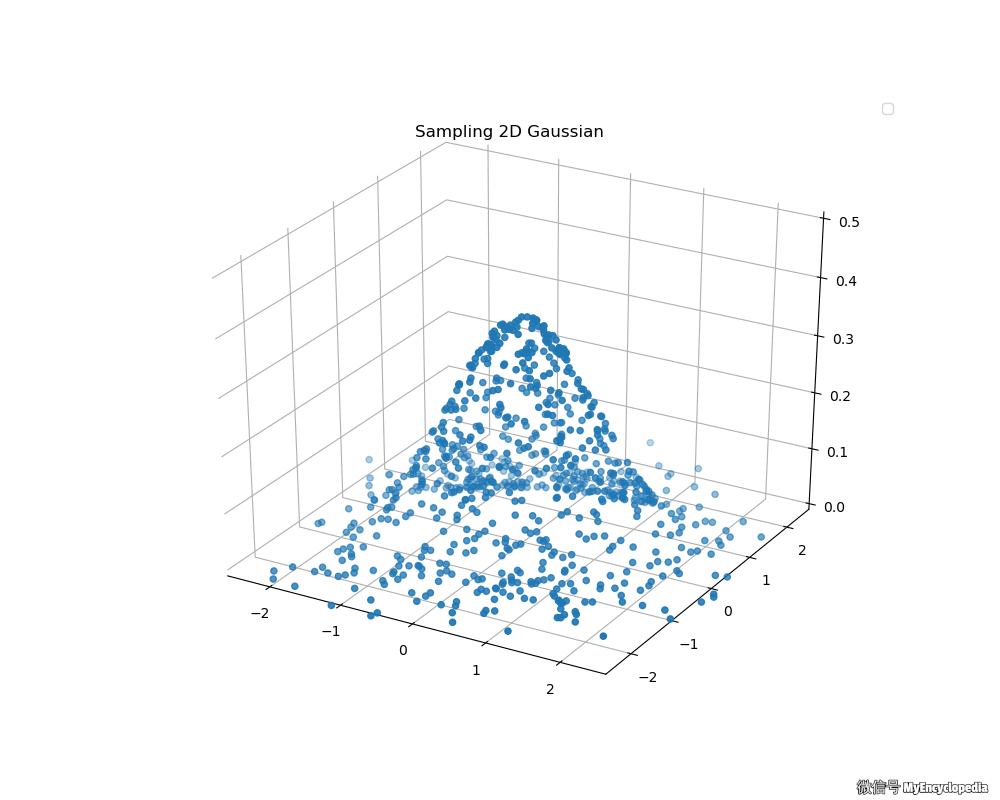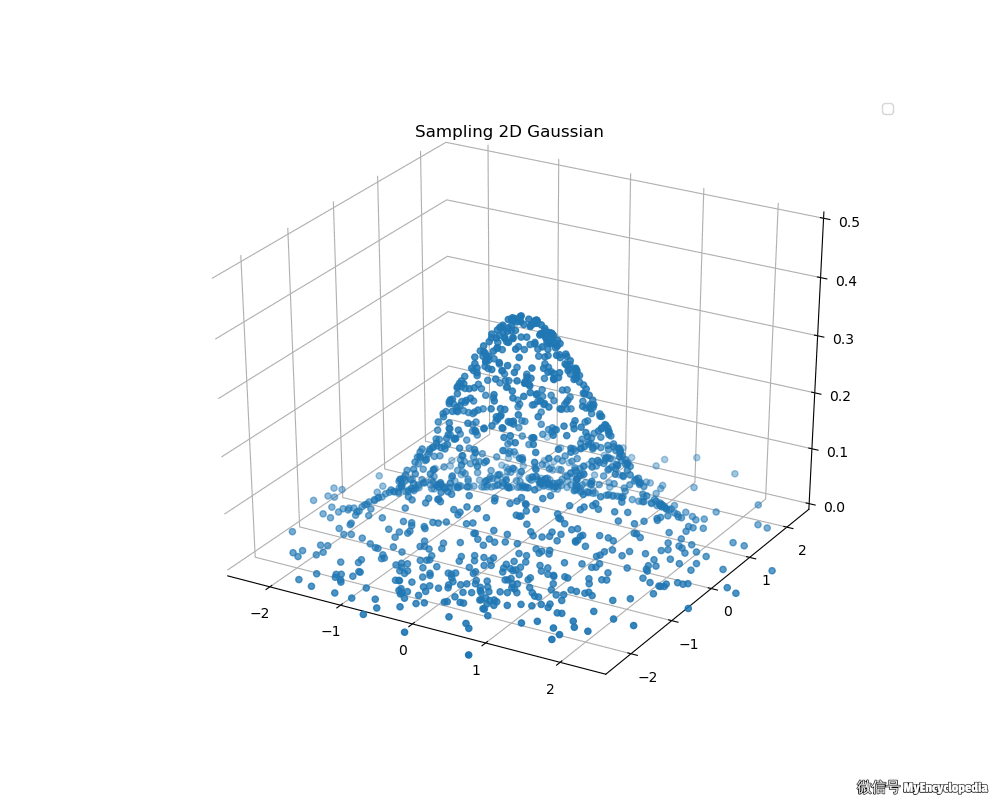
接下来,我们来看看 Box-Muller 法生成的二维标准正态分布动画吧
拒绝采样极坐标方法
Box-Muller 方法还有一种形式,称为极坐标形式,属于拒绝采样方法。
1. 生成独立的 u, v 和 s
分别生成 [0, 1] 均匀分布 u 和 v。令 \(s =
r^2 = u^2 + v^2\)。如果 s = 0或 s ≥ 1,则丢弃 u 和 v
,并尝试另一对 (u , v)。因为 u 和 v
是均匀分布的,并且因为只允许单位圆内的点,所以 s
的值也将均匀分布在开区间 (0, 1) 中。注意,这里的 s
的意义虽然也为半径,但不同于基本方法中的 s。这里 s 取值范围为
(0, 1) ,目的是通过 s 生成指数分布,而基本方法中的 s 取值范围为 [0,
+∞],表示二维正态分布 PDF 采样点的半径。复用符号 s
的原因是为了对应维基百科中关于基本方法和极坐标方法的数学描述。
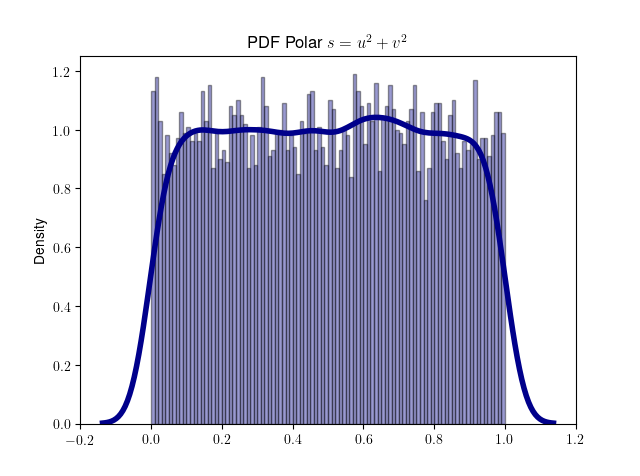
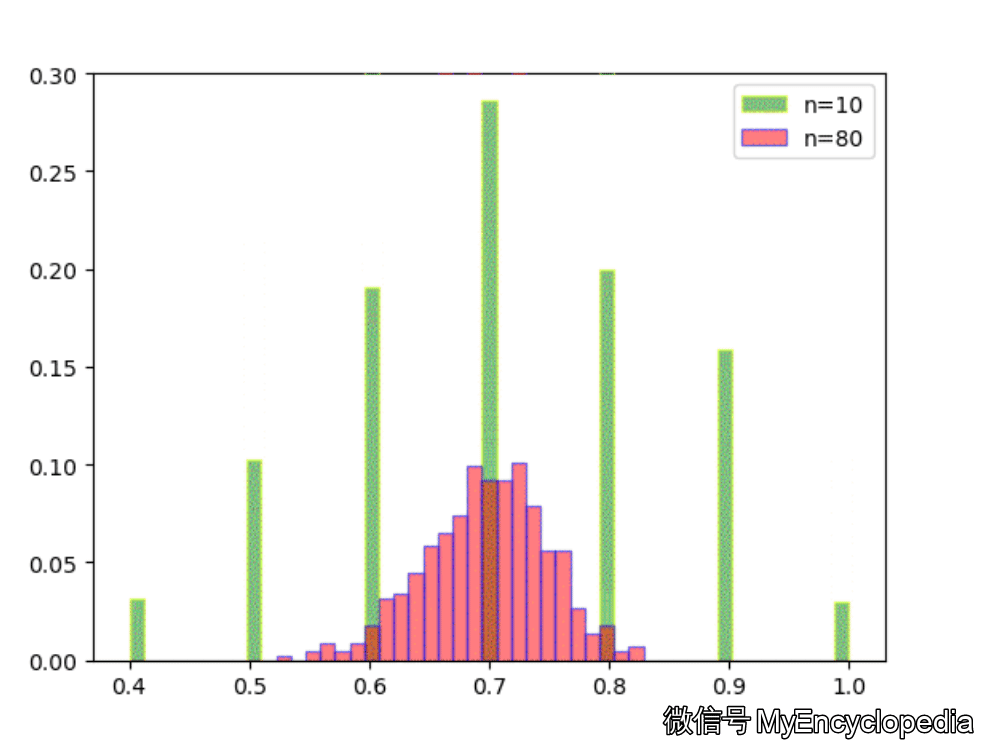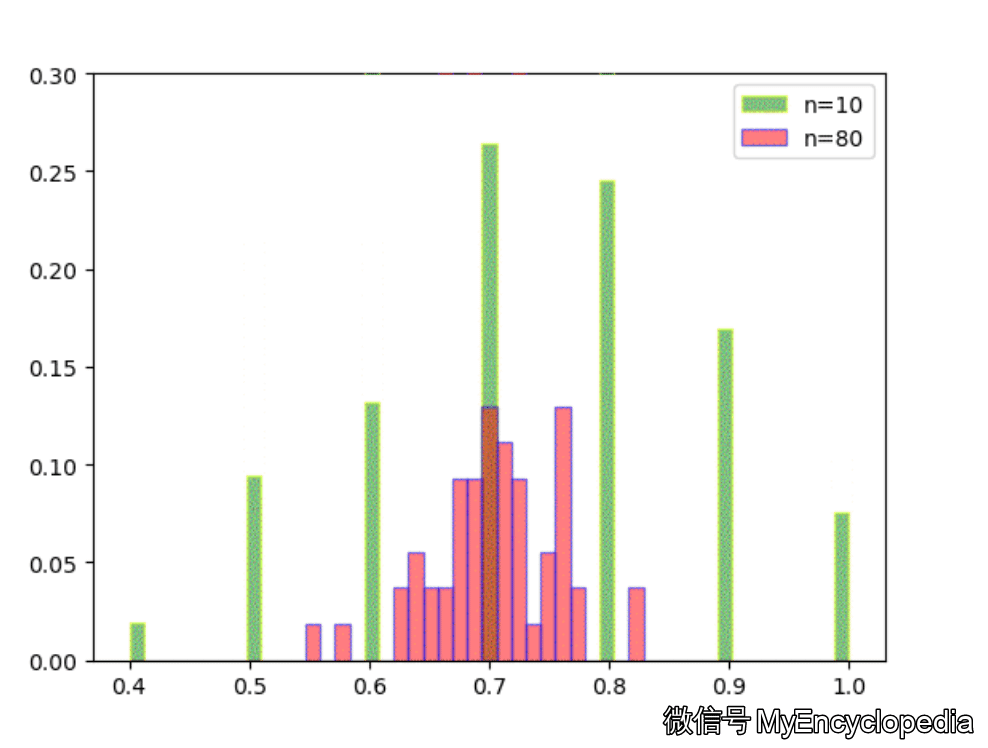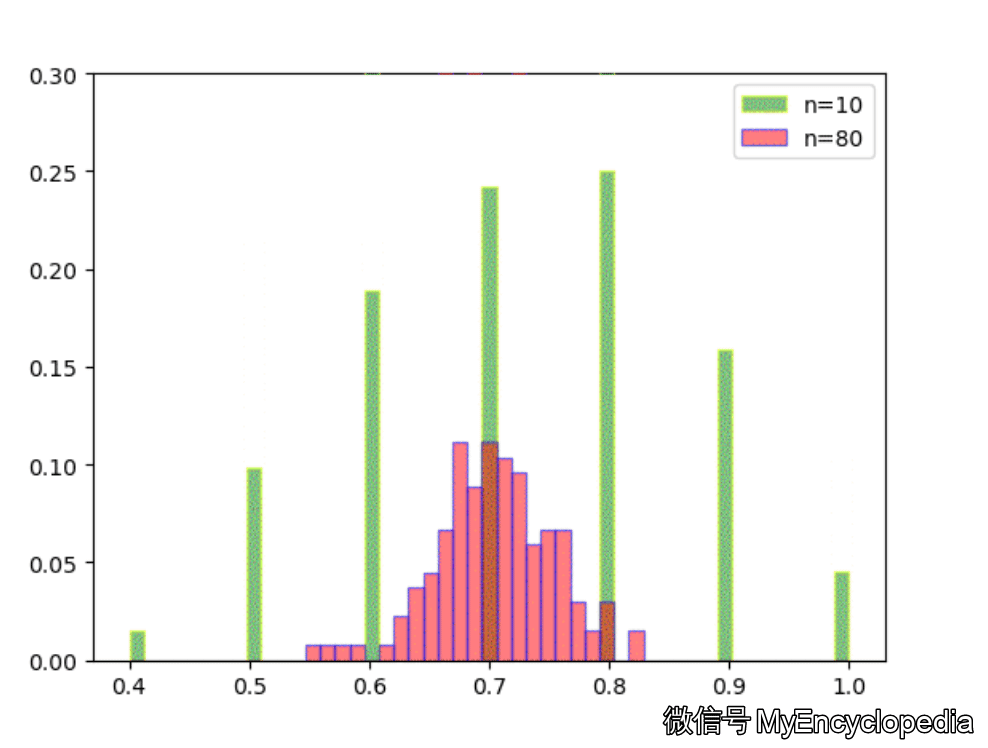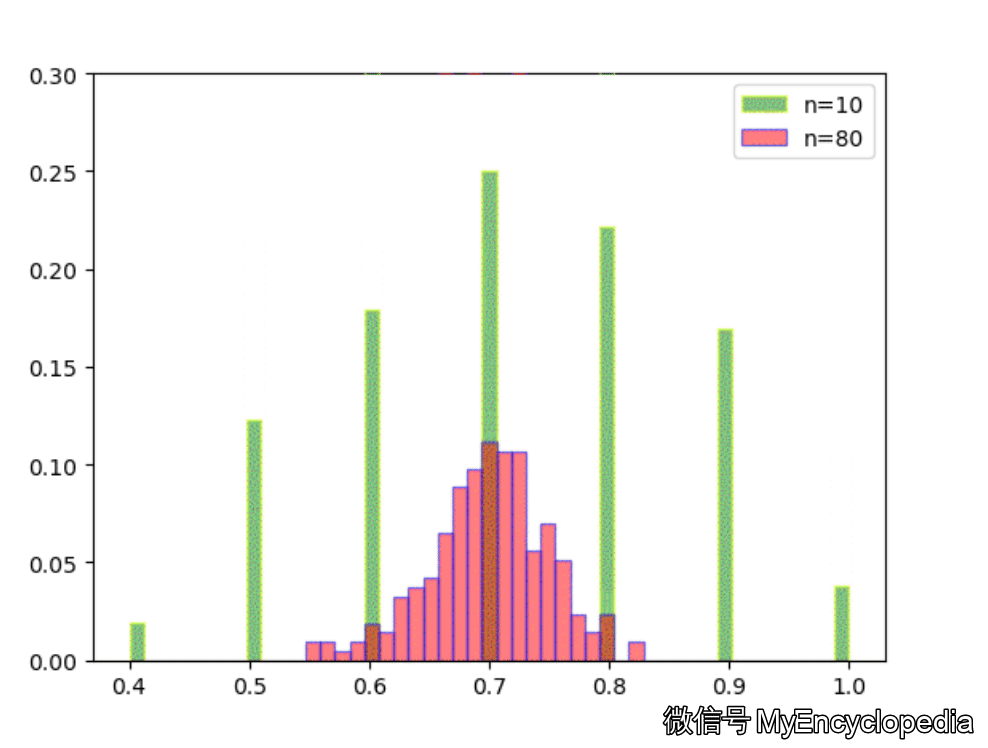
我们用代码来验证 s 服从 (0, 1) 范围上的均匀分布。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
defgen_polar_s(): import random whileTrue: u = random.uniform(-1, 1) v = random.uniform(-1, 1) s = u * u + v * v if s >= 1.0or s == 0.0: continue return s
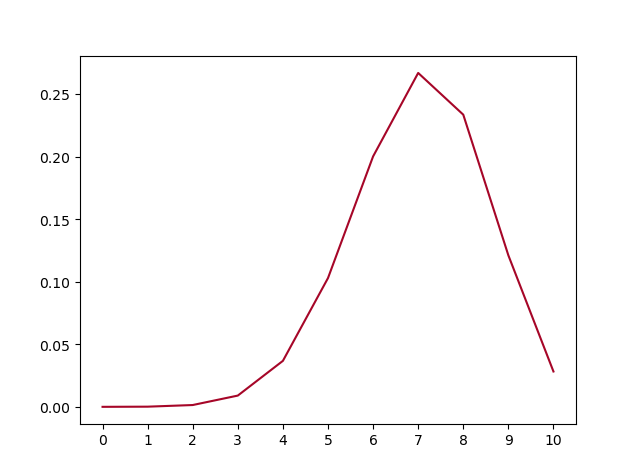
defplot_polar_s(): s = [gen_polar_s() for _ inrange(10000) ] plot_dist_1d(s, title='PDF Polar $s = u^2 + v^2$')
defnormal_box_muller_polar(): import random from math import sqrt, log whileTrue: u = random.uniform(-1, 1) v = random.uniform(-1, 1) s = u * u + v * v if s >= 1.0or s == 0.0: continue z0 = u * sqrt(-2 * log(s) / s) z1 = v * sqrt(-2 * log(s) / s) return z0, z1
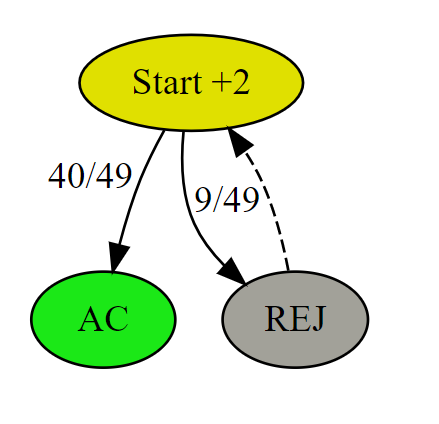
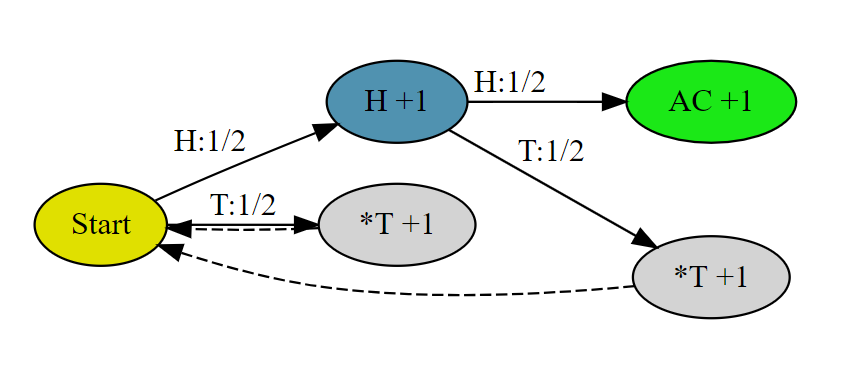
# AC # Runtime: 408 ms, faster than 23.80% of Python3 online submissions for Implement Rand10() Using Rand7(). # Memory Usage: 16.7 MB, less than 90.76% of Python3 online submissions for Implement Rand10() Using Rand7(). classSolution: defrand10(self): whileTrue: a = rand7() if a <= 3: b = rand7() if b <= 5: return b elif a <= 6: b = rand7() if b <= 5: return b + 5
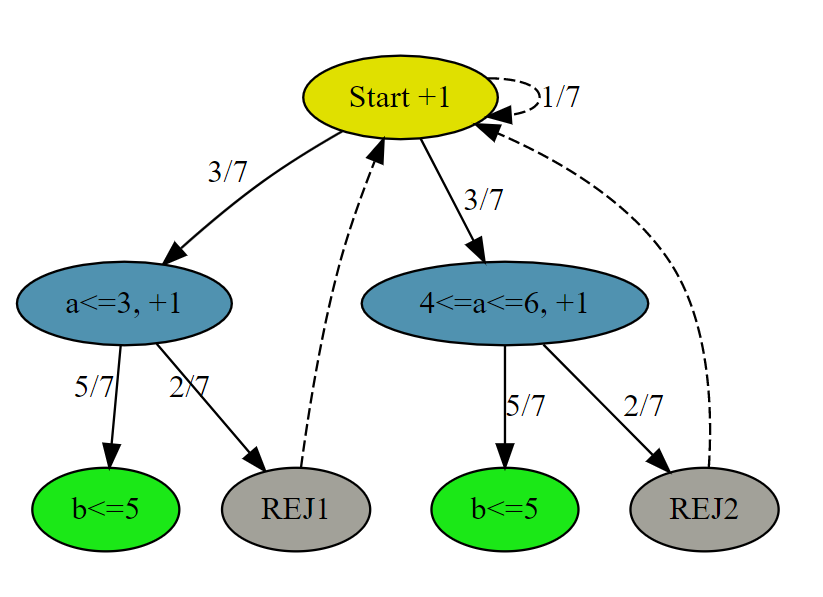
# AC # Runtime: 376 ms, faster than 54.71% of Python3 online submissions for Implement Rand10() Using Rand7(). # Memory Usage: 16.9 MB, less than 38.54% of Python3 online submissions for Implement Rand10() Using Rand7(). classSolution: defrand10(self): whileTrue: a, b = rand7(), rand7() num = (a - 1) * 7 + b if num <= 40: return num % 10 + 1
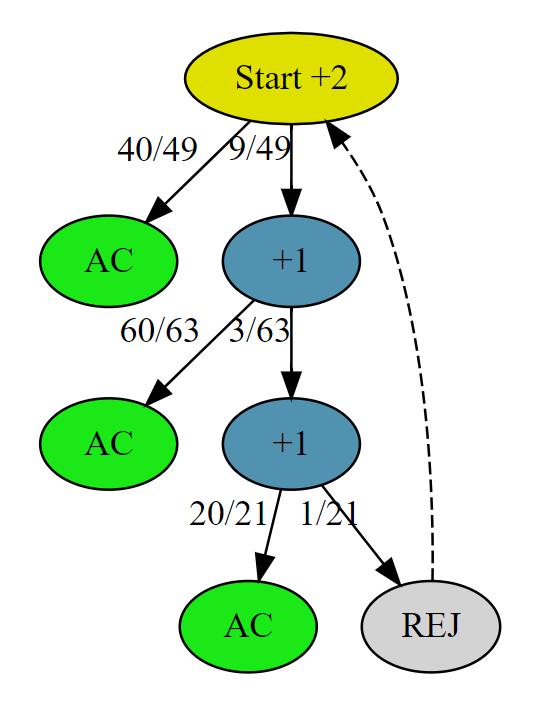
# AC # Runtime: 344 ms, faster than 92.72% of Python3 online submissions for Implement Rand10() Using Rand7(). # Memory Usage: 16.7 MB, less than 90.76% of Python3 online submissions for Implement Rand10() Using Rand7(). classSolution: defrand10(self): whileTrue: a, b = rand7(), rand7() num = (a - 1) * 7 + b if num <= 40: return num % 10 + 1 a = num - 40 b = rand7() num = (a - 1) * 7 + b if num <= 60: return num % 10 + 1 a = num - 60 b = rand7() num = (a - 1) * 7 + b if num <= 20: return num % 10 + 1
# The rand7() API is already defined for you. rand7_c = 0 rand10_c = 0
defrand7(): global rand7_c rand7_c += 1 import random return random.randint(1, 7) defrand10(): global rand10_c rand10_c += 1 whileTrue: a, b = rand7(), rand7() num = (a - 1) * 7 + b if num <= 40: return num % 10 + 1 a = num - 40# [1, 9] b = rand7() num = (a - 1) * 7 + b # [1, 63] if num <= 60: return num % 10 + 1 a = num - 60# [1, 3] b = rand7() num = (a - 1) * 7 + b # [1, 21] if num <= 20: return num % 10 + 1
if __name__ == '__main__': whileTrue: rand10() print(f'{rand10_c}{round(rand7_c/rand10_c, 2)}')
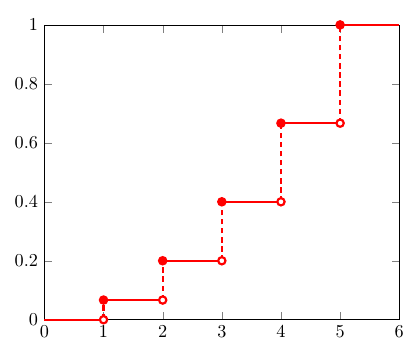
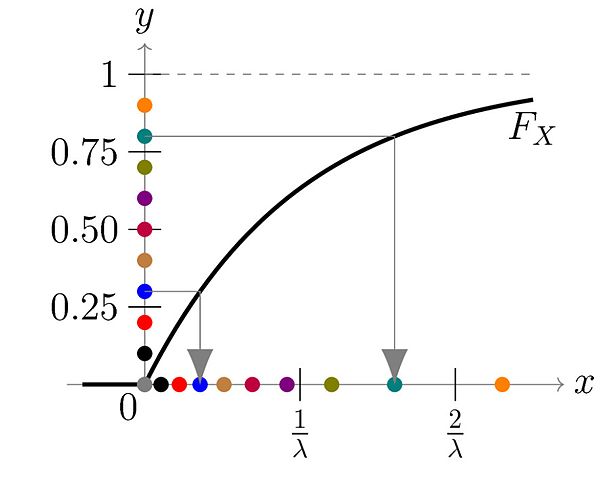
那么Inverse Transformation Method 的第一步,随机生成 0-1 之间的数
u,可以直观的认为是在 y 轴上生成一个随机的点
u。注意到5段竖虚线对应了5个离散的取值,它们的长度和为1,并且每一段长度代表了每个值的权重。因此,通过在
y 轴上的均匀采样可以生成给定PMF的 x 的分布。
离散分布的逆变换采样方法用数学公式可以表述为:找到第一个
x,其CDF的范围包括了 u,即
\[
F^{-1}(u)=\min \{x: F(x) \geq u\}
\]
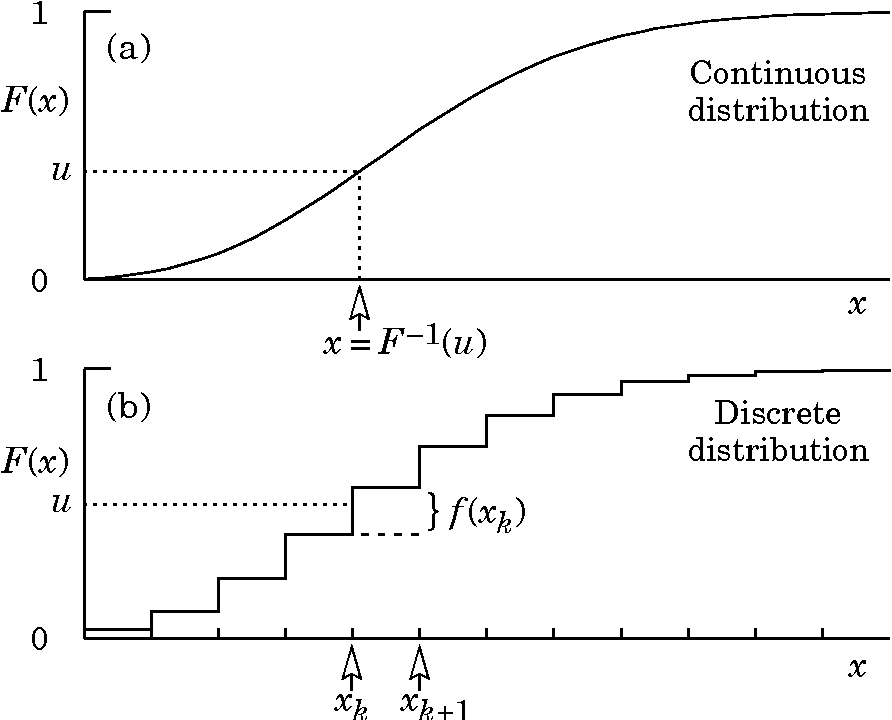
扩展到连续分布
有了离散类别分布的直观感受,扩展到连续分布也就不难理解了。类似于微积分中将连续空间做离散切分,再通过极限的方法,连续光滑函数在
y 轴上可以切分成长度为 \(\Delta u\)
的线段,那么生成的 x 值就是其近似值。随着 $ _{u } $,最终 $ x=F^{-1}(u)
$ 即为满足要求的分布。
defpoisson(lambdda: float) -> int: total = 1.0 i = 0 threshold = exp(-1 * lambdda) while total >= threshold: u = random.random() total *= u i += 1 return i - 1
defsimulate_bruteforce(n: int) -> bool: """ Simulates one round. Unbounded time complexity. :param n: total number of seats :return: True if last one has last seat, otherwise False """
seats = [Falsefor _ inrange(n)]
for i inrange(n-1): if i == 0: # first one, always random seats[random.randint(0, n - 1)] = True else: ifnot seats[i]: # i-th has his seat seats[i] = True else: whileTrue: rnd = random.randint(0, n - 1) # random until no conflicts ifnot seats[rnd]: seats[rnd] = True break returnnot seats[n-1]
defsimulate_online(n: int) -> bool: """ Simulates one round of complexity O(N). :param n: total number of seats :return: True if last one has last seat, otherwise False """
# for each person, the seats array idx available are [i, n-1] for i inrange(n-1): if i == 0: # first one, always random rnd = random.randint(0, n - 1) swap(rnd, 0) else: if seats[i] == i: # i-th still has his seat pass else: rnd = random.randint(i, n - 1) # selects idx from [i, n-1] swap(rnd, i) return seats[n-1] == n - 1
递推思维
这一节我们用数学递推思维来解释0.5的解。令f(n) 为第 n
位乘客坐在自己的座位上的概率,考察第一个人的情况(first step
analysis),有三种可能
这种思想可以写出如下代码,seats为 n 大小的bool
数组,当第i个人(0<i<n)发现自己座位被占的话,此时必然seats[0]没有被占,同时seats[i+1:]都是空的。假设seats[0]被占的话,要么是第一个人占的,要么是第p个人(p<i)坐了,两种情况下乱序都已经恢复了,此时第i个座位一定是空的。
defsimulate(n: int) -> bool: """ Simulates one round of complexity O(N). :param n: total number of seats :return: True if last one has last seat, otherwise False """
seats = [Falsefor _ inrange(n)]
for i inrange(n-1): if i == 0: # first one, always random rnd = random.randint(0, n - 1) seats[rnd] = True else: ifnot seats[i]: # i-th still has his seat seats[i] = True else: # 0 must not be available, now we have 0 and [i+1, n-1], rnd = random.randint(i, n - 1) if rnd == i: seats[0] = True else: seats[rnd] = True returnnot seats[n-1]

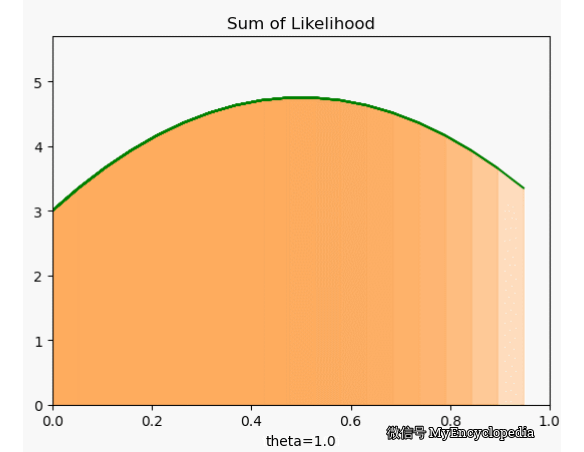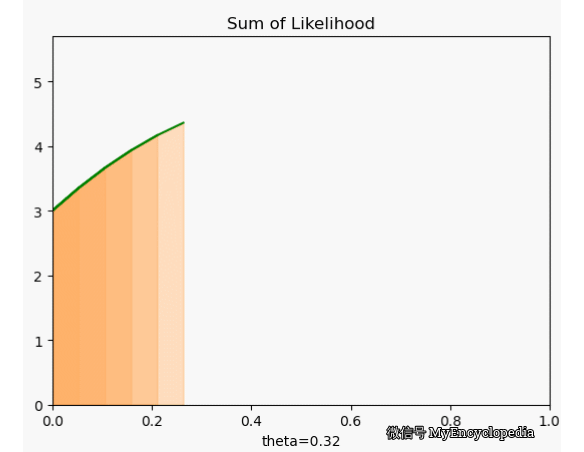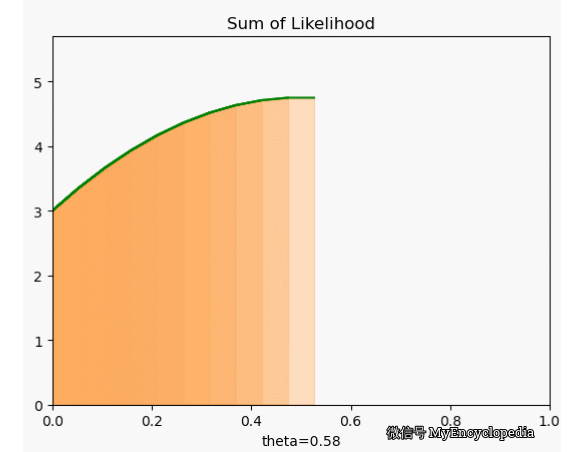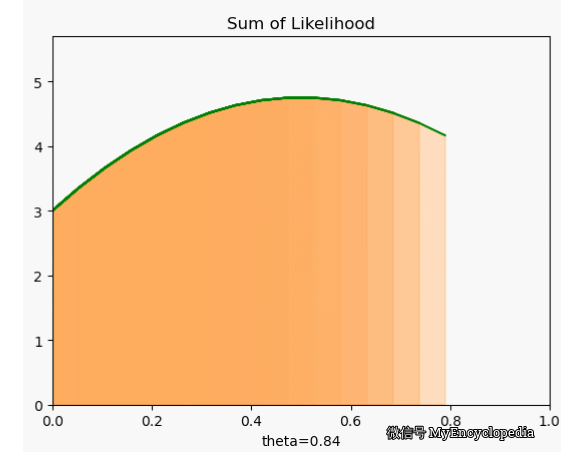
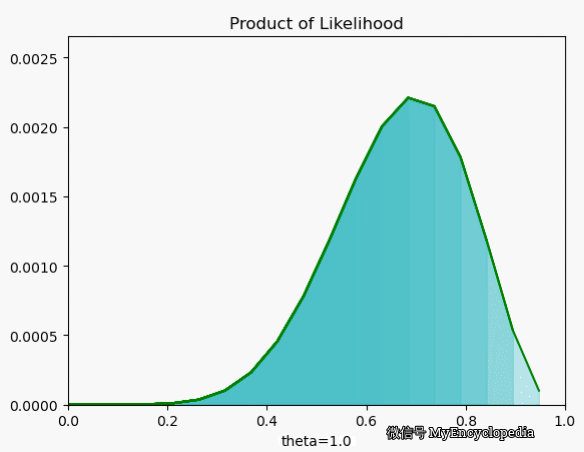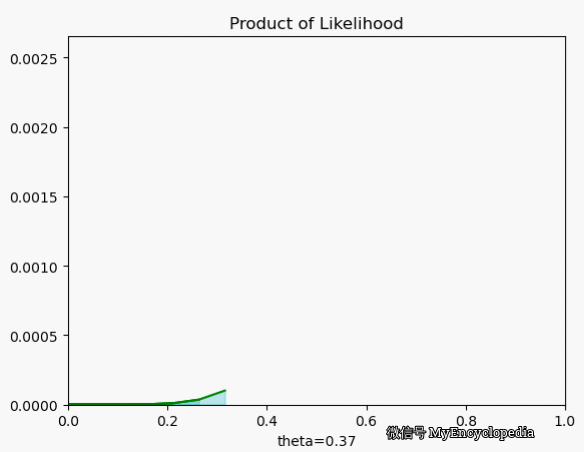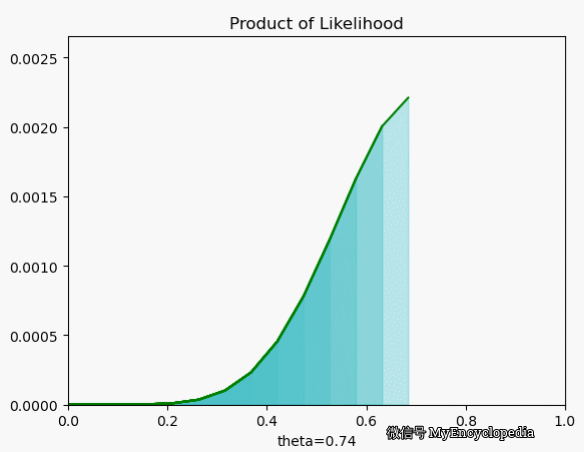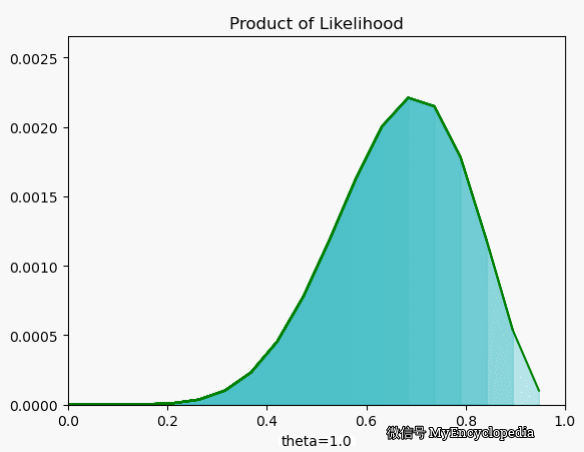
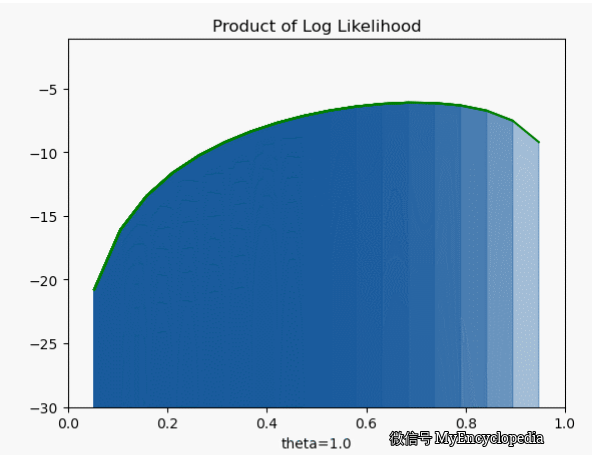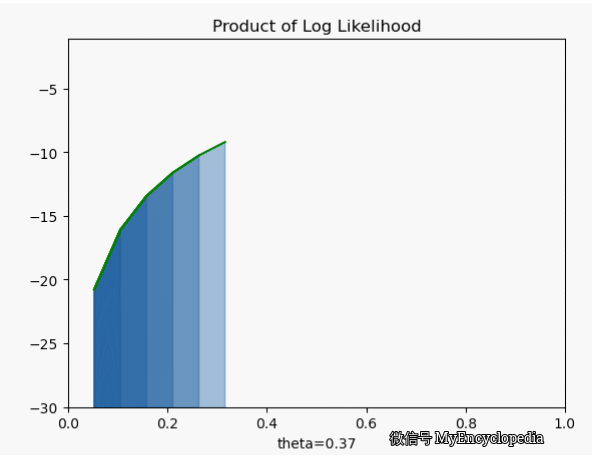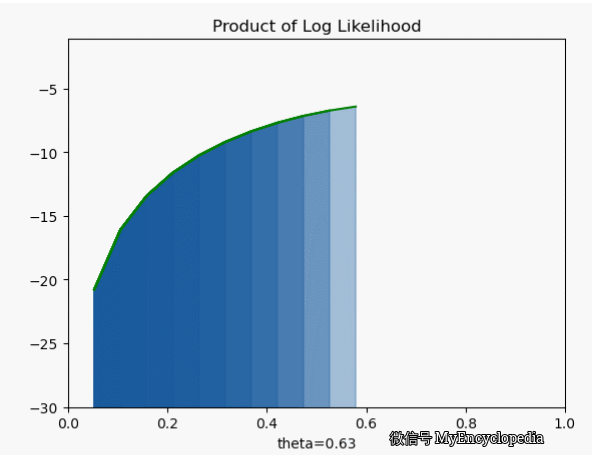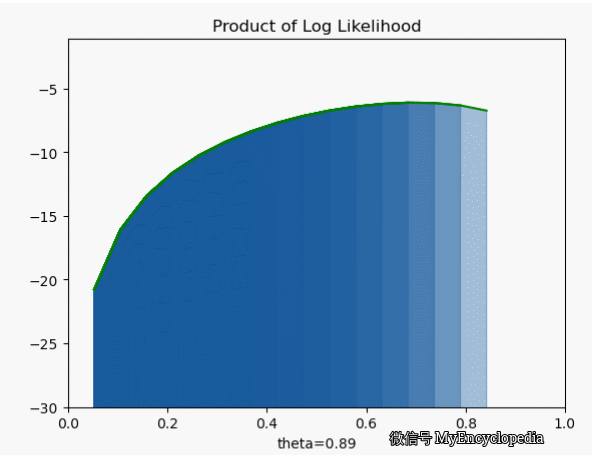
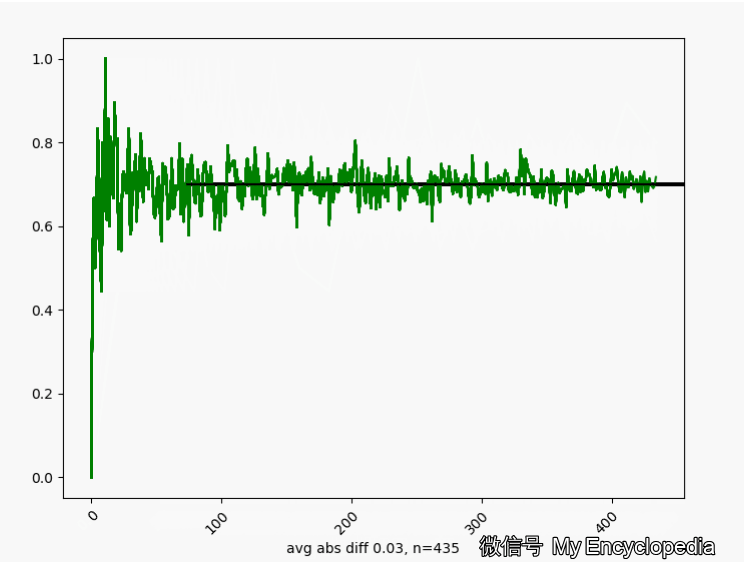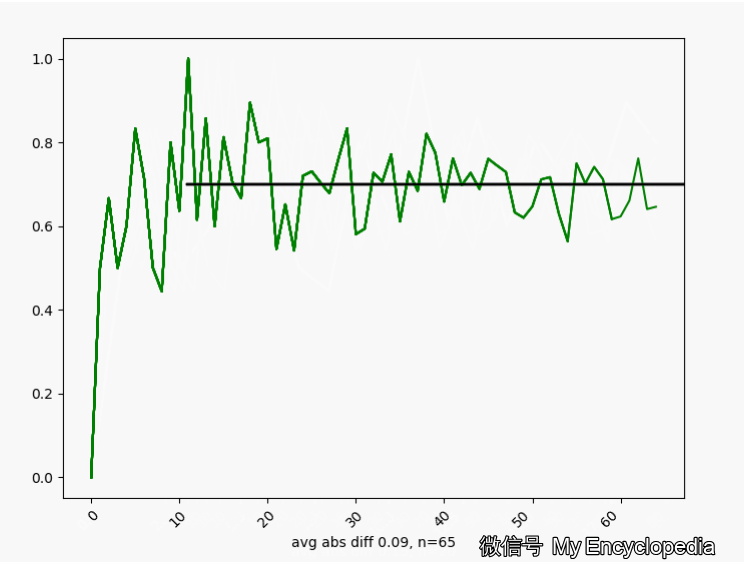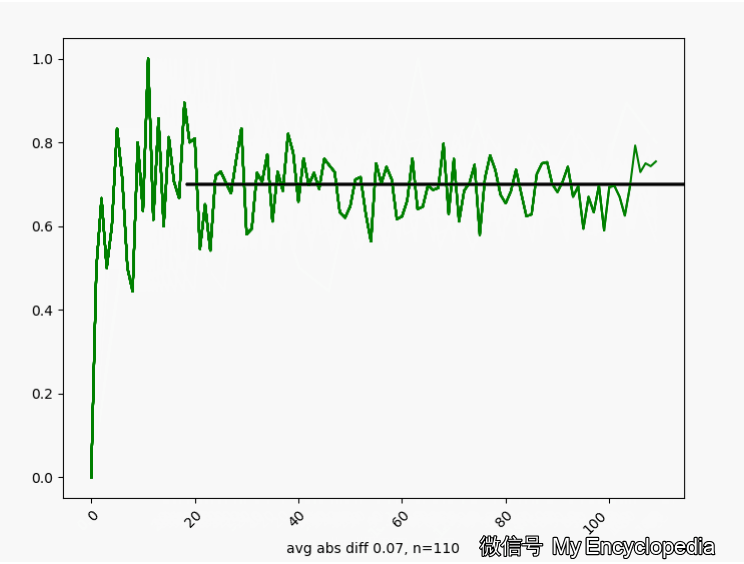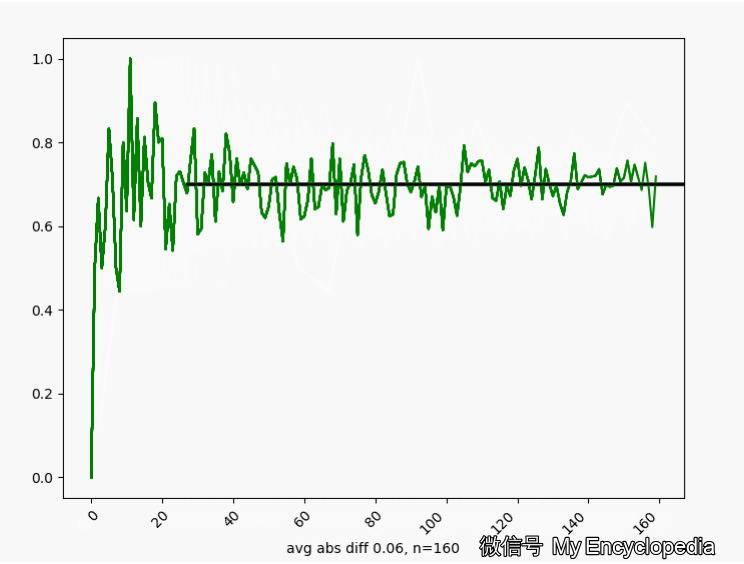
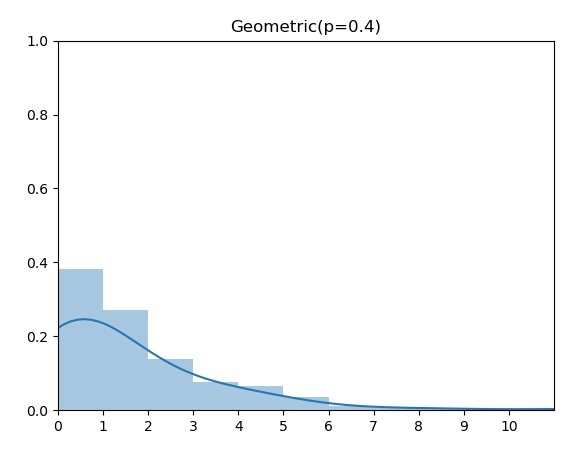
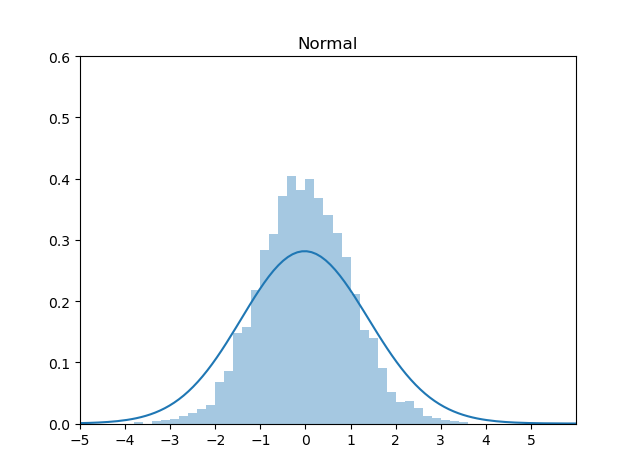
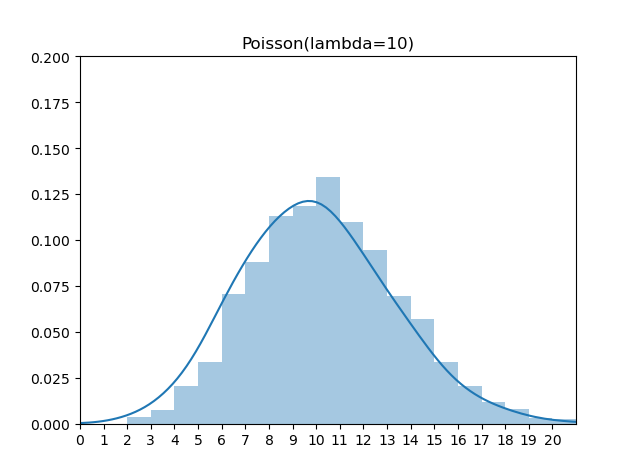
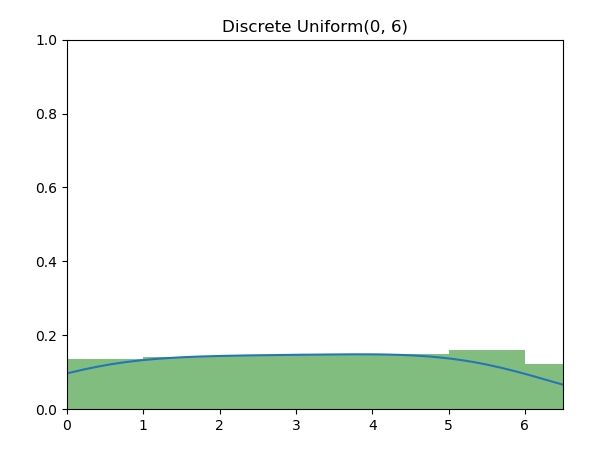
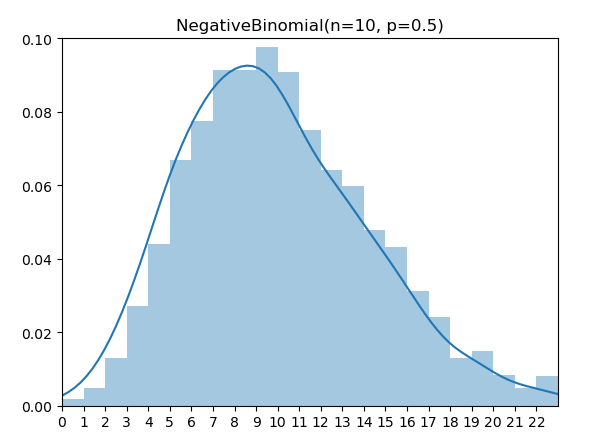
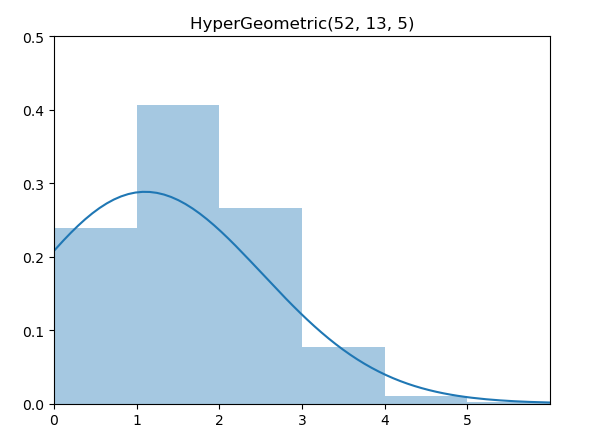
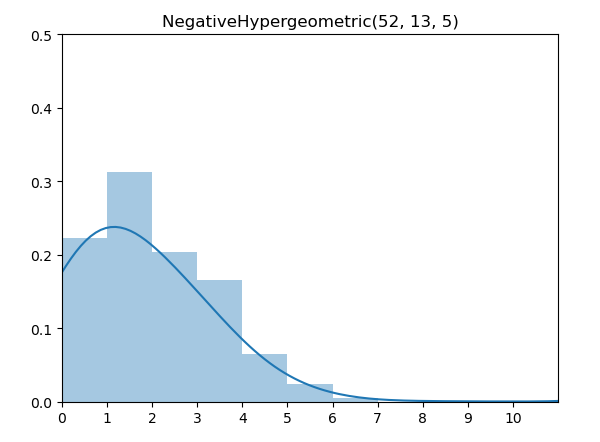
.png)
.png)