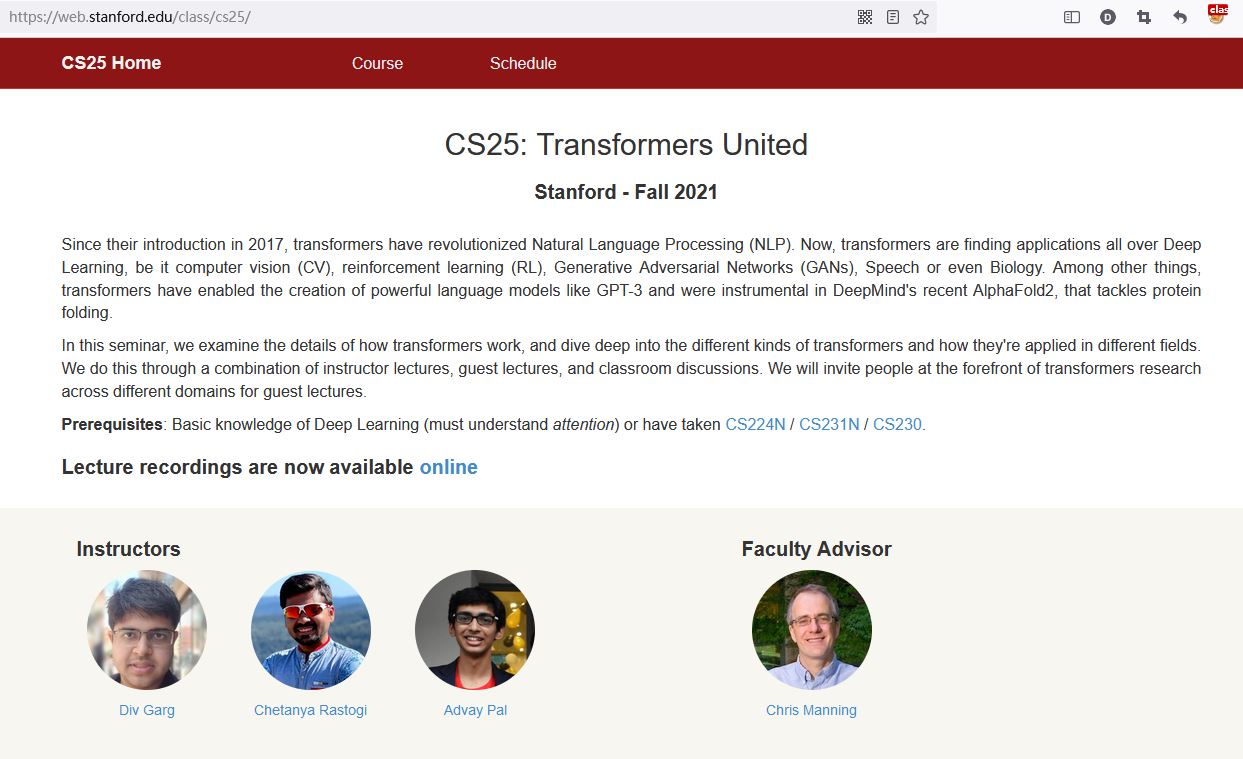
斯坦福大学的 CS 课程上线了一门经典课程:《CS 25: Transformers United》。自 2017 年推出以来,Transformer 彻底改变了自然语言处理 (NLP)领域。现在,Transformer 在深度学习中被广泛使用,无论是计算机视觉 (CV)、强化学习 (RL)、生成对抗网络 (GAN)、语音甚至是生物学。除此之外,Transformer 还能够创建强大的语言模型(如 GPT-3),并在 AlphaFold2 中发挥了重要作用,该算法解决了蛋白质折叠问题。
目前这门课程在 Youtube 上日更连载中,地址为
https://www.youtube.com/playlist?list=PLoROMvodv4rNiJRchCzutFw5ItR_Z27CM
MyEncyclopedia Bilibili 为大家每日搬运同步视频,至今天7/16日已经有6集
明星讲课阵容
在今天公布的第一节课中,讲师为斯坦福大学硕士生 Divyansh Garg、软件工程师 Chetanya Rastogi(毕业于斯坦福大学)、软件工程师 Advay Pal(毕业于斯坦福大学)。
此外,第一节课的指导教授为 Christopher Manning,他是斯坦福大学计算机与语言学教授,也是将深度学习应用于自然语言处理领域的领军者。
从之前的课程描述来看,CS 25 课程邀请了来自不同领域关于 Transformer 研究的前沿人士进行客座讲座。OpenAI 的研究科学家 Mark Chen,主要介绍基于 Transformers 的 GPT-3、Codex;Google Brain 的科学家 Lucas Beyer,主要介绍 Transformer 在视觉领域的应用;Meta FAIR 科学家 Aditya Grover,主要介绍 RL 中的 Transformer 以及计算引擎等。
值得一提的是,AI 教父 Geoff Hinton 也带来了一次讲座。
课程明细
1. (Sep 20) Introduction to Transformers
Recommended Readings:
2. (Sept 27) Transformers in Language: GPT-3, Codex
Speaker: Mark Chen (OpenAI)
Recommended Readings: - Language Models are Few-Shot
Learners
- Evaluating Large Language
Models Trained on Code
3. (Oct 4) Applications in Vision
Speaker: Lucas Beyer (Google Brain)
Recommended Readings: - An
Image is Worth 16x16 Words (Vision Transfomer)
- Additional Readings:
- How to train your
ViT?
4. (Oct 11) Transformers in RL & Universal Compute Engines
Speaker: Aditya Grover (FAIR)
Recommended Readings: - Pretrained Transformers as
Universal Computation Engines
- Decision Transformer:
Reinforcement Learning via Sequence Modeling
5. (Oct 18) Scaling transformers
Speaker: Barret Zoph (Google Brain) with Irwan Bello and Liam Fedus
Recommended Readings: - Switch Transformers: Scaling to
Trillion Parameter Models with Simple and Efficient Sparsity
- ST-MoE: Designing Stable
and Transferable Sparse Expert Models
6. (Oct 25) Perceiver: Arbitrary IO with transformers
Speaker: Andrew Jaegle (DeepMind)
Recommended Readings: - Perceiver: General Perception
with Iterative Attention
- Perceiver IO: A General
Architecture for Structured Inputs & Outputs
7. (Nov 1) Self Attention & Non-Parametric Transformers
Speaker: Aidan Gomez (University of Oxford)
Recommended Readings: - Self-Attention Between Datapoints: Going Beyond Individual Input-Output Pairs in Deep Learning
8. (Nov 8) GLOM: Representing part-whole hierarchies in a neural network
Speaker: Geoffrey Hinton (UoT) Recommended Readings:
9. (Nov 15) Interpretability with transformers
Speaker: Chris Olah (AnthropicAI)
Recommended Readings: - Multimodal Neurons in Artificial Neural Networks Additional Readings: - The Building Blocks of Interpretability
10. (Nov 29) Transformers for Applications in Audio, Speech and Music: From Language Modeling to Understanding to Synthesis
Speaker: Prateek Verma (Stanford)