Berkeley 2017年联合了DeepMind 以及 OpenAI 举办了一个大咖云集的深度强化学习训练营,是难得的前沿深度强化学习佳品,本公众号 MyEncyclopedia 用代码实现了权威教材 Sutton & Barto 第二版强化学习的基础部分之后,会大致沿着这个训练营的思路,从原理到代码逐步揭示强化深度学习面纱,并结合各种有意思的游戏环境来演示。
如果没有耐心的同学可以直接跳到文末的百度云盘下载链接,内容涵盖所有视频和slide。
此次训练营主讲的强化学习领域专家包括
Pieter Abbeel,前Berkeley 机器人学习实验室主任,伯克利人工智能研究(BAIR)实验室联合主任
Andrej Karpathy,前 OpenAI研究科学家、现特斯拉AI总监
Vlad Mnih,Deepmind 研究科学家
John Schulman,Deepmind 研究科学家,OpenAI共同创建人
Sergey Levine,Berkeley 计算机副教授

课程列表
- Core Lecture 1 Intro to MDPs and Exact Solution Methods -- Pieter Abbeel
- Core Lecture 2 Sample-based Approximations and Fitted Learning -- Rocky Duan
- Core Lecture 3 DQN + Variants -- Vlad Mnih
- Core Lecture 4a Policy Gradients and Actor Critic -- Pieter Abbeel
- Core Lecture 4b Pong from Pixels -- Andrej Karpathy
- Core Lecture 5 Natural Policy Gradients, TRPO, and PPO -- John Schulman
- Core Lecture 6 Nuts and Bolts of Deep RL Experimentation -- John Schulman
- Core Lecture 7 SVG, DDPG, and Stochastic Computation Graphs -- John Schulman
- Core Lecture 8 Derivative-free Methods -- Peter Chen
- Core Lecture 9 Model-based RL -- Chelsea Finn
- Core Lecture 10a Utilities -- Pieter Abbeel
- Core Lecture 10b Inverse RL -- Chelsea Finn
- Frontiers Lecture I: Recent Advances, Frontiers and Future of Deep RL -- Vlad Mnih
- Frontiers Lecture II: Recent Advances, Frontiers and Future of Deep RL -- Sergey Levine
- TAs Research Overviews
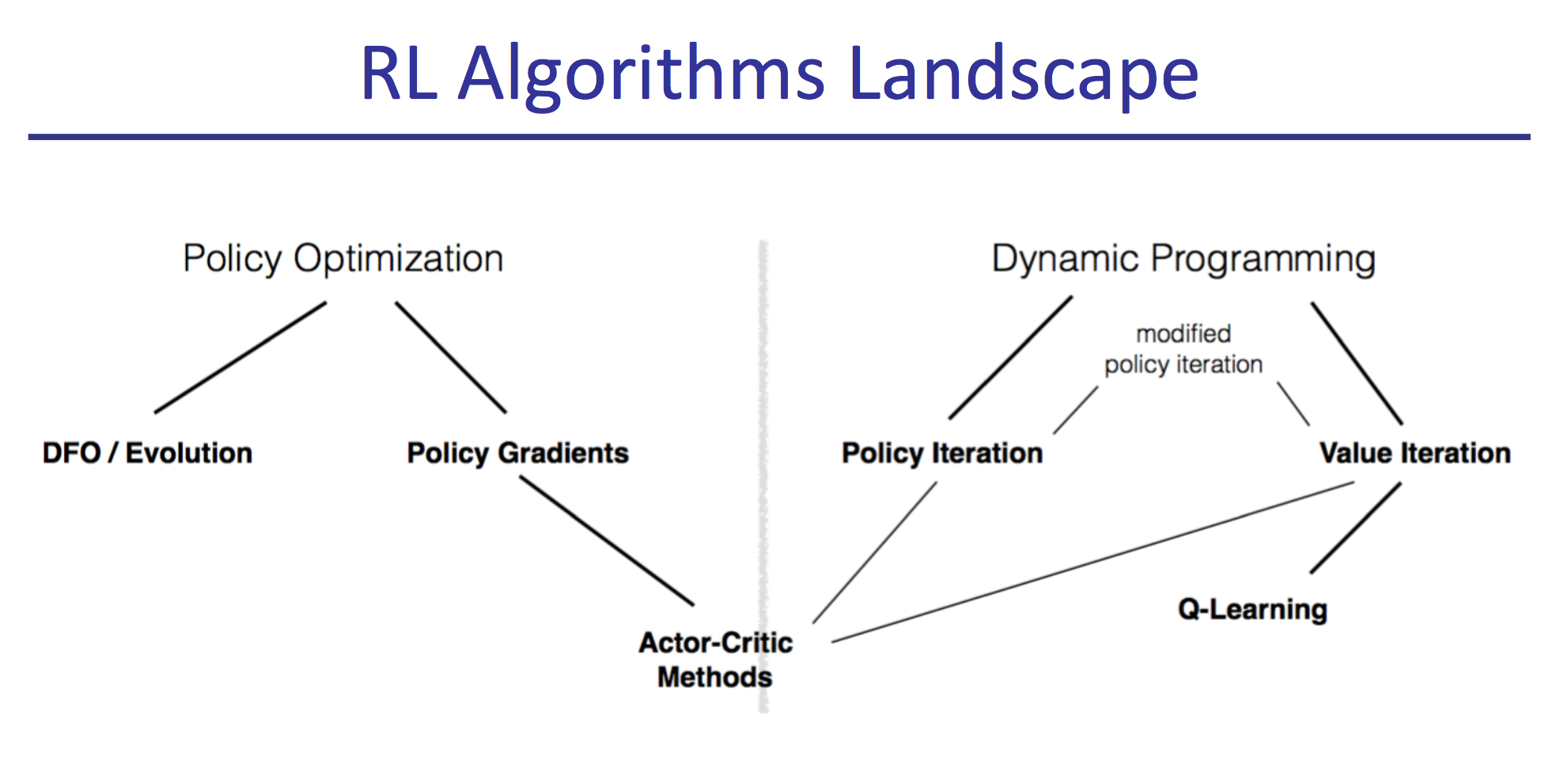
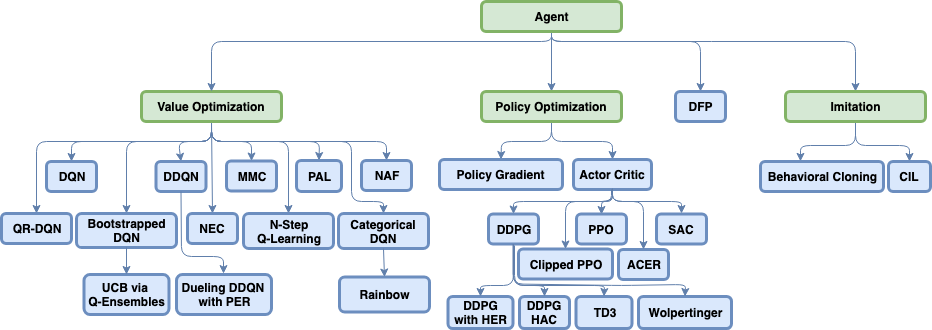
前两讲总结了强化学习基础理论方面,包括用动态规划求精确解,采样与环境交互的传统基本方法。第三四讲覆盖了主流的深度强化学习的几种模式:DQN,PG和AC。第五到七讲深入了深度强化学习的各种前沿方法。值得一提的是第六讲,很好的从实践中总结了各种调试诊断方法。余下的若干讲涉及到了非主流的剩余强化学习领域。
下载方法
关注 MyEncyclopedia 公众号,输入 rl-bootcamp-ucb-2017 即可获得百度云盘链接