继上一篇完成了井字棋(N子棋)的minimax
最佳策略后,我们基于Pygame来创造一个图形游戏环境,可供人机和机器对弈,为后续模拟AlphaGo的自我强化学习算法做环境准备。OpenAI
Gym 在强化学习领域是事实标准,我们最终封装成OpenAI
Gym的接口。本篇所有代码都在github.com/MyEncyclopedia/ConnectNGym 。
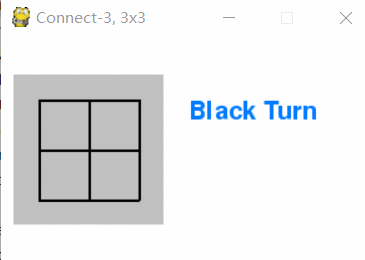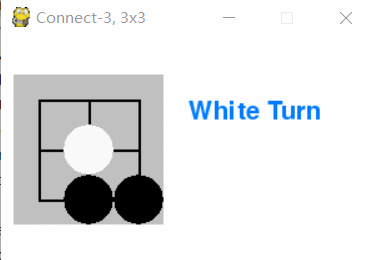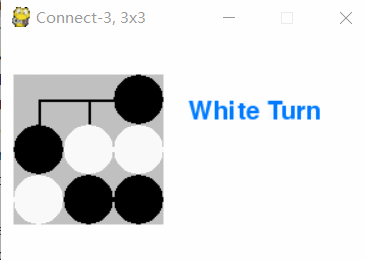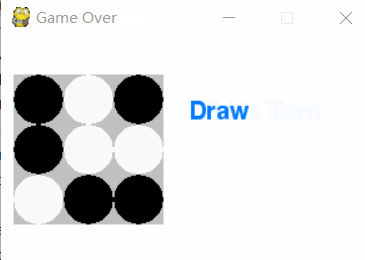
井字棋、五子棋 Pygame 实现
Pygame 井字棋玩家对弈效果
Python
上有Tkinter,PyQt等跨平台GUI类库,主要用于桌面程序编程,但此类库容量较大,编程也相对麻烦。Pygame具有代码少,开发快的优势,比较适合快速开发五子棋这类桌面小游戏。
### Pygame 极简入门
与所有的GUI开发相同,Pygame也是基于事件的单线程编程模型。下面的例子包含了显示一个最简单GUI窗口,操作系统产生事件并发送到Pygame窗口,while
True
控制了python主线程永远轮询事件。我们在这里仅仅判断了当前是否是关闭应用程序事件,如果是则退出进程。此外,clock
用于控制FPS。
{linenos 1 2 3 4 5 6 7 8 9 10 11 12 13 import sysimport pygamepygame.init() display = pygame.display.set_mode((800 ,600 )) clock = pygame.time.Clock() while True : for event in pygame.event.get(): if event.type == pygame.QUIT: sys.exit(0 ) else : pygame.display.update() clock.tick(1 )
PyGameBoard 主体代码
PyGameBoard类封装了Pygame实现游戏交互和显示的逻辑。上一篇中,我们完成了ConnectNGame逻辑,这里PyGameBoard需要在初始化时,指定传入ConnectNGame
实例(见下图),支持通过API
方式改变其状态,也支持GUI交互方式等待人类玩家的输入。next_user_input(self)实现了等待人类玩家输入的逻辑,本质上是循环检查GUI事件直到有合法的落子产生。
PyGameBoard Class Diagram
{linenos 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class PyGameBoard : def __init__ (self, connectNGame: ConnectNGame ): self.connectNGame = connectNGame pygame.init() def next_user_input (self ) -> Tuple [int , int ]: self.action = None while not self.action: self.check_event() self._render() self.clock.tick(60 ) return self.action def move (self, r: int , c: int ) -> int : return self.connectNGame.move(r, c) if __name__ == '__main__' : connectNGame = ConnectNGame() pygameBoard = PyGameBoard(connectNGame) while not pygameBoard.isGameOver(): pos = pygameBoard.next_user_input() pygameBoard.move(*pos) pygame.quit()
check_event
较之极简版本增加了处理用户输入事件,这里我们仅支持人类玩家鼠标输入。方法_handle_user_input
将鼠标点击事件转换成棋盘行列值,并判断点击位置是否合法,合法则返回落子位置,类型为Tuple[int,
int],例如(0, 0)表示棋盘最左上角位置。
{linenos 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 def check_event (self ): for e in pygame.event.get(): if e.type == pygame.QUIT: pygame.quit() sys.exit(0 ) elif e.type == pygame.MOUSEBUTTONDOWN: self._handle_user_input(e) def _handle_user_input (self, e: Event ) -> Tuple [int , int ]: origin_x = self.start_x - self.edge_size origin_y = self.start_y - self.edge_size size = (self.board_size - 1 ) * self.grid_size + self.edge_size * 2 pos = e.pos if origin_x <= pos[0 ] <= origin_x + size and origin_y <= pos[1 ] <= origin_y + size: if not self.connectNGame.gameOver: x = pos[0 ] - origin_x y = pos[1 ] - origin_y r = int (y // self.grid_size) c = int (x // self.grid_size) valid = self.connectNGame.checkAction(r, c) if valid: self.action = (r, c) return self.action
OpenAI Gym 接口规范
OpenAI
Gym规范了Agent和环境(Env)之间的互动,核心抽象接口类是gym.Env,自定义的游戏环境需要继承Env,并实现
reset、step和render方法。下面我们看一下如何具体实现ConnectNGym的这几个方法:
{linenos 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 class ConnectNGym (gym.Env ): def reset (self ) -> ConnectNGame: """Resets the state of the environment and returns an initial observation. Returns: observation (object): the initial observation. """ raise NotImplementedError def step (self, action: Tuple [int , int ] ) -> Tuple [ConnectNGame, int , bool , None ]: """Run one timestep of the environment's dynamics. When end of episode is reached, you are responsible for calling `reset()` to reset this environment's state. Accepts an action and returns a tuple (observation, reward, done, info). Args: action (object): an action provided by the agent Returns: observation (object): agent's observation of the current environment reward (float) : amount of reward returned after previous action done (bool): whether the episode has ended, in which case further step() calls will return undefined results info (dict): contains auxiliary diagnostic information (helpful for debugging, and sometimes learning) """ raise NotImplementedError def render (self, mode='human' ): """ Renders the environment. The set of supported modes varies per environment. (And some environments do not support rendering at all.) By convention, if mode is: - human: render to the current display or terminal and return nothing. Usually for human consumption. - rgb_array: Return an numpy.ndarray with shape (x, y, 3), representing RGB values for an x-by-y pixel image, suitable for turning into a video. - ansi: Return a string (str) or StringIO.StringIO containing a terminal-style text representation. The text can include newlines and ANSI escape sequences (e.g. for colors). Note: Make sure that your class's metadata 'render.modes' key includes the list of supported modes. It's recommended to call super() in implementations to use the functionality of this method. Args: mode (str): the mode to render with """ raise NotImplementedError
reset 方法
1 def reset (self ) -> ConnectNGame
重置环境状态,并返回给Agent重置后环境下观察到的状态。ConnectNGym内部维护了ConnectNGame实例作为自身状态,每个agent落子后会更新这个实例。由于棋类游戏对于玩家来说是完全信息的,我们直接返回ConnectNGame的deepcopy。
step 方法
1 def step (self, action: Tuple [int , int ] ) -> Tuple [ConnectNGame, int , bool , None ]
Agent 选择了某一action后,由环境来执行这个action并返回4个值:1.
执行后的环境Agent观察到的状态;2.
环境执行了这个action回馈给agent的reward;3. 环境是否结束;4.
其余信息。
step方法是最核心的接口,因此举例来说明ConnectNGym中的输入和输出:
初始状态
状态 ((0, 0, 0), (0, 0, 0), (0, 0, 0))
Agent A 选择action = (0, 0),执行ConnectNGym.step 后返回值:status =
((1, 0, 0), (0, 0, 0), (0, 0, 0)),reward = 0,game_end = False
状态 ((1, 0, 0), (0, 0, 0), (0, 0, 0))
Agent B 选择action = (1, 1),执行ConnectNGym.step 后返回值:status =
((1, 0, 0), (0, -1, 0), (0, 0, 0)),reward = 0,game_end = False
状态 ((1, 0, 0), (0, -1, 0), (0, 0, 0))
重复此过程直至游戏结束,下面是5步后游戏可能达到的最终状态
终结状态 ((1, 1, 1), (-1, -1, 0), (0, 0, 0))
此时step的返回值为:status = ((1, 1, 1), (-1, -1, 0), (0, 0,
0)),reward = 1,game_end = True
render 方法
1 def render (self, mode='human' )
展现环境,通过mode区分是否是人类玩家。
ConnectNGym 代码
{linenos 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class ConnectNGym (gym.Env ): def __init__ (self, pygameBoard: PyGameBoard, isGUI=True , displaySec=2 ): self.pygameBoard = pygameBoard self.isGUI = isGUI self.displaySec = displaySec self.action_space = spaces.Discrete(pygameBoard.board_size * pygameBoard.board_size) self.observation_space = spaces.Discrete(pygameBoard.board_size * pygameBoard.board_size) self.seed() self.reset() def reset (self ) -> ConnectNGame: self.pygameBoard.connectNGame.reset() return copy.deepcopy(self.pygameBoard.connectNGame) def step (self, action: Tuple [int , int ] ) -> Tuple [ConnectNGame, int , bool , None ]: r, c = action reward = REWARD_NONE result = self.pygameBoard.move(r, c) if self.pygameBoard.isGameOver(): reward = result return copy.deepcopy(self.pygameBoard.connectNGame), reward, not result is None , None def render (self, mode='human' ): if not self.isGUI: self.pygameBoard.connectNGame.drawText() time.sleep(self.displaySec) else : self.pygameBoard.display(sec=self.displaySec) def get_available_actions (self ) -> List [Tuple [int , int ]]: return self.pygameBoard.getAvailablePositions()
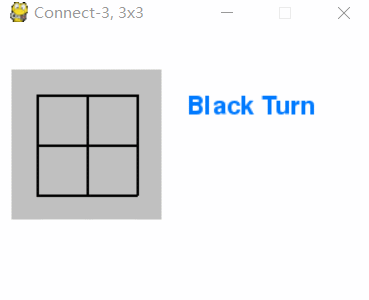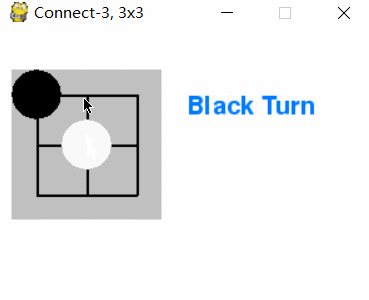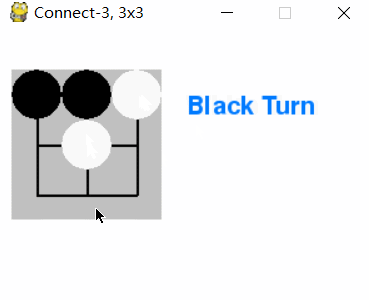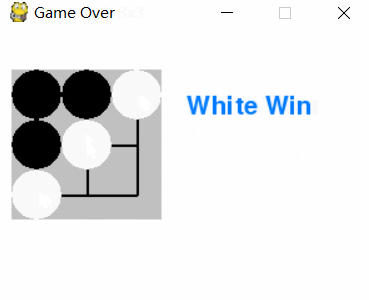
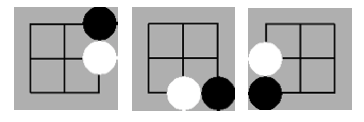
井字棋(N子棋)Minimax策略玩家
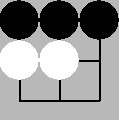
图中当k=3,m=n=3即井字棋游戏中,两个minimax策略玩家的对弈效果,游戏结局符合已知的结论:井字棋的解是先手被对方逼平。
Minimax策略AI对弈
镜像游戏状态的DP处理
上一篇中,我们确认了井字棋的总状态数是5478。当k=3,
m=n=4时是6035992,k=4,
m=n=4时是9722011,总的来说游戏状态数是以指数级增长的。上一版minimax
DP策略还有改善的空间,第一种是旋转格局的处理。对于任意一种棋盘格局可以得到90度旋转后的另外三种格局,它们的最佳结局是一致的。因此,我们在递归过程中解得某一棋盘格局后,将其另外三种旋转后格局的解也一起缓存起来。例如:
游戏状态1
旋转后的三种游戏状态
{linenos 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def similarStatus (self, status: Tuple [Tuple [int , ...]] ) -> List [Tuple [Tuple [int , ...]]]: ret = [] rotatedS = status for _ in range (4 ): rotatedS = self.rotate(rotatedS) ret.append(rotatedS) return ret def rotate (self, status: Tuple [Tuple [int , ...]] ) -> Tuple [Tuple [int , ...]]: N = len (status) board = [[ConnectNGame.AVAILABLE] * N for _ in range (N)] for r in range (N): for c in range (N): board[c][N - 1 - r] = status[r][c] return tuple ([tuple (board[i]) for i in range (N)])
Minimax 策略预计算
之前我们对每个棋局去计算最佳的下一步,并在此过程中做了剪枝,即当已经找到当前玩家必胜落子时直接返回。这对于单一局面的计算是较优的,但是AI
Agent
需要在每一步都重复这个过程,当棋盘大小>3时运算非常耗时,因此我们来做第二种优化。初始空棋盘时使用Minimax来保证遍历所有状态,缓存所有棋局的最佳结果。对于AI
Agent面临的每个棋局只需查找此棋局下所有的可能落子位置,并返回最佳决定,这样大大减少了每次棋局下重复的minimax递归计算。相关代码如下。
{linenos 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class PlannedMinimaxStrategy (Strategy ): def __init__ (self, game: ConnectNGame ): super ().__init__() self.game = copy.deepcopy(game) self.dpMap = {} self.result = self.minimax(game.getStatus()) def action (self, game: ConnectNGame ) -> Tuple [int , Tuple [int , int ]]: game = copy.deepcopy(game) player = game.currentPlayer bestResult = player * -1 bestMove = None for move in game.getAvailablePositions(): game.move(*move) status = game.getStatus() game.undo() result = self.dpMap[status] if player == ConnectNGame.PLAYER_A: bestResult = max (bestResult, result) else : bestResult = min (bestResult, result) bestMove = move if bestResult == result else bestMove print (f'move {move} => {result} ' ) return bestResult, bestMove
Agent 类和对弈逻辑
Agent 类的抽象并不是 OpenAI
Gym的规范,出于代码扩展性,我们也封装了Agent基类及其子类,包括AI玩家和人类玩家。BaseAgent需要子类实现
act方法,默认实现为随机决定。
{linenos 1 2 3 4 5 6 class BaseAgent (object def __init__ (self ): pass def act (self, game: PyGameBoard, available_actions ): return random.choice(available_actions)
AIAgent 实现act并代理给 strategy 的action方法。
{linenos 1 2 3 4 5 6 7 8 class AIAgent (BaseAgent ): def __init__ (self, strategy: Strategy ): self.strategy = strategy def act (self, game: PyGameBoard, available_actions ): result, move = self.strategy.action(game.connectNGame) assert move in available_actions return move
HumanAgent 实现act并代理给 PyGameBoard 的next_user_input方法。
{linenos 1 2 3 4 5 6 class HumanAgent (BaseAgent ): def __init__ (self ): pass def act (self, game: PyGameBoard, available_actions ): return game.next_user_input()
Agent Class Diagram
下面代码展示如何将Agent,ConnectNGym,PyGameBoard
等所有上述类串联起来,完成人人对弈,人机对弈。
{linenos 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 def play_ai_vs_ai (env: ConnectNGym ): plannedMinimaxAgent = AIAgent(PlannedMinimaxStrategy(env.pygameBoard.connectNGame)) play(env, plannedMinimaxAgent, plannedMinimaxAgent) def play (env: ConnectNGym, agent1: BaseAgent, agent2: BaseAgent ): agents = [agent1, agent2] while True : env.reset() done = False agent_id = -1 while not done: agent_id = (agent_id + 1 ) % 2 available_actions = env.get_available_actions() agent = agents[agent_id] action = agent.act(pygameBoard, available_actions) _, reward, done, info = env.step(action) env.render(True ) if done: print (f'result={reward} ' ) time.sleep(3 ) break if __name__ == '__main__' : pygameBoard = PyGameBoard(connectNGame=ConnectNGame(board_size=3 , N=3 )) env = ConnectNGym(pygameBoard) env.render(True ) play_ai_vs_ai(env)
Class Diagram 总览





评论
shortnamefor Disqus. Please set it in_config.yml.