AlphaGo Zero是Deepmind 最后一代AI围棋算法,因为已经达到了棋类游戏AI的终极目的:给定任何游戏规则,AI从零出发只通过自我对弈的方式提高,最终可以取得超越任何对手(包括顶级人类棋手和上一代AlphaGo)的能力。换种方式说,当给定足够多的时间和计算资源,可以取得无限逼近游戏真实解的能力。这一篇,我们深入分析AlphaGo Zero的设计理念和关键组件的细节并解释组件之间的关联。下一篇中,我们将在已有的N子棋OpenAI Gym 环境中用Pytorch实现一个简化版的AlphaGo Zero算法。
AlphaGo Zero 综述
AlphaGo Zero 作为Deepmind在围棋领域的最后一代AI Agent,已经可以达到棋类游戏的终极目标:在只给定游戏规则的情况下,AI 棋手从最初始的随机状态开始,通过不断的自我对弈的强化学习来实现超越以往任何人类棋手和上一代Alpha的能力,并且同样的算法和模型应用到了其他棋类也得出相同的效果。这一篇,从原理上来解析AlphaGo Zero的运行方式。
AlphaGo Zero 算法由三种元素构成:强化学习(RL)、深度学习(DL)和蒙特卡洛树搜索(MCTS,Monte Carlo Tree Search)。核心思想是基于神经网络的Policy Iteration强化学习,即最终学的是一个深度学习的policy network,输入是某棋盘局面 s,输出是此局面下可走位的概率分布:\(p(a|s)\)。
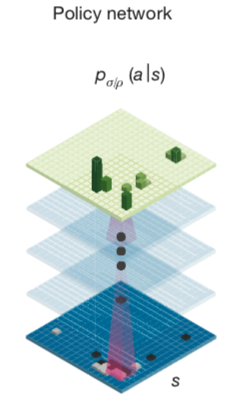
在第一代AlphaGo算法中,这个初始policy network通过收集专业人类棋手的海量棋局训练得来,再采用传统RL 的Monte Carlo Tree Search Rollout 技术来强化现有的AI对于局面落子(Policy Network)的判断。Monte Carlo Tree Search Rollout 简单说来就是海量棋局模拟,AI Agent在通过现有的Policy Network策略完成一次从某局面节点到最终游戏胜负结束的对弈,这个完整的对弈叫做rollout,又称playout。完成一次rollout之后,通过局面树层层回溯到初始局面节点,并在回溯过程中同步修订所有经过的局面节点的统计指标,修正原先policy network对于落子导致输赢的判断。通过海量并发的棋局模拟来提升基准policy network,即在各种局面下提高好的落子的\(p(a_{win}|s)\),降低坏的落子的\(p(a_{lose}|s)\)
举例如下井字棋局面: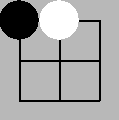
基准policy network返回 p(s) 如下 \[ p(a|s) = \begin{align*} \left\lbrace \begin{array}{r@{}l} 0.1, & & a = (0,2) \\ 0.05, & & a = (1,0) \\ 0.5, & & a = (1,1) \\ 0.05, & & a = (1,2)\\ 0.2, & & a = (2,0) \\ 0.05, & & a = (2,1) \\ 0.05, & & a = (2,2) \end{array} \right. \end{align*} \] 通过海量并发模拟后,修订成如下的action概率分布,然后通过policy iteration迭代新的网络来逼近 \(p'\) 就提高了棋力。 \[ p'(a|s) = \begin{align*} \left\lbrace \begin{array}{r@{}l} 0, & & a = (0,2) \\ 0, & & a = (1,0) \\ 0.9, & & a = (1,1) \\ 0, & & a = (1,2)\\ 0, & & a = (2,0) \\ 0, & & a = (2,1) \\ 0.1, & & a = (2,2) \end{array} \right. \end{align*} \]
蒙特卡洛树搜索(MCTS)概述
Monte Carlo Tree Search 是Monte Carlo 在棋类游戏中的变种,棋类游戏的一大特点是可以用动作(move)联系的决策树来表示,树的节点数量取决于分支的数量和树的深度。MCTS的目的是在树节点非常多的情况下,通过实验模拟(rollout, playout)的方式来收集尽可能多的局面输赢情况,并基于这些统计信息,将搜索资源的重点均衡地放在未被探索的节点和值得探索的节点上,减少在大概率输的节点上的模拟资源投入。传统MCTS有四个过程:Selection, Expansion, Simulation 和Backpropagation。下图是Wikipedia 的例子:
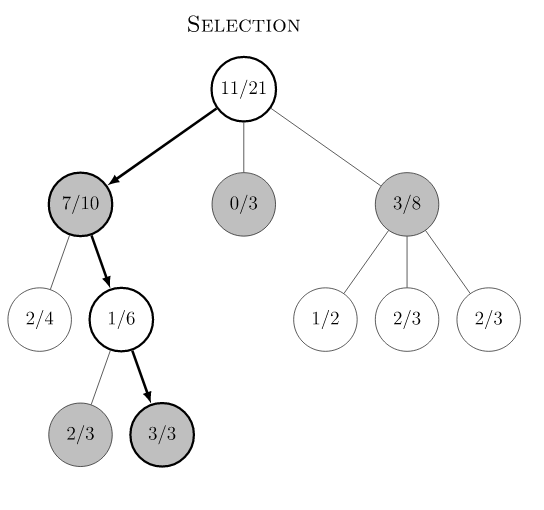
- Selection:从根节点出发,根据现有统计的信息和selection规则,选择子节点递归向下做决定,后面我们会详细介绍AlphaGo的UCB规则。图中节点的数字,例如根节点11/21,分别代表赢的次数和总模拟次数。从根节点一路向下分别选择节点 7/10, 1/6直到叶子节点3/3,叶子节点表示它未被探索过。
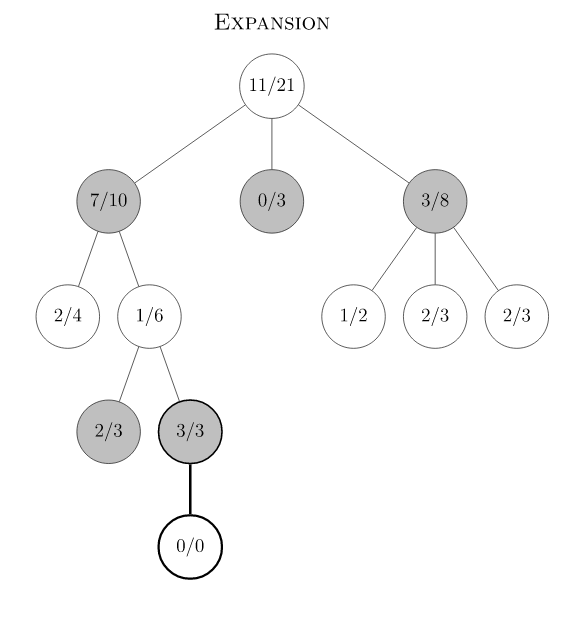
- Expansion:由于3/3节点未被探索过,初始化其所有子节点为0/0,图中3/3只有一个子节点。后面我们会看到神经网络在初始化子节点的时候起到的指导作用,即所有子节点初始权重并非相同,而是由神经网络给出估计。
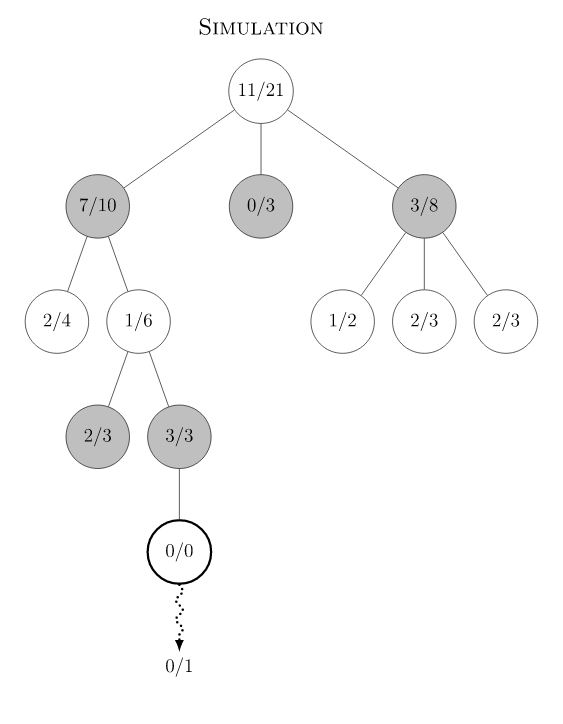
- Simulation:重复selection和expansion,根据游戏规则递归向下直至游戏结束。
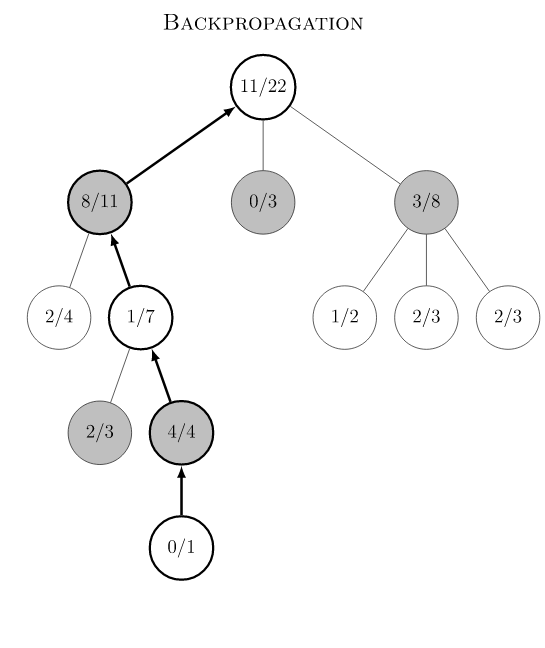
- Backpropagation:游戏结束在终点节点产生游戏真实的价值,回溯向上调整所有父节点的统计状态。
权衡 Exploration 和 Exploitation
在不断扩张决策树并收集节点统计信息的同时,MCTS根据规则来权衡探索目的(采样不足)或利用目的来做决策,这个权衡规则叫做Upper Confidence Bound(UCB)。典型的UCB公式如下:w表示通过节点的赢的次数,n表示通过节点的总次数,N是父节点的访问次数,c是调节Exploration 和 Exploitation权重的超参。
\[ {\frac{w_i}{n_i}} + c \sqrt{\frac{\ln N_i}{n_i}} \]
假设某节点有两个子节点s1, s2,它们的统计指标为 s1: w/n = 3/4,s2: w/n = 6/8,由于两者输赢比率一样,因此根据公式,访问次数少的节点出于Exploration的目的胜出,MCTS最终决定从s局面走向s1。
从第一性原理来理解AlphaGo Zero
前一代的AlphaGo已经战胜了世界冠军,取得了空前的成就,AlphaGo Zero 的设计目标变得更加General,去除围棋相关的处理和知识,用统一的框架和算法来解决棋类问题。 1. 无人工先验数据
改进之前需要专家棋手对弈数据来冷启动初始棋力
无特定游戏特征工程
无需围棋特定技巧,只包含下棋规则,可以适用到所有棋类游戏
单一神经网络
统一Policy Network和Value Network,使用一个共享参数的双头神经网络
简单树搜索
去除传统MCTS的Rollout 方式,用神经网络来指导MCTS更有效产生搜索策略
搜索空间的两个优化原则
尽管理论上围棋是有解的,即先手必赢、被逼平或必输,通过遍历所有可能局面可以求得解。同理,通过海量模拟所有可能游戏局面,也可以无限逼近所有局面下的真实输赢概率,直至收敛于局面落子的确切最佳结果。但由于围棋棋局的数目远远大于宇宙原子数目,3^361 >> 10^80,因此需要将计算资源有效的去模拟值得探索的局面,例如对于显然的被动局面减小模拟次数,所以如何有效地减小搜索空间是AlphaGo Zero 需要解决的重大问题。David Silver 在Deepmind AlphaZero - Mastering Games Without Human Knowledge中提到AlphaGo Zero 采用两个原则来有效减小搜索空间。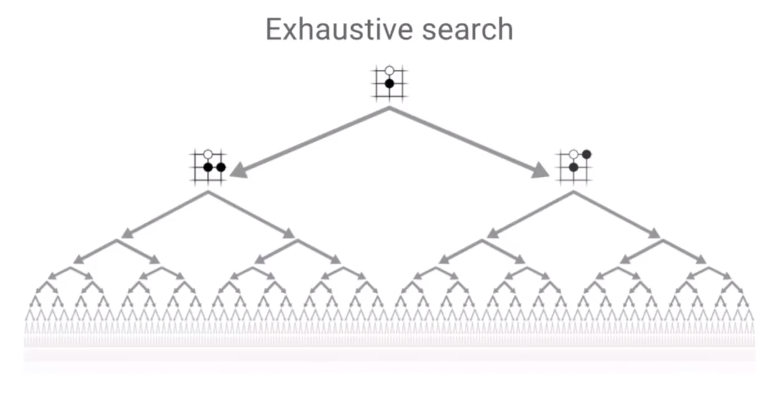
原则1: 通过Value Network减少搜索的深度
Value Network 通过预测给定局面的value来直接预测最终结果,思想和上一期Minimax DP 策略中直接缓存当前局面的胜负状态一样,减少每次必须靠模拟到最后才能知道当前局面的输赢概率,或者需要多层树搜索才能知道输赢概率。
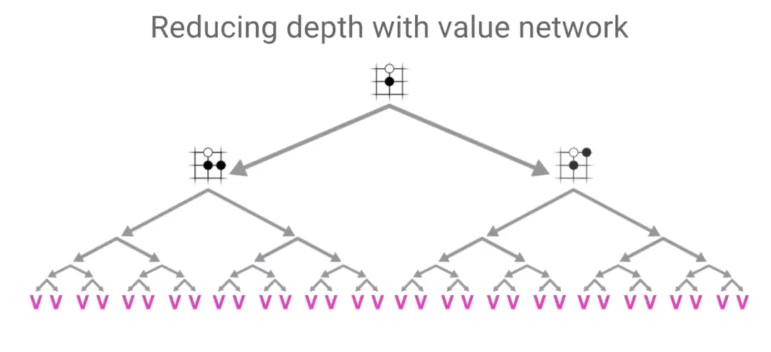
原则2: 通过Policy Network减少搜索的宽度
搜索广度的减少是由Policy Network预估来达成的,将下一步搜索局限在高概率的动作上,大幅度提升原先MCTS新节点生成后冷启动的搜索宽度。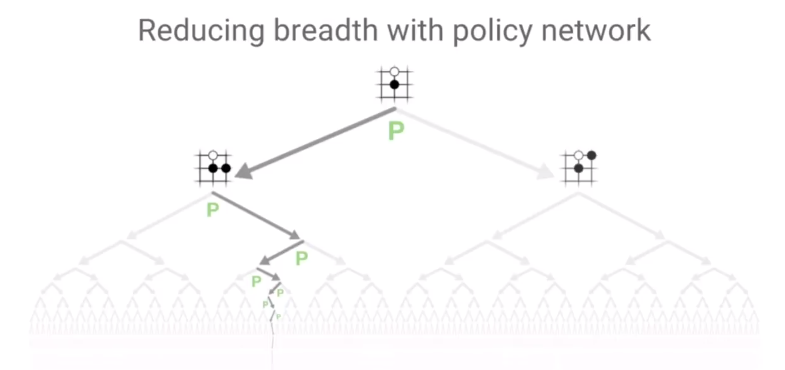
神经网络结构
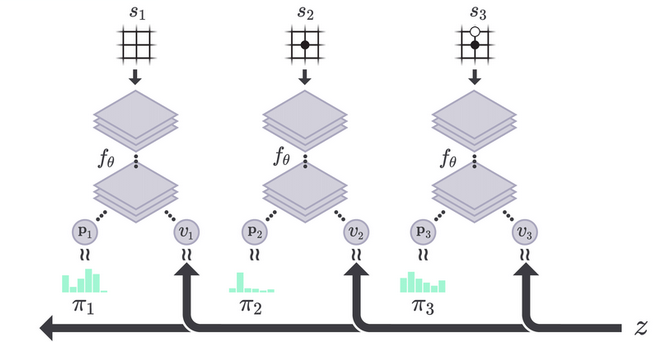
AlphaGo Zero 使用一个单一的深度神经网络来完成policy 和value的预测。具体实现方式是将policy network和value network合并成一个共享参数 $ $ 的双头网络。其中z是真实游戏结局的效用,范围为[-1, 1] 。
\[ (p, v)=f_{\theta}(s) \] \[ p_{a}=\operatorname{Pr}(a \mid s) \] \[ v = \mathop{\mathbb{E}}[z|s] \]
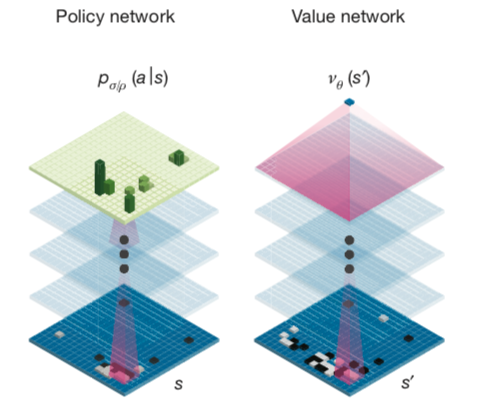
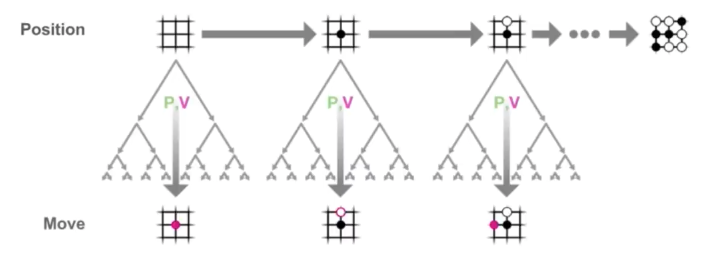
Monte Carlo Tree Search (MCTS) 建立了棋局搜索树,节点的初始状态由神经网络输出的p和v值来估计,由此初始的动作策略和价值预判就会建立在高手的水平之上。模拟一局游戏之后向上回溯,会同步更新路径上节点的统计数值并生成更好的MCTS搜索策略 \(\vec{\pi}\)。进一步来看,MCTS和神经网络互相形成了正循环。神经网络指导了未知节点的MCTS初始搜索策略,产生自我对弈游戏结局后,通过减小 \(\vec{p}\) 和\(\vec{\pi}\)的 Loss ,最终又提高了神经网络对于局面的估计能力。神经网络value network的提升也是通过不断减小网络预测的结果和最终结果的差异来提升。 因此,具体神经网络的Loss函数由三部分组成,value network的损失,policy network的损失以及正则项。 \[ l=\sum_{t}\left(v_{\theta}\left(s_{t}\right)-z_{t}\right)^{2}-\vec{\pi}_{t} \cdot \log \left(\vec{p}_{\theta}\left(s_{t}\right)\right) + c {\lVert \theta \rVert}^2 \]
AlphaGo Zero MCTS 具体过程
AlphaGo Zero的MCTS和传统MCTS都有相似的四个过程,但AlphaGo Zero的MCTS步骤相对更复杂。 首先,除了W/N统计指标之外,AlphaGo Zero的MCTS保存了决策边 a|s 的Q(s,a):Action Value,也就是Q-Learning中的Q值,其初始值由神经网络给出。此外,Q 值也用于串联自底向上更新节点的Value值。具体说来,当某个新节点被Explore后,会将网络给出的Q值向上传递,并逐层更新父节点的Q值。当游戏结局产生时,也会向上更新所有父节点的Q值。 此外对于某一游戏局面s进行多次模拟,每次在局面s出发向下探索,每次探索在已知节点按Selection规则深入一步,直至达到未探索的局面或者游戏结束,产生Q值后向上回溯到最初局面s,回溯过程中更新路径上的局面的统计值或者Q值。在多次模拟结束后根据Play的算法,决定局面s的下一步行动。尽管每次模拟探索可能会深入多层,但最终play阶段的算法规则仅决定给定局面s的下一层落子动作。多次向下探索的优势在于:
探索和采样更多的叶子节点,在更多信息下做决策。
通过average out多次模拟下一层落子决定,尽可能提升MCTS策略的下一步判断能力,提高 \(\pi\) 能力,更有效指导神经网络,提高其学习效率。
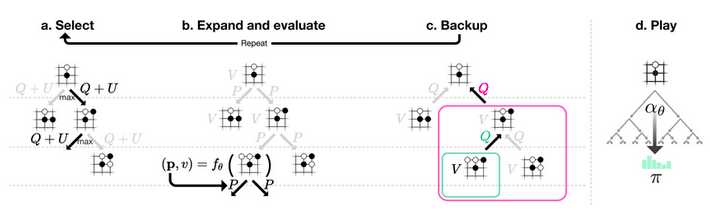
- Selection:
从游戏局面s开始,选择a向下递归,直至未展开的节点(搜索树中的叶子节点)或者游戏结局。具体在局面s下选择a的规则由以下UCB(Upper
Confidence Bound)决定
\[
a=\operatorname{argmax}_a(Q(s,a) + u(s,a))
\]
其中,Q(s,a) 和u(s,a) 项分别代表Exploitation 和Exploration。两项相加来均衡Exploitation和Exploration,保证初始时每个节点被explore,在有足够多的信息时逐渐偏向exploitation。
\[ u(s, a)=c_{p u c t} \cdot P(s, a) \cdot \frac{\sqrt{\Sigma_{b} N(s, b)}}{1+N(s, a)} \]
- Expand
当遇到一个未展开的节点(搜索树中的叶子节点)时,对其每个子节点使用现有网络进行预估,即
\[ (p(s), v(s))=f_{\theta}(s) \]
- Backup
当新的叶子节点展开时或者到达终点局面时,向上更新父节点的Q值,具体公式为 \[ Q(s, a)=\frac{1}{N(s, a)} \sum_{s^{\prime} \mid s, a \rightarrow s^{\prime}} V\left(s^{\prime}\right) \]
- Play
多次模拟结束后,使用得到搜索概率分布 ${a} $来确定最终的落子动作。正比于访问次数的某次方 $ {a} N(s, a)^{1 / }\(,其中\)$为温度参数(temperature parameter)。
参考资料
Youtube, Deepmind AlphaZero - Mastering Games Without Human Knowledge, David Silver
Mastering the game of Go with deep neural networks and tree search
Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm

评论
shortnamefor Disqus. Please set it in_config.yml.