上一篇中,我们知道AlphaGo Zero 的MCTS树搜索是基于传统MCTS 的UCT (UCB
for Tree)的改进版PUCT(Polynomial Upper Confidence
Trees)。局面节点的PUCT值由两部分组成,分别是代表Exploitation的action
value Q值,和代表Exploration的U值。 \[
PUCT(s, a) =Q(s,a) + U(s,a)
\] U值计算由这些参数决定:系数\(c_{puct}\),节点先验概率P(s, a)
,父节点访问次数,本节点的访问次数。具体公式如下 \[
U(s, a)=c_{p u c t} \cdot P(s, a) \cdot \frac{\sqrt{\Sigma_{b} N(s,
b)}}{1+N(s, a)}
\]
_parent: TreeNode _children: Dict[int, TreeNode] # map from action to TreeNode _visit_num: int _Q: float# Q value of the node, which is the mean action value. _prior: float
和上面的计算公式相对应,下列代码根据节点状态计算PUCT(s, a)。
{linenos
1 2 3 4 5 6 7 8 9 10
classTreeNode:
defget_puct(self) -> float: """ Computes AlphaGo Zero PUCT (polynomial upper confidence trees) of the node. :return: Node PUCT value. """ U = (TreeNode.c_puct * self._prior * np.sqrt(self._parent._visit_num) / (1 + self._visit_num)) return self._Q + U
AlphaGo Zero
MCTS在playout时遇到已经被展开的节点,会根据selection规则选择子节点,该规则本质上是在所有子节点中选择最大的PUCT值的节点。
defpropagate_to_root(self, leaf_value: float): """ Updates current node with observed leaf_value and propagates to root node. :param leaf_value: :return: """ if self._parent: self._parent.propagate_to_root(-leaf_value) self._update(leaf_value)
def_update(self, leaf_value: float): """ Updates the node by newly observed leaf_value. :param leaf_value: :return: """ self._visit_num += 1 # new Q is updated towards deviation from existing Q self._Q += 0.5 * (leaf_value - self._Q)
AlphaGo Zero MCTS Player
实现
AlphaGo Zero MCTS
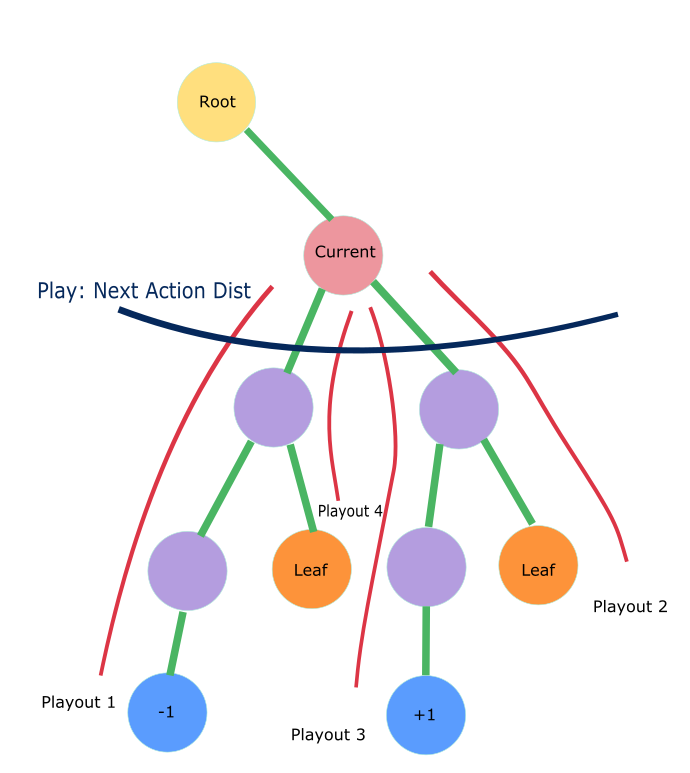
在训练阶段分为如下几个步骤。游戏初始局面下,整个局面树的建立由子节点的不断被探索而丰富起来。AlphaGo
Zero对弈一次即产生了一次完整的游戏开始到结束的动作系列。在对弈过程中的某一游戏局面,需要采样海量的playout,又称MCTS模拟,以此来决定此局面的下一步动作。一次playout可视为在真实游戏状态树的一种特定采样,playout可能会产生游戏结局,生成真实的v值;也可能explore
到新的叶子节点,此时v值依赖策略价值网络的输出,目的是利用训练的神经网络来产生高质量的游戏对战局面。每次playout会从当前给定局面递归向下,向下的过程中会遇到下面三种节点情况。
def_next_step_play_act_probs(self, game: ConnectNGame) -> Tuple[List[Pos], ActionProbs]: """ For the given game status, run playouts number of times specified by self._playout_num. Returns the action distribution according to AlphaGo Zero MCTS play formula. :param game: :return: actions and their probability """
for n inrange(self._playout_num): self._playout(copy.deepcopy(game))
defget_action(self, board: PyGameBoard) -> Pos: """ Method defined in BaseAgent. :param board: :return: next move for the given game board. """ return self._get_action(copy.deepcopy(board.connect_n_game))[0]
# the pi defined in AlphaGo Zero paper acts, act_probs = self._next_step_play_act_probs(game) move_probs[list(acts)] = act_probs if self._is_training: # add Dirichlet Noise when training in favour of exploration p_ = (1-epsilon) * act_probs + epsilon * np.random.dirichlet(0.3 * np.ones(len(act_probs))) move = np.random.choice(acts, p=p_) assert move in game.get_avail_pos() else: move = np.random.choice(acts, p=act_probs)
defself_play_one_game(self, game: ConnectNGame) \ -> List[Tuple[NetGameState, ActionProbs, NDArray[(Any), np.float]]]: """ :param game: :return: Sequence of (s, pi, z) of a complete game play. The number of list is the game play length. """
classMCTSAlphaGoZeroPlayer(BaseAgent): def_playout(self, game: ConnectNGame): """ From current game status, run a sequence down to a leaf node, either because game ends or unexplored node. Get the leaf value of the leaf node, either the actual reward of game or action value returned by policy net. And propagate upwards to root node. :param game: """ player_id = game.current_player
# now game state is a leaf node in the tree, either a terminal node or an unexplored node act_and_probs: Iterator[MoveWithProb] act_and_probs, leaf_value = self._policy_value_net.policy_value_fn(game)
ifnot game.game_over: # case where encountering an unexplored leaf node, update leaf_value estimated by policy net to root for act, prob in act_and_probs: game.move(act) child_node = node.expand(act, prob) game.undo() else: # case where game ends, update actual leaf_value to root if game.game_result == ConnectNGame.RESULT_TIE: leaf_value = ConnectNGame.RESULT_TIE else: leaf_value = 1if game.game_result == player_id else -1 leaf_value = float(leaf_value)
# Update leaf_value and propagate up to root node node.propagate_to_root(-leaf_value)
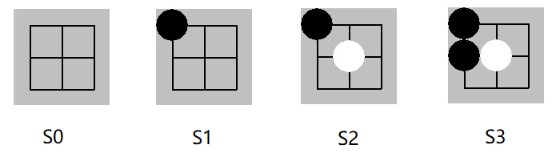
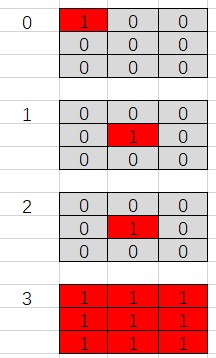
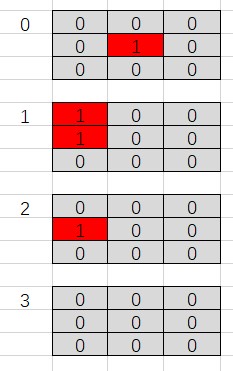
defconvert_game_state(game: ConnectNGame) -> NetGameState: """ Converts game state to type NetGameState as ndarray. :param game: :return: Of shape 4 * board_size * board_size. [0] is current player positions. [1] is opponent positions. [2] is last move location. [3] all 1 meaning move by black player, all 0 meaning move by white. """ state_matrix = np.zeros((4, game.board_size, game.board_size))
if game.action_stack: actions = np.array(game.action_stack) move_curr = actions[::2] move_oppo = actions[1::2] for move in move_curr: state_matrix[0][move] = 1.0 for move in move_oppo: state_matrix[1][move] = 1.0 # indicate the last move location state_matrix[2][actions[-1]] = 1.0 iflen(game.action_stack) % 2 == 0: state_matrix[3][:, :] = 1.0# indicate the colour to play return state_matrix[:, ::-1, :]


评论
shortnamefor Disqus. Please set it in_config.yml.