
导读:这篇式1999 年Richard Sutton 在强化学习领域中的经典论文,论文证明了策略梯度定理和在用函数近似 Q 值时策略梯度定理依然成立,本文奠定了后续以深度强化学习策略梯度方法的基石。理解熟悉本论文对 Policy Gradient,Actor Critic 方法有很好的指导意义。
论文分成四部分。第一部分指出策略梯度在两种期望回报定义下都成立(定理一)。第二部分提出,如果 \(Q^{\pi}\) 被函数 \(f_w\) 近似时且满足兼容(compatible)条件,以 \(f_w\) 替换策略梯度中的 \(Q^{\pi}\)公式也成立(定理二)。第三部分举Gibbs分布的策略为例,如何应用 \(Q^{\pi}\)近似函数来实现策略梯度算法。第四部分证明了近似函数的策略梯度迭代法一定能收敛到局部最优解。附录部分证明了两种定义下的策略梯度定理。
1. 策略梯度定理
对于Agent和环境而言,可以分成episode和non-episode,后者的时间步骤可以趋近于无穷大,但一般都可以适用两种期望回报定义。一种是单步平均reward ,另一种是指定唯一开始状态并对trajectory求 \(\gamma\)-discounted 之和,称为开始状态定义。两种定义都考虑到了reward的sum会趋近于无穷大,通过不同的方式降低了此问题的概率。
A. 平均reward定义
目标函数 \(\rho(\pi)\) 定义成单步的平均reward,这种情况下等价于稳定状态分布下期望值。
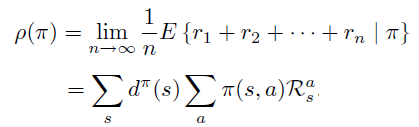
稳定状态分布定义成无限次数后状态的分布。
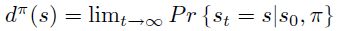
此时,\(Q^{\pi}\) 定义为无限步的reward sum 减去累积的单步平均 reward \(\rho(\pi)\),这里减去\(\rho(\pi)\)是为了一定程度防止 \(Q^{\pi}\)没有上界。
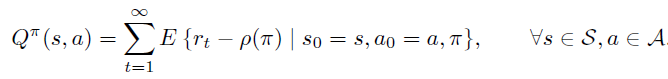
B. 开始状态定义
在开始状态定义方式中,某指定状态\(s_0\)作为起始状态,\(\rho(\pi)\) 的定义为 trajectory 的期望回报,注意由于时间步骤 t 趋近于无穷大,必须要乘以discount 系数 \(\gamma < 1\) 保证期望不会趋近无穷大。
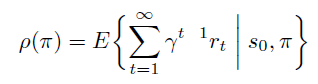
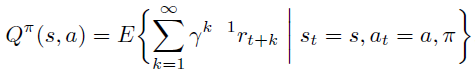
\(d^{\pi}\) 依然为无限次数后状态的稳定分布。
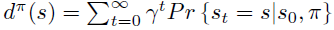
策略梯度定理
论文指出上述两种定义都满足策略梯度定理,即目标 \(\rho\) 对于参数 \(\theta\) 的偏导不依赖于 \(d^{\pi}\) 对于 \(\theta\) 偏导,仅取决
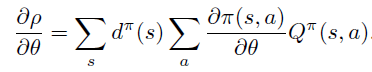
关于策略梯度定理的一些综述,可以参考。
论文中还提到策略梯度定理公式和经典的William REINFORCE算法之间的联系。REINFORCE算法即策略梯度的蒙特卡洛实现。
联系如下:
首先,根据策略梯度定理,如果状态 s 是通过 \(\pi\) 采样得到,则下式是$$ 的无偏估计。注意,这里action的summation和 \(\pi\) 是无关的。
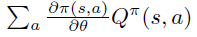
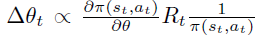
2. 函数近似的策略梯度
论文第二部分,进一步引入 \(Q_{\pi}\) 的近似函数 \(f_w\): $ $。
如果我们有\(Q_{\pi}(s_t, a_t)\)的无偏估计,例如 \(R_t\),很自然,可以让 \(\partial f_w \over \partial w\) 通过最小化 \(R_t\) 和 \(f_w\)之间的差距来计算。
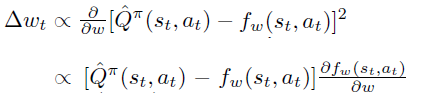
当拟合过程收敛到局部最优时,策略梯度定理中右边项对于 \(w\) 求导为0,可得(3)式。
.png)
至此,引出策略梯度定理的延续,即定理2:当 \(f_w\) 满足(3)式同时满足(4)式(称为compatible条件时),可以用 \(f_w(s, a)\)替换原策略梯度中的 \(Q_{\pi}(s,a)\)

3. 一个应用示例
假设一个策略用features的线性组合后的 Gibbs分布来生成,即:
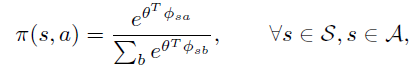
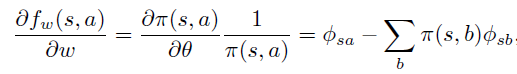
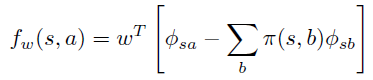
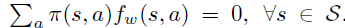
上式和advantage 函数 \(A^{\pi}(s, a)\) 定义一致,因此可以认为 \(f_w\) 的意义是 \(A^{\pi}\) 的近似。
\(A^{\pi}\)具体定义如下
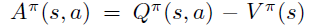
4. 函数近似的策略梯度收敛性证明
这一部分证明了在满足一定条件后,\(\theta\) 可以收敛到局部最优点。
条件为
- Compatible 条件,公式(4)
- 任意两个 \(\partial \pi \over \partial \theta\) 偏导是有限的,即
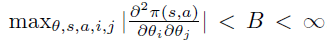
- 步长数列满足如下条件
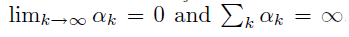
环境的 reward 是有限的
此时,当 \(w_k\) 和 \(\theta_k\) 按如下方式迭代一定能收敛到局部最优。
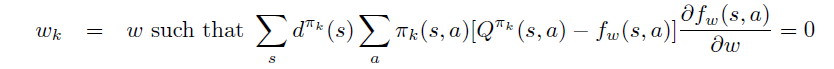
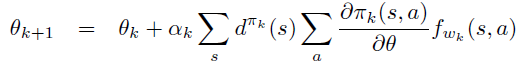
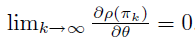
5. 策略梯度定理的两种情况下的证明
下面简单分解策略梯度的证明步骤。
A. 平均reward 定义下的证明
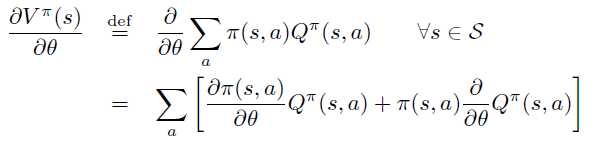
根据定义,将 \(\theta\) 导数放入求和号中,并分别对乘积中的每项求导。
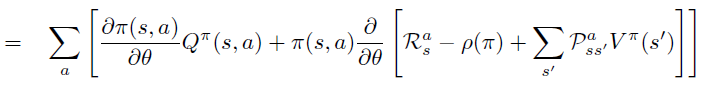
将\(Q_{\pi}\)的定义代入第二项 \(Q^{\pi}\) 对 \(\theta\) 求偏导中,引入环境reward 随机变量 \(R^a_s\),环境dynamics \(P\) 和 \(\rho(\pi)\)
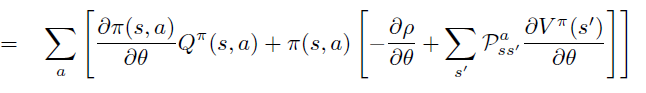
\(\theta\) 偏导进一步移入,\(R^a_s\), \(P\) 不依赖于\(\theta\)。
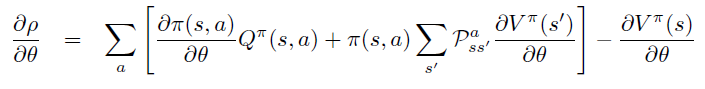
\(\rho(\pi)\) 对于 \(\theta\) 偏导整理到等式左边
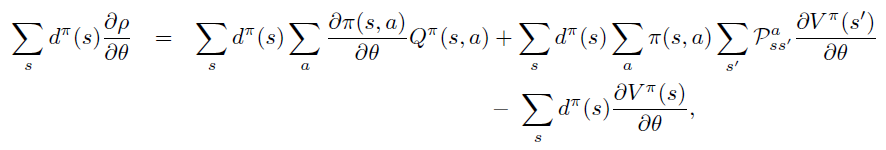
两边同时乘以 \(\sum d^{\pi}\)
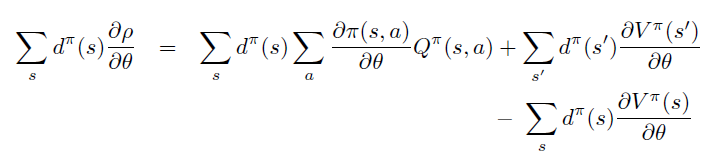
由于 \(d^{\pi}\) 是状态在 \(\pi\) 下的平稳分布,\(\sum \pi \sum P\) 项表示 agent 主观 \(\pi\) 和环境客观 \(P\) 对于状态分布的影响,因此可以直接去除。
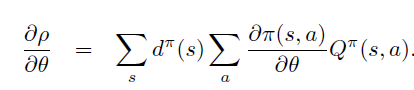
整理证得。
B. Start-state 定义下的证明
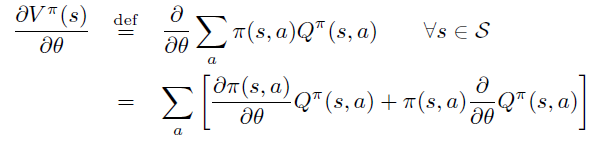
根据定义,将 \(\theta\) 导数放入求和号中,并分别对乘积中的每项求导。
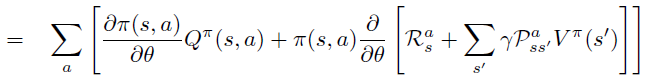
将\(Q_{\pi}\)的定义代入第二项 \(Q^{\pi}\) 对 \(\theta\) 求偏导中,引入环境reward 随机变量 \(R^a_s\),环境dynamics \(P\)
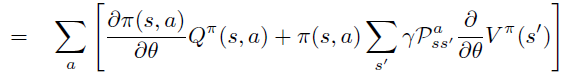
\(\theta\) 偏导进一步移入,\(R^a_s\), \(P\) 不依赖于\(\theta\)。注意,此式表示从状态 \(s\) 出发一步之后的能到达的所有 \(s^{\prime}\) ,将次式反复unroll \(V^{\pi}\) 成 \(Q^{\pi}\) 之后得到
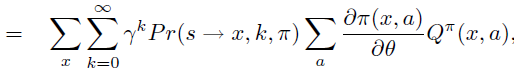
\(\operatorname{Pr}(s \rightarrow x, k, \pi)\) 表示 k 步后 状态 s 能到达的所有状态 x
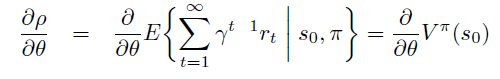
根据定义,\(\rho = V^{\pi}(s_0)\)
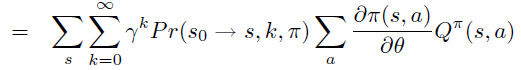
将 \(V^{\pi}(s_0)\) 替换成unroll 成 \(Q^{\pi}\) 的表达式
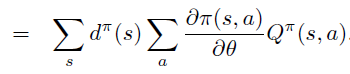
\(\operatorname{Pr}(s \rightarrow x, k, \pi)\) 即 \(d^{\pi}\)

评论
shortnamefor Disqus. Please set it in_config.yml.