上一期 MyEncyclopedia公众号文章 从Q-Learning
演化到
DQN ,我们从原理上讲解了DQN算法,这一期,让我们通过代码来实现任天堂游戏机中经典的超级玛丽的自动通关吧。本文所有代码在
https://github.com/MyEncyclopedia/reinforcement-learning-2nd/tree/master/super_mario。
DQN 算法回顾
上期详细讲解了DQN中的两个重要的技术:Target Network 和 Experience
Replay,正是有了它们才使得 Deep Q
Network在实战中容易收敛,以下是Deepmind 发表在Nature 的 Human-level
control through deep reinforcement learning 的完整算法流程。
超级玛丽 NES OpenAI 环境
安装基于OpenAI gym的超级玛丽环境执行下面的 pip 命令即可。
1 pip install gym-super-mario-bros
我们先来看一下游戏环境的输入和输出。下面代码采用随机的action来和游戏交互。有了
组合游戏系列3: 井字棋、五子棋的OpenAI Gym
GUI环境 对于OpenAI Gym
接口的介绍,现在对于其基本的交互步骤已经不陌生了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import gym_super_mario_brosfrom random import random, randrangefrom gym_super_mario_bros.actions import RIGHT_ONLYfrom nes_py.wrappers import JoypadSpacefrom gym import wrappersenv = gym_super_mario_bros.make('SuperMarioBros-v0' ) env = JoypadSpace(env, RIGHT_ONLY) done = False env.reset() step = 0 while not done: action = randrange(len (RIGHT_ONLY)) state, reward, done, info = env.step(action) print (done, step, info) env.render() step += 1 env.close()
游戏render效果如下
。。。
注意我们在游戏环境初始化的时候用了参数
RIGHT_ONLY,它定义成五种动作的list,表示仅使用右键的一些组合,适用于快速训练来完成Mario第一关。
1 2 3 4 5 6 7 RIGHT_ONLY = [ ['NOOP' ], ['right' ], ['right' , 'A' ], ['right' , 'B' ], ['right' , 'A' , 'B' ], ]
观察一些 info 输出内容,coins表示金币获得数量,flag_get
表示是否取得最后的旗子,time 剩余时间,以及 Mario 大小状态和所在的
x,y位置。
1 2 3 4 5 6 7 8 9 10 11 12 { "coins":0, "flag_get":False, "life":2, "score":0, "stage":1, "status":"small", "time":381, "world":1, "x_pos":594, "y_pos":89 }
游戏图像处理
Deep Reinforcement Learning 一般是 end-to-end learning,意味着游戏的
screen image
作为observation直接视为真实状态,喂给神经网络训练。于此相反的另一种做法是,通过游戏环境拿到内部状态,例如所有相关物品的位置和属性作为模型输入。这两种方式的区别有两点。第一点,用观察到的屏幕像素代替真正的状态
s,在partially observable 的环境时可能因为 non-stationarity
导致无法很好的工作,而拿内部状态利用了额外的作弊信息,在partially
observable环境中也可以工作。第二点,第一种方式屏幕像素维度比较高,输入数据量大,需要神经网络的大量训练拟合,第二种方式,内部真实状态往往维度低得多,训练起来很快,但缺点是因为除了内部状态往往还需要游戏相关规则作为输入,因此generalization能力不如前者强。
这里,我们当然采样屏幕像素的 end-to-end
方式了,自然首要任务是将游戏帧图像有效处理。超级玛丽游戏环境的屏幕输出是
(240, 256, 3) shape的 numpy
array,通过下面一系列的转换,尽可能的在不影响训练效果的情况下减小采样到的数据量。
MaxAndSkipFrameWrapper:每4个frame连在一起,采取同样的动作,降低frame数量。
FrameDownsampleWrapper:将原始的 (240, 256, 3) down sample 到
(84, 84, 1)
ImageToPyTorchWrapper:转换成适合 pytorch 的 (1, 84, 84)
shape
FrameBufferWrapper:保存最后4次屏幕采样
NormalizeFloats:Normalize 成 [0., 1.0] 的浮点值
1 2 3 4 5 6 7 8 9 def wrap_environment (env_name: str , action_space: list ) -> Wrapper: env = make(env_name) env = JoypadSpace(env, action_space) env = MaxAndSkipFrameWrapper(env) env = FrameDownsampleWrapper(env) env = ImageToPyTorchWrapper(env) env = FrameBufferWrapper(env, 4 ) env = NormalizeFloats(env) return env
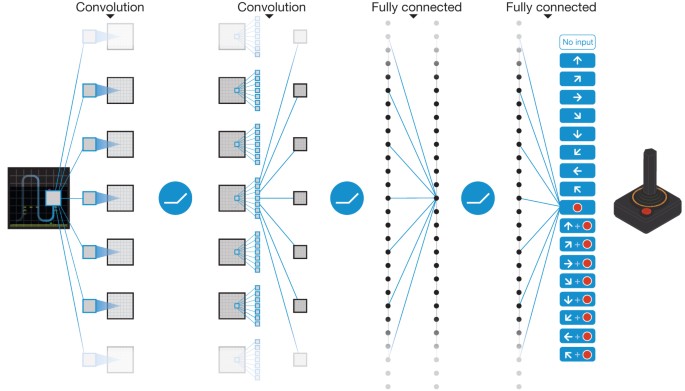
CNN 模型
模型比较简单,三个卷积层后做
softmax输出,输出维度数为离散动作数。act() 采用了epsilon-greedy
模式,即在epsilon小概率时采取随机动作来
explore,大于epsilon时采取估计的最可能动作来 exploit。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 class DQNModel (nn.Module ): def __init__ (self, input_shape, num_actions ): super (DQNModel, self).__init__() self._input_shape = input_shape self._num_actions = num_actions self.features = nn.Sequential( nn.Conv2d(input_shape[0 ], 32 , kernel_size=8 , stride=4 ), nn.ReLU(), nn.Conv2d(32 , 64 , kernel_size=4 , stride=2 ), nn.ReLU(), nn.Conv2d(64 , 64 , kernel_size=3 , stride=1 ), nn.ReLU() ) self.fc = nn.Sequential( nn.Linear(self.feature_size, 512 ), nn.ReLU(), nn.Linear(512 , num_actions) ) def forward (self, x ): x = self.features(x).view(x.size()[0 ], -1 ) return self.fc(x) def act (self, state, epsilon, device ): if random() > epsilon: state = torch.FloatTensor(np.float32(state)).unsqueeze(0 ).to(device) q_value = self.forward(state) action = q_value.max (1 )[1 ].item() else : action = randrange(self._num_actions) return action
Experience Replay 缓存
实现采用了 Pytorch CartPole DQN 的官方代码,本质是一个最大为 capacity
的 list 保存采样的 (s, a, r, s', is_done) 五元组。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Transition = namedtuple('Transition' , ('state' , 'action' , 'reward' , 'next_state' , 'done' )) class ReplayMemory : def __init__ (self, capacity ): self.capacity = capacity self.memory = [] self.position = 0 def push (self, *args ): if len (self.memory) < self.capacity: self.memory.append(None ) self.memory[self.position] = Transition(*args) self.position = (self.position + 1 ) % self.capacity def sample (self, batch_size ): return random.sample(self.memory, batch_size) def __len__ (self ): return len (self.memory)
DQNAgent
我们将 DQN 的逻辑封装在 DQNAgent 类中。DQNAgent 成员变量包括两个
DQNModel,一个ReplayMemory。
train() 方法中会每隔一定时间将 Target Network
的参数同步成现行Network的参数。在td_loss_backprop()方法中采样
ReplayMemory 中的五元组,通过minimize TD error方式来改进现行 Network
参数 \(\theta\) 。Loss函数为:
\[
L\left(\theta_{i}\right)=\mathbb{E}_{\left(s, a, r, s^{\prime}\right)
\sim \mathrm{U}(D)}\left[\left(r+\gamma \max _{a^{\prime}}
Q_{target}\left(s^{\prime}, a^{\prime} ; \theta_{i}^{-}\right)-Q\left(s,
a ; \theta_{i}\right)\right)^{2}\right]
\]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class DQNAgent (): def act (self, state, episode_idx ): self.update_epsilon(episode_idx) action = self.model.act(state, self.epsilon, self.device) return action def process (self, episode_idx, state, action, reward, next_state, done ): self.replay_mem.push(state, action, reward, next_state, done) self.train(episode_idx) def train (self, episode_idx ): if len (self.replay_mem) > self.initial_learning: if episode_idx % self.target_update_frequency == 0 : self.target_model.load_state_dict(self.model.state_dict()) self.optimizer.zero_grad() self.td_loss_backprop() self.optimizer.step() def td_loss_backprop (self ): transitions = self.replay_mem.sample(self.batch_size) batch = Transition(*zip (*transitions)) state = Variable(FloatTensor(np.float32(batch.state))).to(self.device) action = Variable(LongTensor(batch.action)).to(self.device) reward = Variable(FloatTensor(batch.reward)).to(self.device) next_state = Variable(FloatTensor(np.float32(batch.next_state))).to(self.device) done = Variable(FloatTensor(batch.done)).to(self.device) q_values = self.model(state) next_q_values = self.target_net(next_state) q_value = q_values.gather(1 , action.unsqueeze(-1 )).squeeze(-1 ) next_q_value = next_q_values.max (1 )[0 ] expected_q_value = reward + self.gamma * next_q_value * (1 - done) loss = (q_value - expected_q_value.detach()).pow (2 ) loss = loss.mean() loss.backward()
外层 Training 代码
最后是外层调用代码,基本和以前文章一样。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def train (env, args, agent ): for episode_idx in range (args.num_episodes): episode_reward = 0.0 state = env.reset() while True : action = agent.act(state, episode_idx) if args.render: env.render() next_state, reward, done, stats = env.step(action) agent.process(episode_idx, state, action, reward, next_state, done) state = next_state episode_reward += reward if done: print (f'{episode_idx} : {episode_reward} ' ) break


评论
shortnamefor Disqus. Please set it in_config.yml.