上一期 通过代码学Sutton强化学习1:Grid World OpenAI环境和策略评价算法,我们引入了 Grid World 问题,实现了对应的OpenAI Gym 环境,也分析了其最佳策略和对应的V值。这一期中,继续通过这个例子详细讲解策略提升(Policy Improvment)、策略迭代(Policy Iteration)、值迭代(Value Iteration)和异步迭代方法。
回顾 Grid World 问题
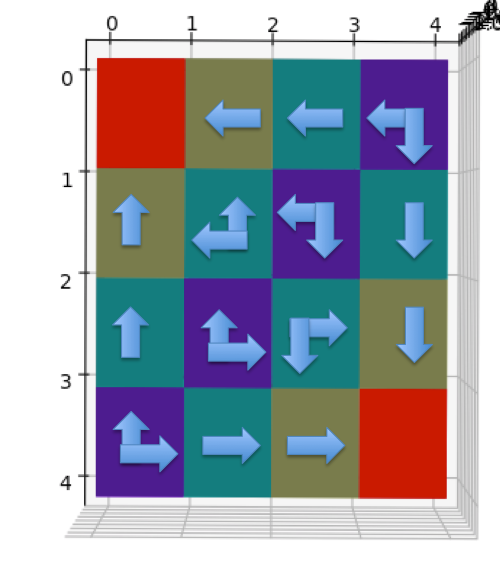
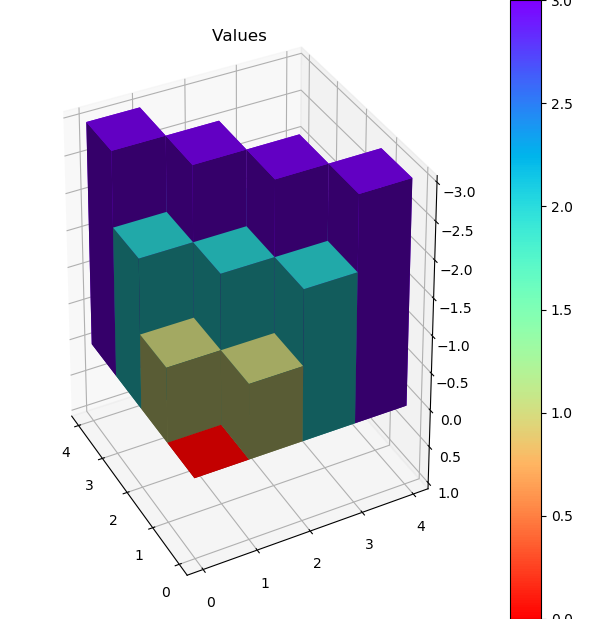
最佳策略对应的状态V值和3D heatmap如下
1 | [[ 0. -1. -2. -3.] |
策略迭代
上一篇中,我们知道如何evaluate 给定policy \(\pi\) 的 \(v_{\pi}\)值,那么是否可能在此基础上改进生成更好的策略 \(\pi^{\prime}\)。如果可以,能否最终找到最佳策略\({\pi}_{*}\)?答案是肯定的,因为存在策略提升定理(Policy Improvement Theorem)。
策略提升定理
在 4.2 节 Policy Improvement Theorem 可以证明,利用 \(v_{\pi}\) 信息对于每个状态采取最 greedy 的 action (又称exploitation)能够保证生成的新 \({\pi}^{\prime}\) 是不差于旧的policy \({\pi}\),即
\[ q_{\pi}(s, {\pi}^{\prime}(s)) \gt v_{\pi}(s) \]
\[ v_{\pi^{\prime}}(s) \gt v_{\pi}(s) \]
\[ \pi_{0} \stackrel{\mathrm{E}}{\longrightarrow} v_{\pi_{0}} \stackrel{\mathrm{I}}{\longrightarrow} \pi_{1} \stackrel{\mathrm{E}}{\longrightarrow} v_{\pi_{1}} \stackrel{\mathrm{I}}{\longrightarrow} \pi_{2} \stackrel{\mathrm{E}}{\longrightarrow} \cdots \stackrel{\mathrm{I}}{\longrightarrow} \pi_{*} \stackrel{\mathrm{E}}{\longrightarrow} v_{*} \]
策略迭代算法
以下为书中4.3的policy iteration伪代码。其中policy evaluation的算法在上一篇中已经实现。Policy improvement 的精髓在于一次遍历所有状态后,通过policy 的最大Q值找到该状态的最佳action,并更新成最新policy,循环直至没有 action 变更。\[ \begin{align*} &\textbf{Policy Iteration (using iterative policy evaluation) for estimating } \pi\approx {\pi}_{*} \\ &1. \quad \text{Initialization} \\ & \quad \quad V(s) \in \mathbb R\text{ and } \pi(s) \in \mathcal A(s) \text{ arbitrarily for all }s \in \mathcal{S} \\ & \\ &2. \quad \text{Policy Evaluation} \\ & \quad \quad \text{Loop:}\\ & \quad \quad \Delta \leftarrow 0\\ & \quad \quad \text{Loop for each } s \in \mathcal{S}:\\ & \quad \quad \quad \quad v \leftarrow V(s) \\ & \quad \quad \quad \quad V(s) \leftarrow \sum_{s^{\prime}, r} p\left(s^{\prime}, r \mid s, a\right)\left[r+\gamma V\left(s^{\prime}\right)\right] \\ & \quad \quad \quad \quad \Delta \leftarrow \max(\Delta, |v-V(s)|) \\ & \quad \quad \text{until } \Delta < \theta \text{ (a small positive number determining the accuracy of estimation)}\\ & \\ &3. \quad \text{Policy Improvement} \\ & \quad \quad policy\text{-}stable\leftarrow true \\ & \quad \quad \text{Loop for each } s \in \mathcal{S}:\\ & \quad \quad \quad \quad old\text{-}action\leftarrow \pi(s) \\ & \quad \quad \quad \quad \pi(s) \leftarrow \operatorname{argmax}_{a} \sum_{s^{\prime}, r} p\left(s^{\prime}, r \mid s, a\right)\left[r+\gamma V\left(s^{\prime}\right)\right] \\ & \quad \quad \quad \quad \text{If } old\text{-}action \neq \pi\text{,then }policy\text{-}stable\leftarrow false \\ & \quad \quad \text{If } policy\text{-}stable \text{, then stop and return }V \approx v_{*} \text{ and } \pi\approx {\pi}_{*}\text{; else go to 2} \end{align*} \]
注意到状态Q值 \(q_{\pi}(s, a)\) 会被多处调用,将其封装为单独的函数。
\[ \begin{aligned} q_{\pi}(s, a) &=\sum_{s^{\prime}, r} p\left(s^{\prime}, r \mid s, a\right)\left[r+\gamma v_{\pi}\left(s^{\prime}\right)\right] \end{aligned} \]
Q值函数实现如下:
1 | def action_value(env: GridWorldEnv, state: State, V: StateValue, gamma=1.0) -> ActionValue: |
有了 action_value 和上期的 policy_evaluate,policy iteration 实现完全对应上面的伪代码。
1 | def policy_improvement(env: GridWorldEnv, policy: Policy, V: StateValue, gamma=1.0) -> bool: |
值迭代
值迭代( Value Iteration)的本质是,将policy iteration中的policy evaluation过程从不断循环到收敛直至小于theta,改成只执行一遍,并直接用最佳Q值更新到状态V值,如此可以不用显示地算出\({\pi}\) 而直接在V值上迭代。具体迭代公式如下:
\[ \begin{aligned} v_{k+1}(s) & \doteq \max _{a} \mathbb{E}\left[R_{t+1}+\gamma v_{k}\left(S_{t+1}\right) \mid S_{t}=s, A_{t}=a\right] \\ &=\max_{a} q_{\pi_k}(s, a) \\ &=\max _{a} \sum_{s^{\prime}, r} p\left(s^{\prime}, r \mid s, a\right)\left[r+\gamma v_{k}\left(s^{\prime}\right)\right] \end{aligned} \]
完整的伪代码为:
\[ \begin{align*} &\textbf{Value Iteration, for estimating } \pi\approx \pi_{*} \\ & \text{Algorithm parameter: a small threshold } \theta > 0 \text{ determining accuracy of estimation} \\ & \text{Initialize } V(s), \text{for all } s \in \mathcal{S}^{+} \text{, arbitrarily except that } V (terminal) = 0\\ & \\ &1: \text{Loop:}\\ &2: \quad \quad \Delta \leftarrow 0\\ &3: \quad \quad \text{Loop for each } s \in \mathcal{S}:\\ &4: \quad \quad \quad \quad v \leftarrow V(s) \\ &5: \quad \quad \quad \quad V(s) \leftarrow \operatorname{max}_{a} \sum_{s^{\prime}, r} p\left(s^{\prime}, r \mid s, a\right)\left[r+\gamma V\left(s^{\prime}\right)\right] \\ &6: \quad \quad \quad \quad \Delta \leftarrow \max(\Delta, |v-V(s)|) \\ &7: \text{until } \Delta < \theta \\ & \\ & \text{Output a deterministic policy, }\pi\approx \pi_{*} \text{, such that} \\ & \quad \quad \pi(s) \leftarrow \operatorname{argmax}_{a} \sum_{s^{\prime}, r} p\left(s^{\prime}, r \mid s, a\right)\left[r+\gamma V\left(s^{\prime}\right)\right] \end{align*} \]
代码实现也比较直接,可以复用上面已经实现的 action_value 函数。
1 | def value_iteration(env:GridWorldEnv, gamma=1.0, theta=0.0001) -> Tuple[Policy, StateValue]: |
异步迭代
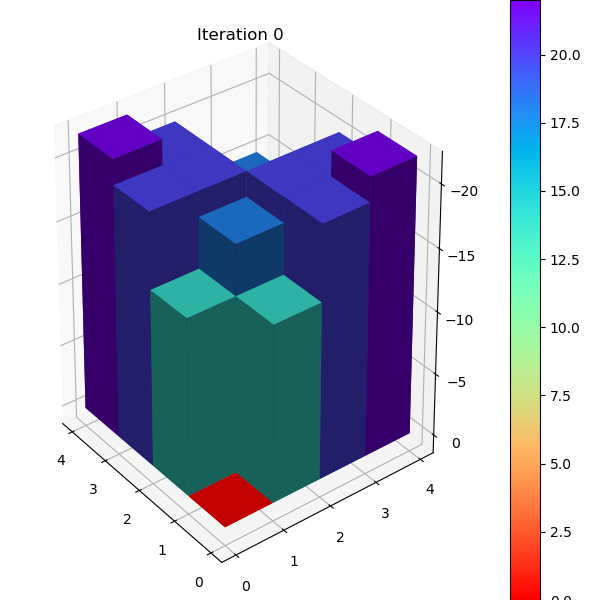
在第4.5节中提到了DP迭代方式的改进版:异步方式迭代(Asychronous Iteration)。这里的异步是指每一轮无需全部扫一遍所有状态,而是根据上一轮变化的状态决定下一轮需要最多计算的状态数,类似于Dijkstra最短路径算法中用 heap 来维护更新节点集合,减少运算量。下面我们通过异步值迭代来演示异步迭代的工作方式。
下图表示状态的变化方向,若上一轮 \(V(s)\) 发生更新,那么下一轮就要考虑状态 s 可能会影响到上游状态的集合( p1,p2),避免下一轮必须遍历所有状态的V值计算。
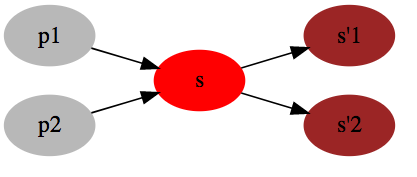
要做到部分更新就必须知道每个状态可能影响到的上游状态集合,上图对应的映射关系可以表示为
\[ \begin{align*} s'_1 &\rightarrow \{s\} \\ s'_2 &\rightarrow \{s\} \\ s &\rightarrow \{p_1, p_2\} \end{align*} \]
建立映射关系的代码如下,build_reverse_mapping 返回类型为 Dict[State, Set[State]]。
1 | def build_reverse_mapping(env:GridWorldEnv) -> Dict[State, Set[State]]: |
有了描述状态依赖的映射 dict 后,代码也比较简洁,changed_state_set 变量保存了这轮必须计算的状态集合。新的一轮迭代时,将下一轮需要计算的状态保存到 changed_state_set_ 中,本轮结束后,changed_state_set 更新成changed_state_set_,开始下一轮循环直至没有状态需要更新。
1 | def value_iteration_async(env:GridWorldEnv, gamma=1.0, theta=0.0001) -> Tuple[Policy, StateValue]: |

评论
shortnamefor Disqus. Please set it in_config.yml.