from sentence_transformers import SentenceTransformer model = SentenceTransformer('paraphrase-MiniLM-L6-v2')
#Our sentences we like to encode sentences = ['This framework generates embeddings for each input sentence', 'Sentences are passed as a list of string.', 'The quick brown fox jumps over the lazy dog.']
#Sentences are encoded by calling model.encode() embeddings = model.encode(sentences)
#Print the embeddings for sentence, embedding inzip(sentences, embeddings): print("Sentence:", sentence) print("Embedding:", embedding) print("")
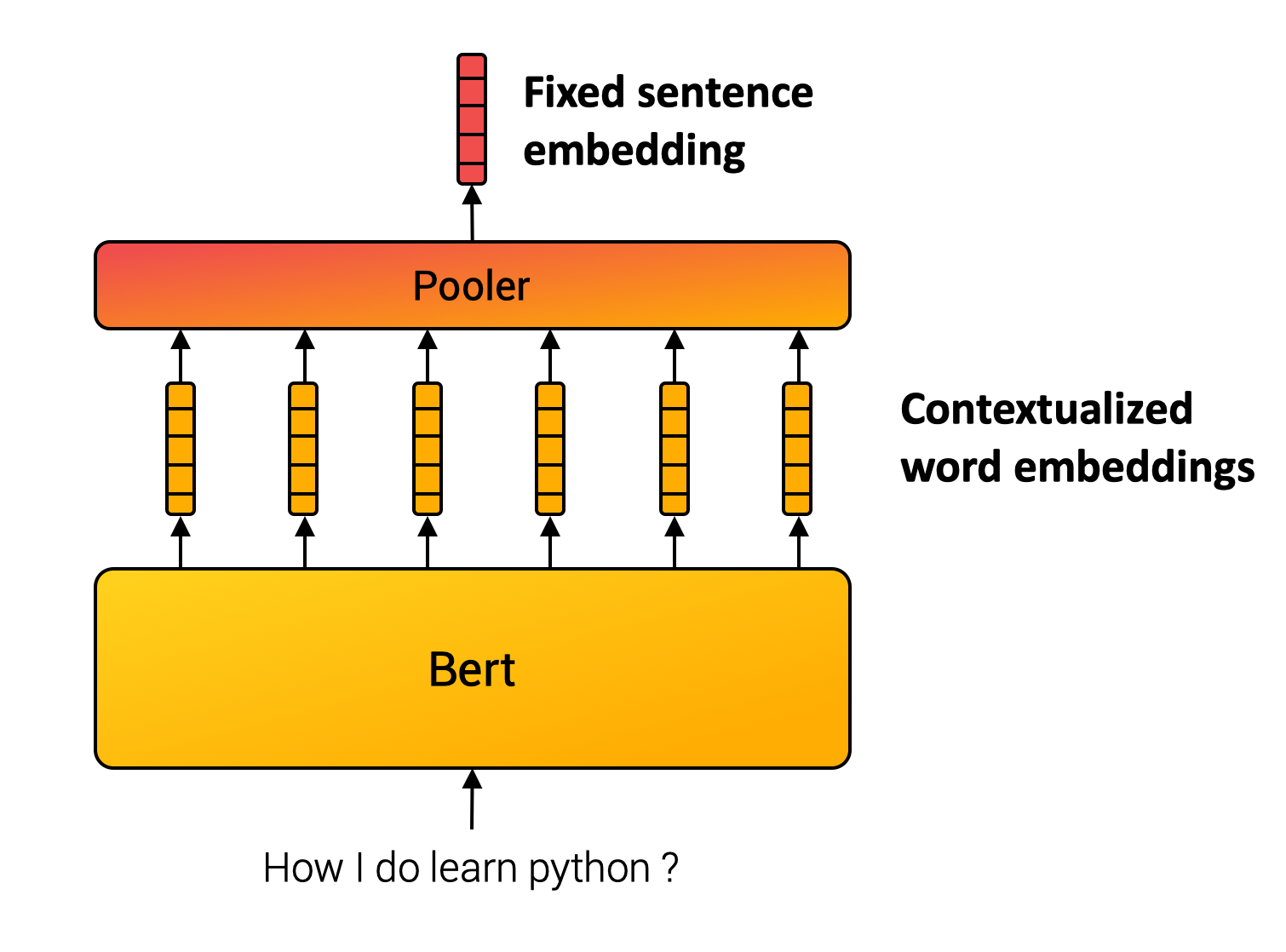
当然,我们也可以绕过 sentence-transformer API,直接使用
pytorch API 和 huggingface
手动实现平均池化层,生成句子的 sentence embedding。
from transformers import AutoTokenizer, AutoModel import torch
#Mean Pooling - Take attention mask into account for correct averaging defmean_pooling(model_output, attention_mask): token_embeddings = model_output[0] #First element of model_output contains all token embeddings input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float() sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1) sum_mask = torch.clamp(input_mask_expanded.sum(1), min=1e-9) return sum_embeddings / sum_mask
#Sentences we want sentence embeddings for sentences = ['This framework generates embeddings for each input sentence', 'Sentences are passed as a list of string.', 'The quick brown fox jumps over the lazy dog.']
#Load AutoModel from huggingface model repository tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2") model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
Top 3 most similar sentences in corpus: 人工智能需要懂很多数学么 (Cosine Score: 0.7606) MyEncyclopedia公众号全栈人工智能 (Cosine Score: 0.7498) 上海疫情有完没完 (Cosine Score: 0.7449)
Top 3 most similar sentences in corpus: 俄方称已准备好重启俄乌和谈 (Cosine Score: 0.7041) MyEncyclopedia公众号全栈人工智能 (Cosine Score: 0.6897) 上海疫情有完没完 (Cosine Score: 0.6888)

评论
shortnamefor Disqus. Please set it in_config.yml.